피벗
개요
분석 > 피벗 메뉴에서는 피벗 테이블을 이용해 데이터를 시각적으로 분석할 수 있습니다. 로그프레소 소나가 수집하는 데이터는 대부분 시간순으로 발생한 이벤트(로그) 정보이며, 피벗 기능을 통해 이 데이터에서 필요한 항목만 추출한 뒤 행과 열을 원하는 형태로 재구성할 수 있습니다. 이를 통해 항목 간의 관계를 파악하거나 집계를 수행하고, 다른 데이터와의 연관 분석을 통해 의미 있는 인사이트를 도출할 수 있습니다. 피벗 기능을 사용하면 복잡한 쿼리를 작성하지 않아도 고차원 분석을 손쉽게 수행할 수 있습니다.
화면 구성
데이터 적재 전
분석 > 피벗 메뉴에 처음 진입하면 다음과 같이 빈 작업 패널 화면이 표시됩니다.
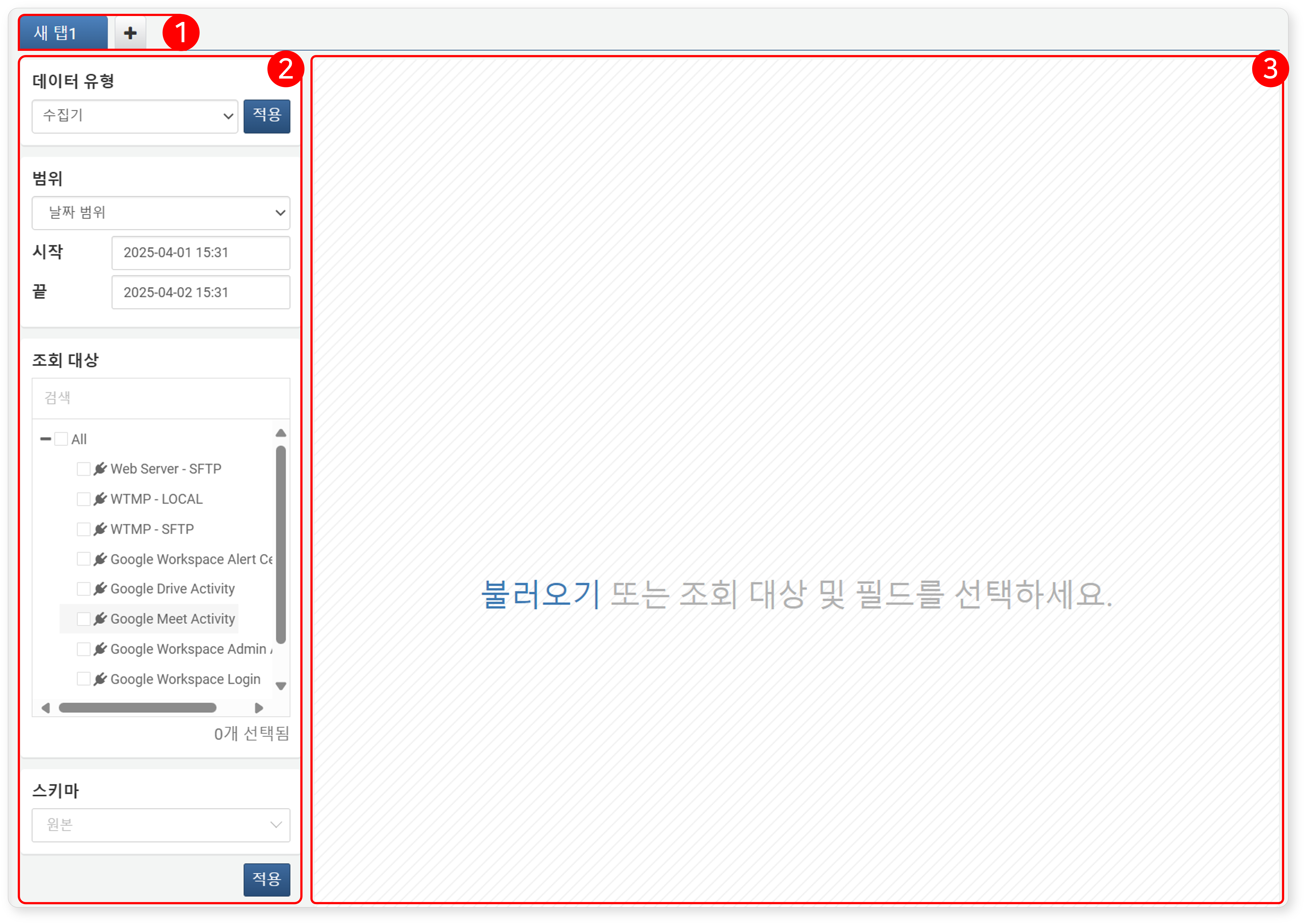
- 1. 탭
- 피벗 작업은 각 탭에서 진행됩니다. 새 탭을 열어 여러 개의 피벗 작업을 동시에 수행할 수 있습니다.
- 2. 데이터 적재 설정
-
조회 대상(수집기, 테이블, 데이터셋, 행위 프로파일, 이벤트)의 데이터를 불러오기 위한 조건을 설정하는 영역입니다.
-
데이터 유형을 선택한 뒤 분석 대상 기간, 조회 필드 및 대상, 데이터 유형에 따라 로그 스키마를 지정할 수 있습니다. 조건 설정 후 하단의 적용 버튼을 클릭하면 작업 공간에 데이터가 적재됩니다.
- 3. 작업 공간
-
설정한 조건에 따라 적재된 데이터가 표시되는 영역입니다.
데이터 적재 후
데이터가 적재되면 화면 구성은 다음과 같이 변경됩니다. 1~3은 작업 패널, 4는 작업 공간입니다.
- 1. 탭
- 데이터를 불러오면 탭 이름에 해당 조회 대상이 표시됩니다. 직접 쿼리를 입력해 데이터를 적재한 경우는 예외입니다.

- 탭 이름 오른쪽에 커서를 올리면 ∨ 아이콘이 나타나며, 클릭 시 팝업 메뉴에서 탭 이름을 변경하거나 탭을 닫을 수 있습니다.
- 2. 피벗 설정
- 분석을 위한 설정 도구가 표시됩니다. 입력 필터, 결과 필터, 값, 행, 열, 필드 도구를 통해 원하는 분석 조건을 구성할 수 있습니다.
- 3. 도구 모음
- 데이터를 그리드 또는 차트 형태의 대시보드 위젯으로 변환할 수 있는 기능을 제공합니다. 이외에도 데이터셋 저장, 쿼리 결과 저장, 피벗 결과 다운로드, 피벗 내보내기 등 다양한 변환 도구가 제공됩니다.tline68) 등 다양한 변환 도구가 제공됩니다.
- 4. 작업 공간
- 분석 대상 데이터가 시각적으로 표시되는 영역입니다.
작업 순서
다음 그림은 피벗을 활용한 데이터 분석 과정을 도식화한 것입니다.
- 1 단계: 데이터 적재
-
데이터 유형은 가져올 데이터 원천의 유형으로 보는 것이 더 적절합니다. 데이터 유형, 데이터 범위, 조회 대상, 스키마, 필드 등을 선택해 데이터를 가져올 수 있습니다. 그 외에 쿼리를 직접 입력해서 데이터를 가져오는 저수준의 접근 방식을 이용하거나, 외부로 내보낸 피벗 파일을 다시 불러올 수도 있습니다.
-
데이터 유형별 데이터 적재 방법은 데이터 적재를 참고하세요.
- 2 단계: 데이터 가공
-
1단계에서 데이터를 적재하면, 작업 패널은 본격적인 피벗 작업을 위한 도구 모음으로 전환되고, 작업 공간에 데이터가 출력됩니다.
-
이 데이터를 분석에 적합한 형태로 가공해야 합니다. 가공은 크게 전처리, 후처리로 나뉩니다. 2단계에서 수행하는 가공은 전처리를 의미합니다. 전처리는 조건에 따라 데이터를 재배열하거나 정렬하는 작업입니다.
-
전처리 방법에 대한 자세한 설명은 데이터 가공를 참고하세요.
-
후처리는 3 단계 데이터 분석 작업의 일부로써 이뤄집니다.
- 3 단계: 데이터 분석
-
이 단계에서는 행/열 필드와 값 필드를 정의해 항목 간 관계를 요약하거나 데이터를 집계할 수 있으며, 필요한 경우 다른 데이터와의 연관 분석도 수행할 수 있습니다. 또한, 데이터 분석 단계에서는 필터를 사용해 후처리도 함께 수행할 수 있습니다.
-
2단계(전처리)와 3단계(분석)는 논리적으로 나눠 설명되지만, 실제 작업에서는 동시에 진행됩니다.
- 4 단계: 분석 결과 활용
다음부터는 각 단계에서 수행할 수 있는 작업을 구체적으로 설명합니다.
데이터 적재
데이터 유형, 범위, 조회 대상, 스키마, 필드 등 데이터를 가져올 조건을 지정하고 하단의 적용 버튼을 클릭하세요. 지정한 조건에 따라 작업 공간에 데이터가 표시됩니다. 기본적으로 최대 10,000개의 데이터가 적재되며, 이 개수는 결과 필터 설정을 통해 변경할 수 있습니다.
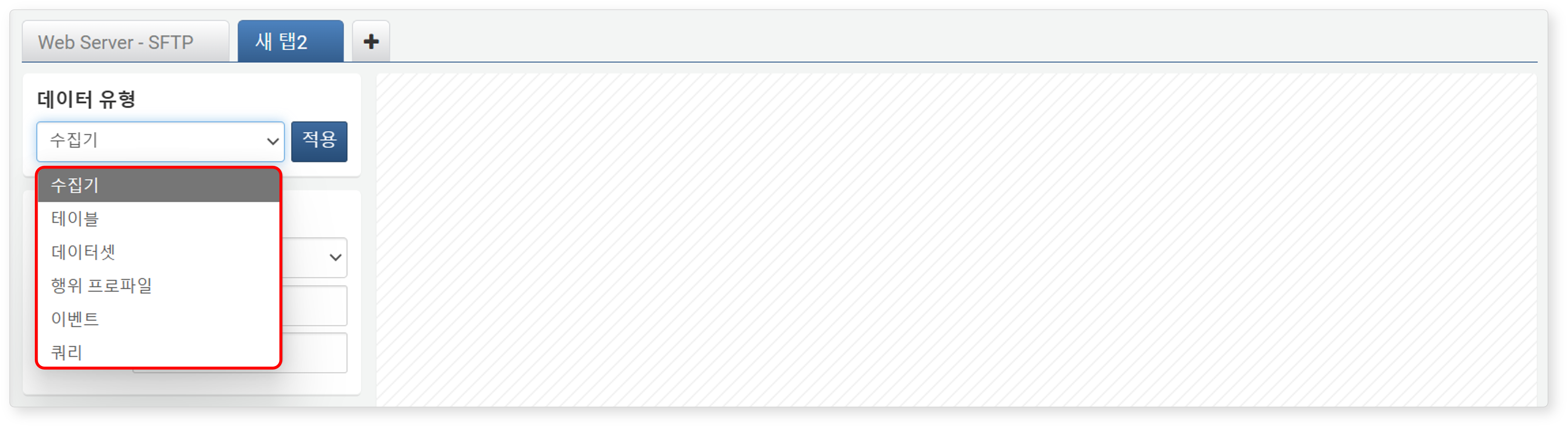
데이터 유형
데이터 원천의 유형을 선택하세요(기본값: 수집기). 선택한 유형에 해당하는 조회 대상 목록이 보여집니다.
- 수집기: 선택한 수집기에 연결된 테이블에서 데이터를 가져옵니다. 하나의 테이블을 여러 수집기가 공유하는 경우에는 선택한 수집기를 통해 수집된 데이터만 가져옵니다.
- 테이블: 선택한 테이블에 저장된 데이터를 가져옵니다.
- 데이터셋: 선택한 데이터셋을 기반으로 쿼리를 실행하여 데이터를 가져옵니다.데이터셋은 검색 기간이 고정된 쿼리를 실행하여 결과를 반환하므로, 범위 조건은 설정할 수 없습니다.
- 행위 프로파일: 선택한 행위 프로파일에서 최근 빌드된 데이터를 가져옵니다. 행위 프로파일은 연관 분석에 활용할 수 있으며, 보안 이상 탐지에 효과적입니다.
- 이벤트: 실시간 또는 배치 탐지 시나리오에 의해 생성된 이벤트 데이터를 가져옵니다.
- 쿼리: 쿼리 항목에 직접 작성한 쿼리를 실행하여 데이터를 가져옵니다. 사전 정의된 유형 외의 데이터를 조회하려면 데이터 유형으로 쿼리를 선택하세요.
- 수집기: 외부 원천에서 특정 수집기를 통해 들어온 데이터를 조회하려는 경우
- 테이블: 여러 수집기가 데이터를 저장하는 테이블, 또는 시스템 테이블 데이터를 조회하려는 경우
테이블 목록은 'system tables' 쿼리를 실행하여 확인할 수 있습니다.
범위
범위는 데이터가 발생한 기간 조건을 설정하는 항목입니다. 단, 데이터 유형이 데이터셋 또는 쿼리인 경우에는 기간 조건을 지정할 수 없습니다. 지정된 기간 조건은 _time 필드를 기준으로 적용됩니다.
기본값은 현재 시각 기준 과거 24시간입니다. 데이터 유형이 행위 프로파일인 경우에는 기본값이 전체 기간으로 설정됩니다.
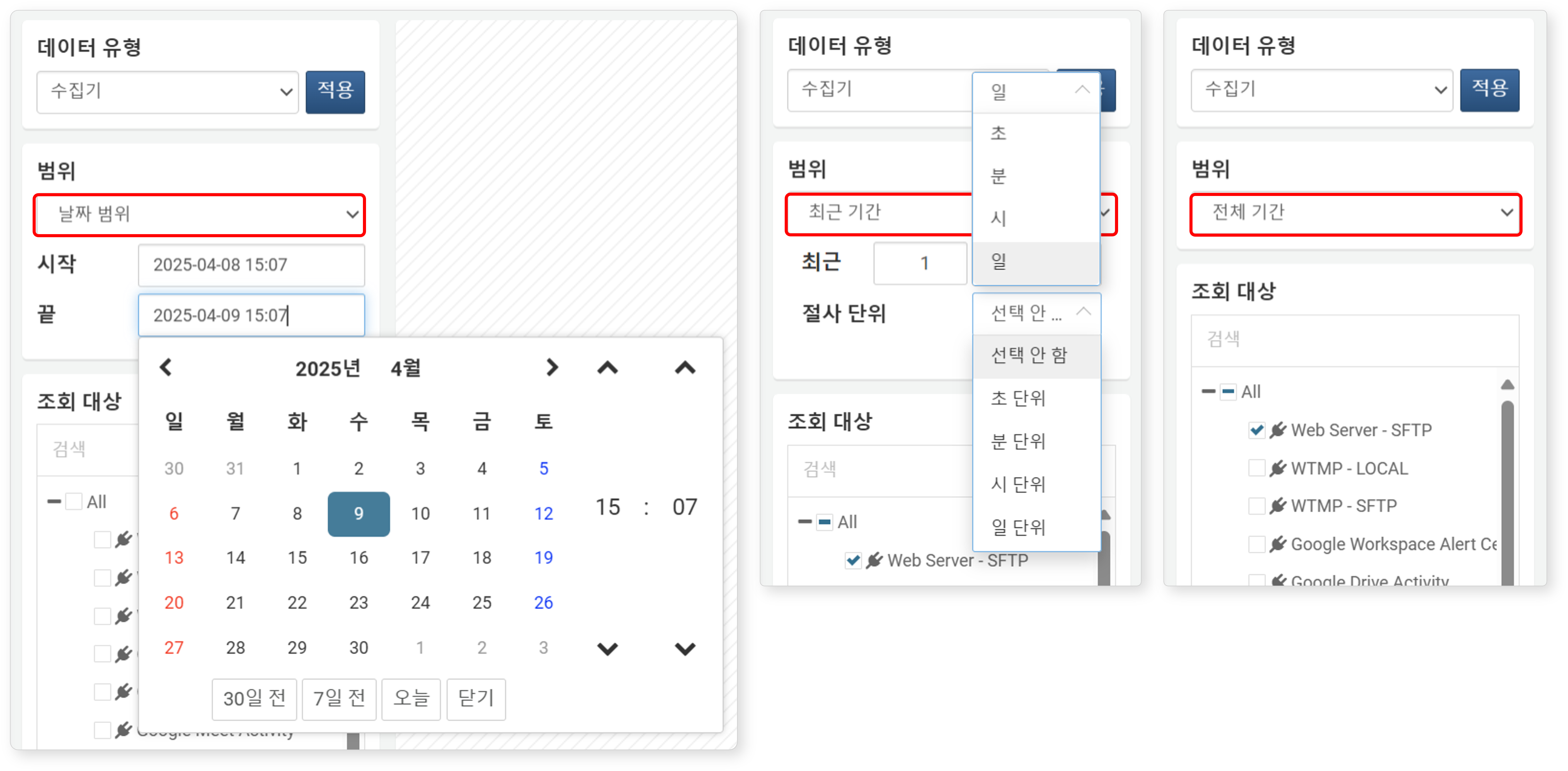
- 날짜 범위: 시작(
from)과 끝(to)으로 지정된 시간 동안 수집된 데이터를 조회합니다. 기본값은 현재 시각 기준 과거 24시간이며, 끝 시각은 조회 범위에 포함되지 않습니다. - 최근 기간: 지정한 최근(
from) 시점부터 현재까지의 데이터를 조회합니다(기본값: 1일).- 절사 단위:단위(초, 분, 시, 일)를 선택하면 _time 필드 값을 해당 단위로 절사합니다(기본값: 선택 안 함). 이는datetrunc() 함수를 적용한 것과 동일한 결과를 생성합니다.
- 전체 기간: 선택한 조회 대상에 기록된 모든 데이터를 조회합니다.
조회 대상
데이터 유형을 선택하면, 해당 유형에 맞는 데이터 원천 목록이 표시됩니다. 목록에서 조회할 대상을 하나 이상 선택하세요. 아래 그림은 데이터 유형별 조회 대상 목록의 예시입니다.
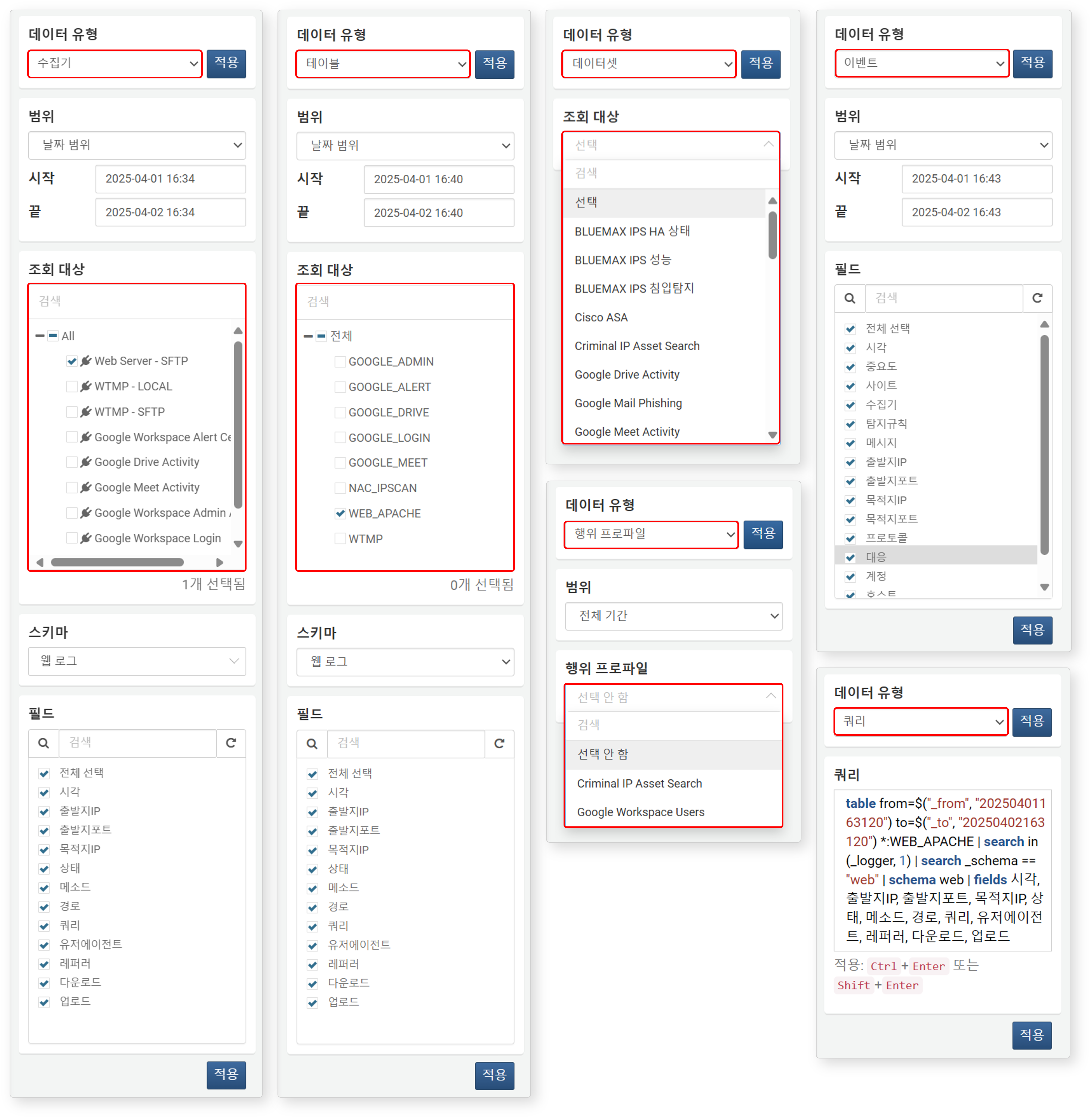
- 데이터 유형이 행위 프로파일인 경우, 조회 대상 목록은 행위 프로파일 목록으로 표시됩니다.
- 데이터 유형이 이벤트 또는 쿼리인 경우에는 조회 대상을 선택할 수 없습니다.
서로 다른 스키마가 필요한 데이터는 새 탭에서 각각 적재한 뒤, 연관 분석 기능을 활용해 비교 분석해보세요.
스키마
데이터 유형이 수집기 또는 테이블인 경우에 스키마를 지정할 수 있습니다. 스키마를 지정하면, 데이터의 원본 필드를 스키마에 정의된 필드 이름으로 정규화하여 데이터를 불러옵니다. 이때 스키마에 정의되지 않은 원본 필드는 가져오지 않습니다.
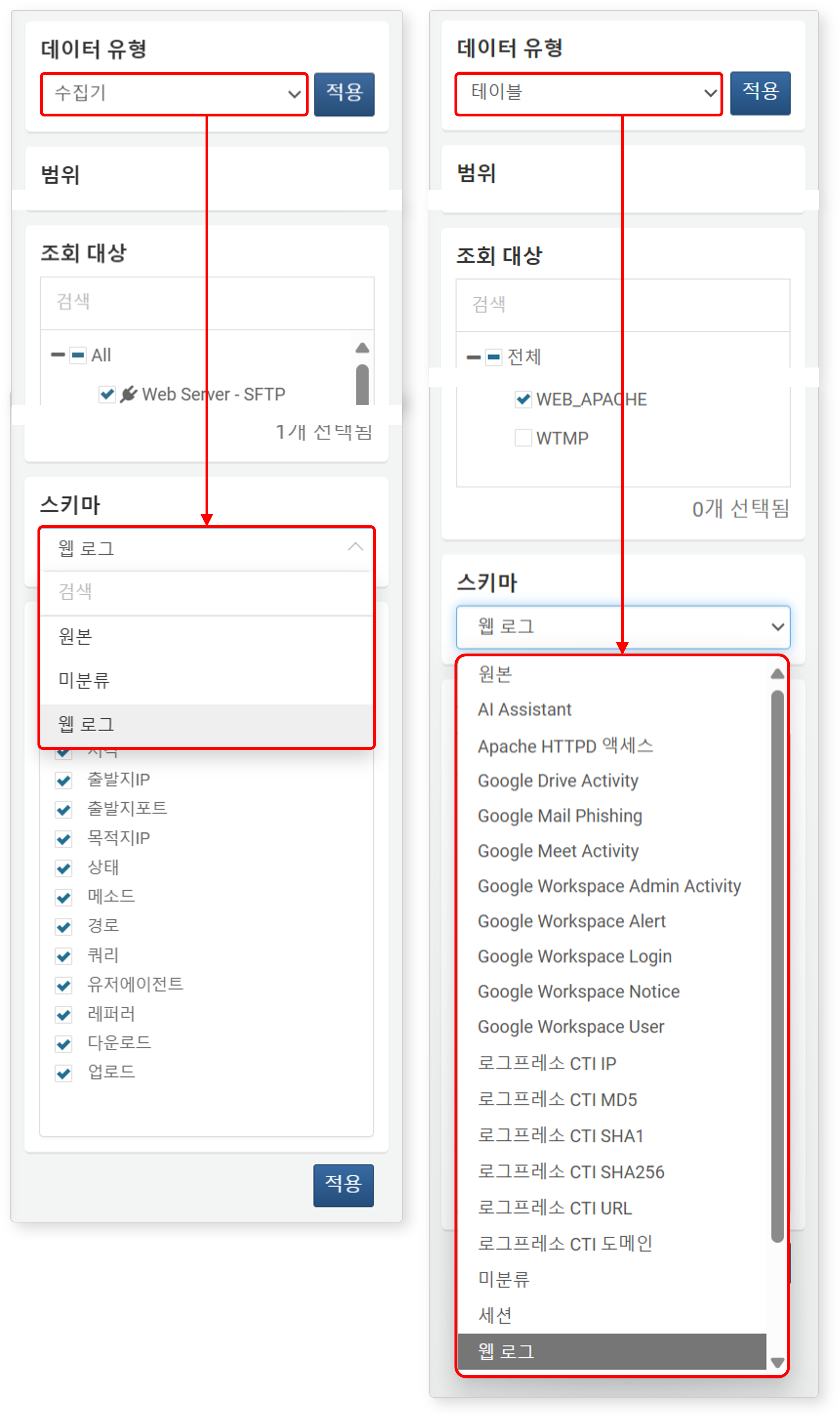
- 데이터 유형이 수집기인 경우, 수집기가 참조하는 수집 모델에 정의된 정규화 규칙의 로그 스키마와 원본, 미분류 중에서 선택할 수 있습니다.
- 미분류: 수집 모델의 정규화 규칙이 적용되지 않은 미분류 데이터
- 원본: 정규화되지 않은 원본 필드
- 데이터 유형이 테이블인 경우, 테이블에 연결된 스키마 정보가 별도로 없으므로 모든 로그 스키마(원본, 미분류 포함) 중에서 선택할 수 있습니다.
- 테이블에 데이터를 기록할 때 어떤 로그 스키마를 적용했는지 확인한 뒤, 그에 맞는 로그 스키마를 선택하세요.
- 엡 스키마(예: Apache HTTPD 액세스 로그 스키마)는 기본 제공되는 스키마보다 확장된 필드를 제공합니다.
필드
데이터 유형이 수집기, 테이블, 이벤트 중 하나인 경우, 사용자가 선택한 스키마에 따라 정규화된 필드 목록이 표시됩니다.
- 스키마에서 원본을 선택한 경우, 데이터를 정규화하지 않음으로 필드 목록은 제동되지 않습니다.
- 데이터 유형이 이벤트인 경우, 스키마를 선택하지 않아도 이벤트에 정의된 정규화 필드 목록이 자동으로 표시됩니다.
- 필드 목록에서 불필요한 항목은 선택을 해제해 결과에 포함하지 않도록 설정할 수 있습니다.
쿼리
데이터 유형으로 쿼리를 선택하면 쿼리문 입력 상자가 나타납니다.
다음 그림은 동일한 데이터를 수집기 기반과 쿼리 기반으로 가져온 화면을 비교한 예시입니다. 좌측은 데이터 유형을 수집기로 설정한 화면이며, 우측은 쿼리로 선택한 뒤 직접 쿼리를 입력한 화면입니다.
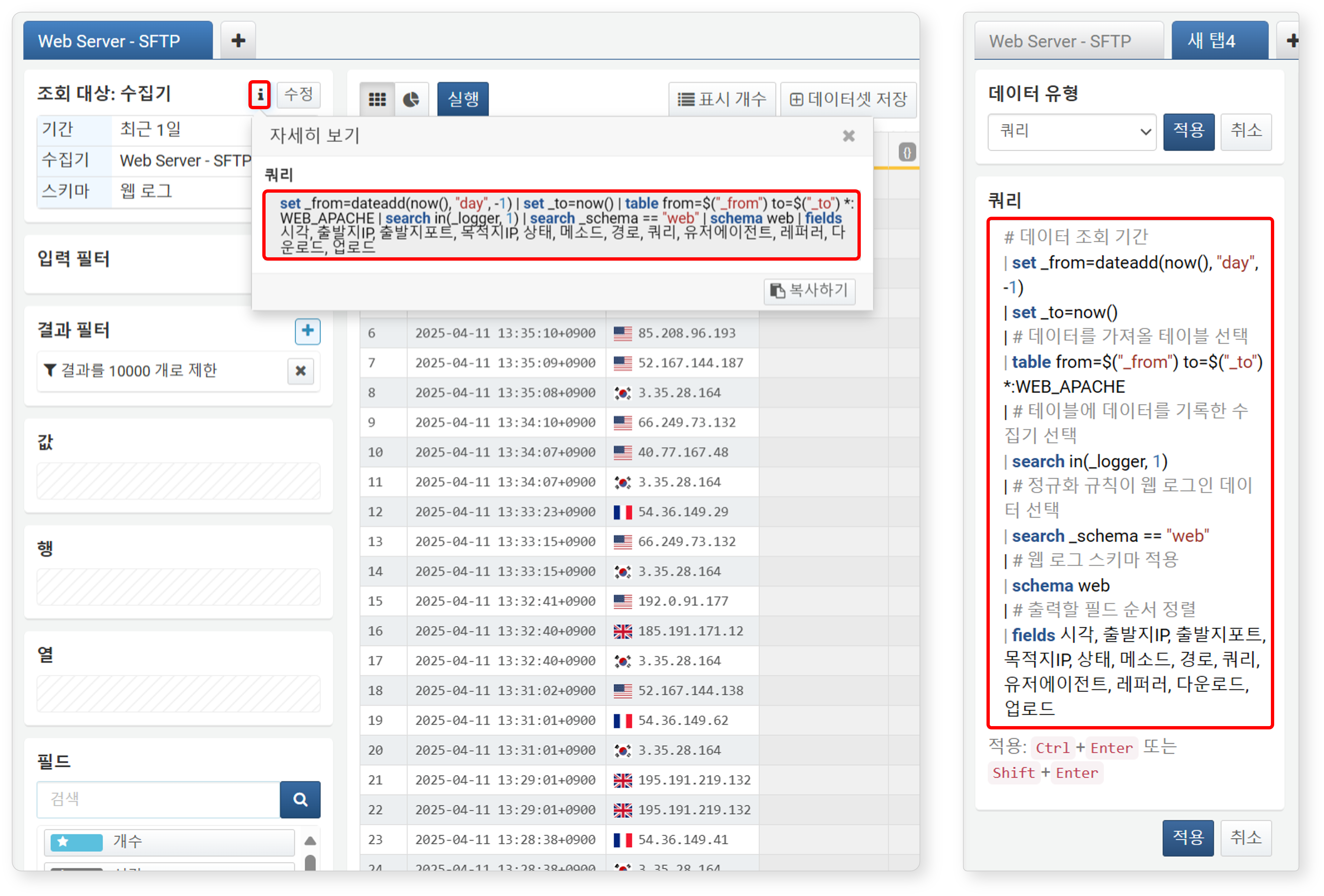
-
 버튼을 클릭하면 데이터를 가져올 때 적용된 쿼리문을 확인할 수 있습니다. 수집기 기반과 쿼리 기반 설정은 동일한 결과를 제공합니다.
버튼을 클릭하면 데이터를 가져올 때 적용된 쿼리문을 확인할 수 있습니다. 수집기 기반과 쿼리 기반 설정은 동일한 결과를 제공합니다. -
아래는 쿼리 기반 설정에 사용된 예시 쿼리입니다:
# 데이터 조회 기간 설정 | set _from=dateadd(now(), "day", -1) | set _to=now() | # 대상 테이븡에서 데이터 조회 | table from=$("_from") to=$("_to") *:WEB_APACHE | # 특정 수집기에서 수집된 데이터만 조회 | search in(_logger, 1) | # 스키마가 "web"인 데이터만 필터링 | search _schema == "web" | # 웹 로그 스키마 적용 | schema web | # 출력할 필드 순서 정의 | fields 시각, 출발지IP, 출발지포트, 목적지IP, 상태, 메소드, 경로, 쿼리, 유저에이전트, 레퍼러, 다운로드, 업로드
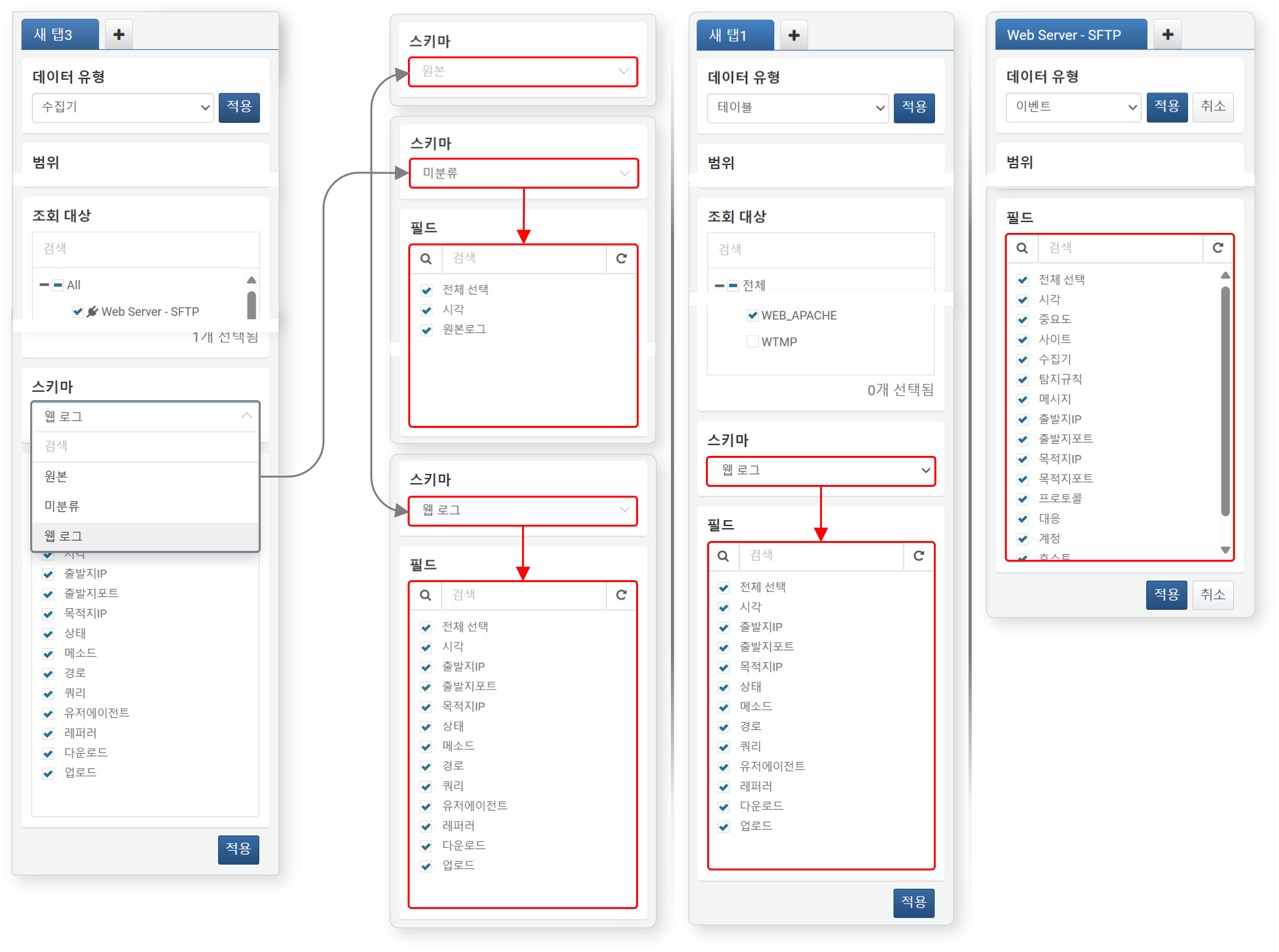
적재
적용 버튼을 클릭하면, 설정한 데이터 유형, 범위, 조회 대상, 스키마, 필드 조건에 따라 데이터가 작업 공간에 적재됩니다. 이후 작업 패널은 데이터 가공 및 피벗 분석에 적합한 인터페이스로 자동 전환됩니다.
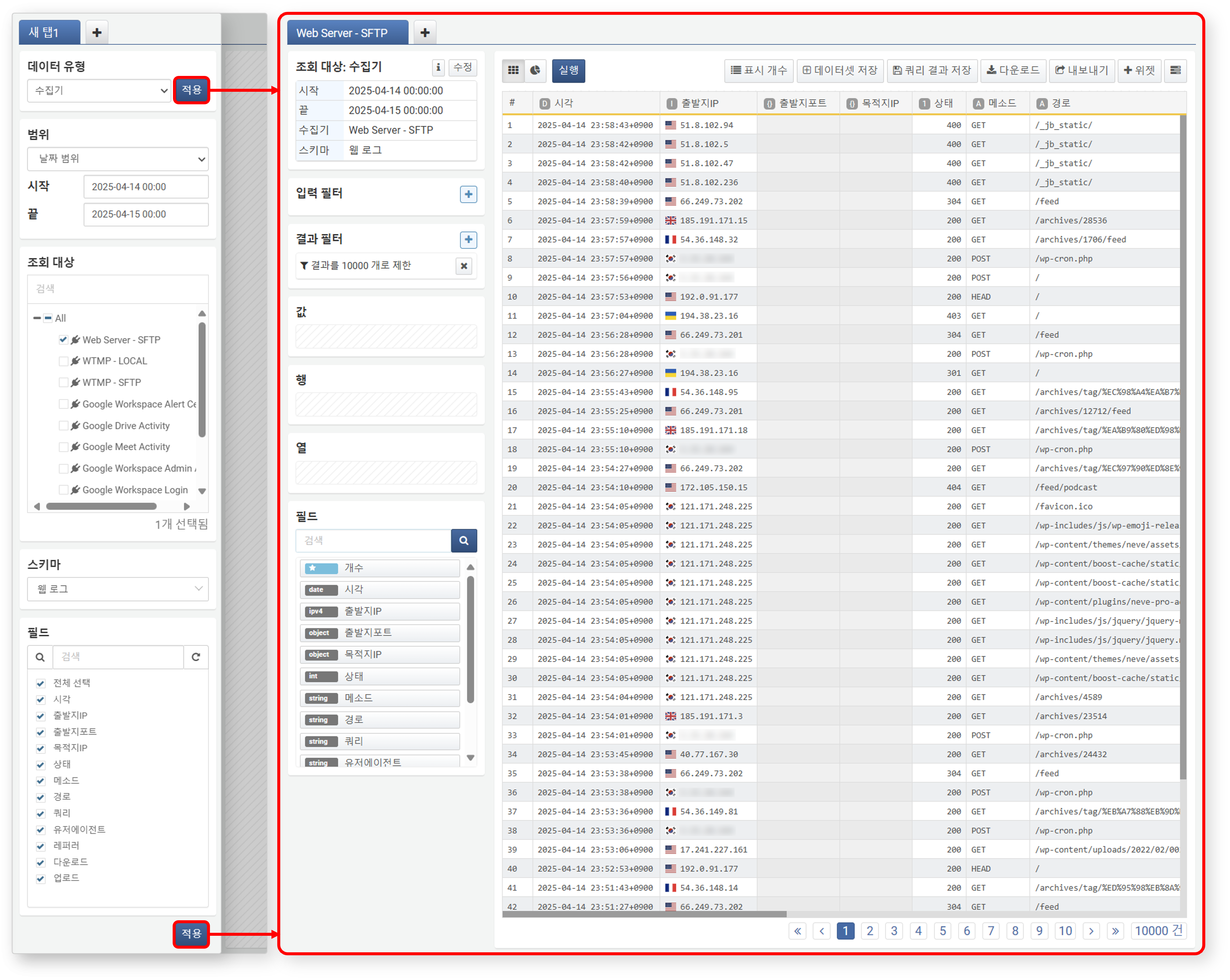
재적재
데이터를 다른 조건으로 다시 가져오려면, 작업 패널에서 조회 대상 우측의 수정 버버튼을 클릭하세요. 조건을 변경한 후 적용 버튼을 다시 클릭해야 새로운 조건이 반영됩니다.

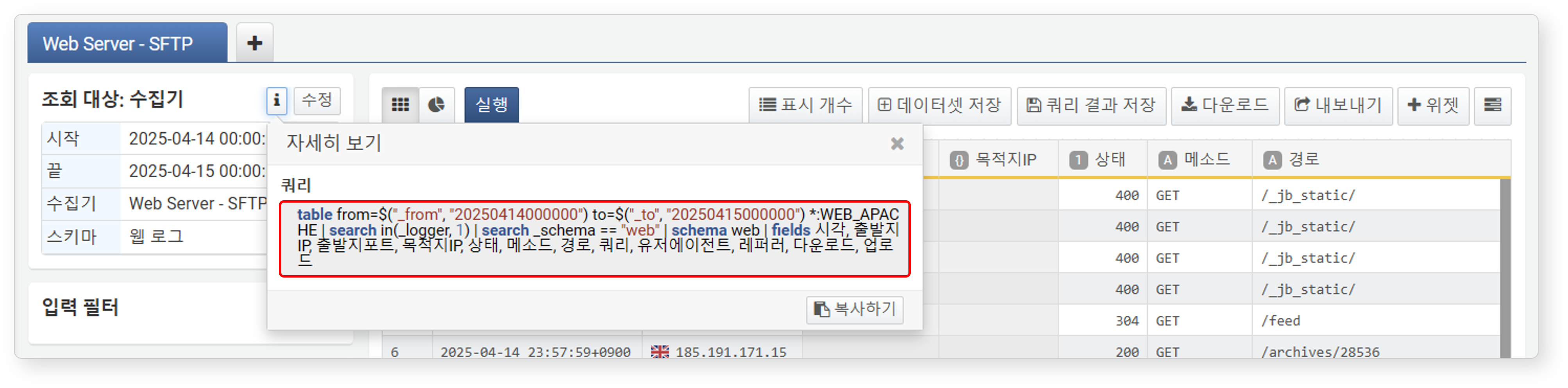
쿼리문 보기
조회 대상 우축의 클릭하면, 데이터를 가져올 때 사용된 쿼리문을 확인할 수 있습니다. 복사하기 버튼을 누르면 해당 쿼리문이 클립보드에 복사됩니다.
데이터 가공
데이터가 작업 공간에 적재되면, 이를 집계 또는 분석에 적합한 형태로 가공해 활용할 수 있습니다. 불필요한 데이터를 제거하고, 분석 대상 기간에 맞춰 시간 단위를 절사한 뒤 필요한 항목만 선별해 정렬하면 피벗 분석의 효율이 높아집니다.
로그프레소 소나는 세 가지 데이터 가공 기능을 제공합니다:
- 필터: 특정 조건에 일치하는 데이터만 가져오거나, 피벗을 통해 가공된 데이터 중에서 특정 조건에 맞는 데이터만 선별
- 수식: 날짜 데이터를 시간 단위로 절사하거나, 시간차 계산, 문자열 처리 등 다양한 변환 수식을 적용
- 정렬: 열의 순서 변경, 열 숨김, 오름차순/내림차순 정렬, 상/하위 N개 정렬 등 데이터의 재배치 및 표시 형식 조정
실행 방법
- 필드 목록에서 필드를 클릭
- 데이터 적재 설정 영역의 필드 목록에서 필드를 클릭하면, 해당 필드에 대해 필터, 수식, 정렬 기능을 적용할 수 있습니다.
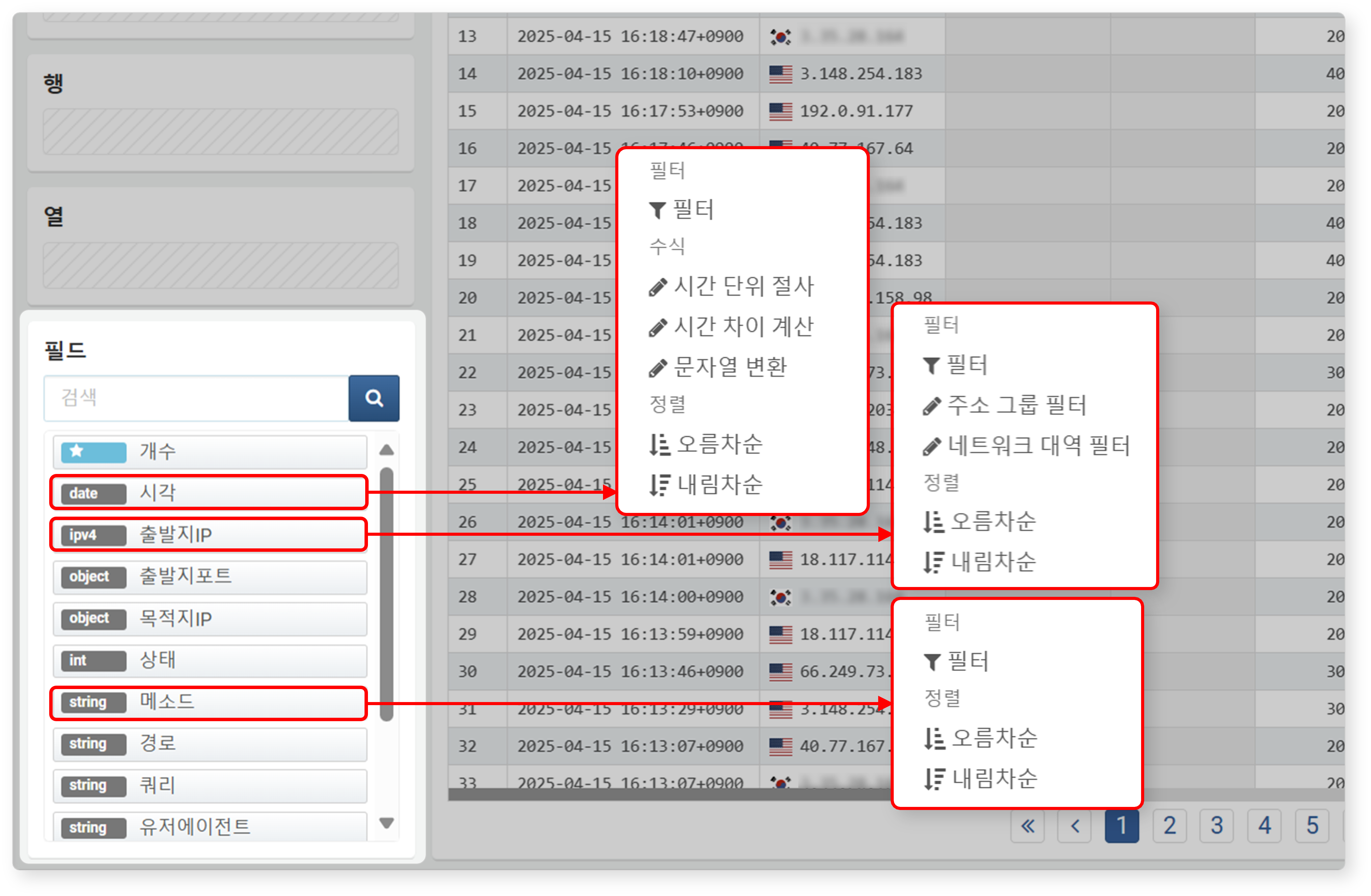
- 선택한 필드에 해당하는 데이터 열을 기준으로 필터, 수식, 정렬 기능이 적용됩니다.
- 각 필드 왼쪽에는 해당 필드의 데이터 유형이 표시됩니다.
- 적용 가능한 필터는 데이터 유형에 따라 달라집니다.
- 열 이름을 보조 클릭
- 작업 공간에서 데이터 열 이름(필드)을 보조 클릭(일반적으로 마우스 오른쪽 클릭)하면 열 이동, 정렬, 상위/하위 N개 선택 등의 기능을 사용할 수 있습니다.
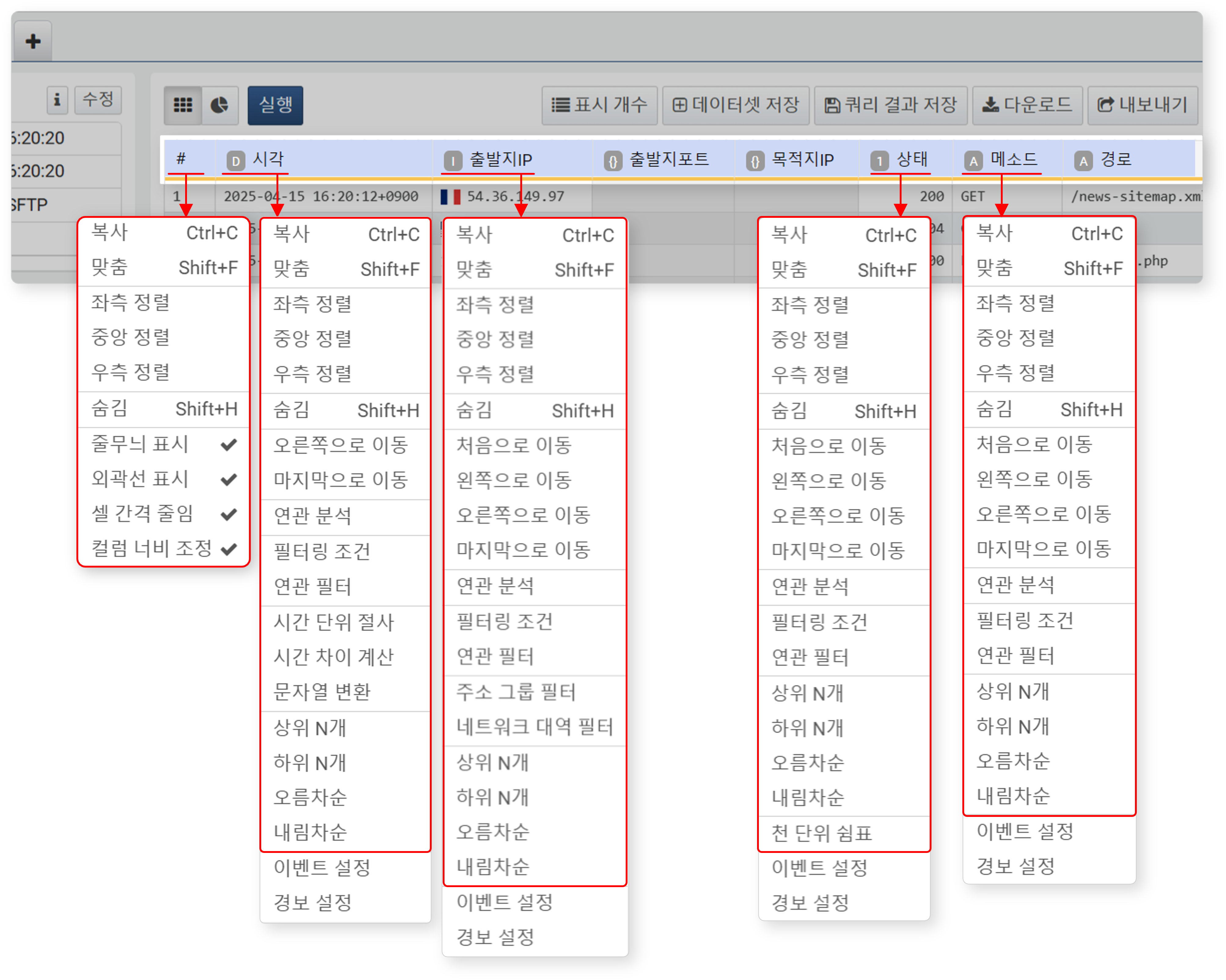
- 필드 목록에서는 설정할 수 없었던 열 위치 변경과 정렬 방식(오름차순/내림차순 등)을 지정할 수 있습니다.
- 필드 숨김/표시 기능을 사용할 수 있으며, 숨겨진 열이 있는 경우 굵은 실선으로 표시됩니다.
- #(행 번호)를 보조 클릭하면 전체 행을 선택하거나, 데이터 그리드 스타일을 변경할 수 있습니다.
- 두 개 이상의 피벗 탭이 있을 경우, 연관 분석 기능을 사용할 수 있습니다.
- 그 외에 연관 필터, 이벤트 설정, 경보 설정도 사용할 수 있습니다. 이벤트 및 경보 설정은 주로 위젯을 구성할 때 사용하는 기능입니다.
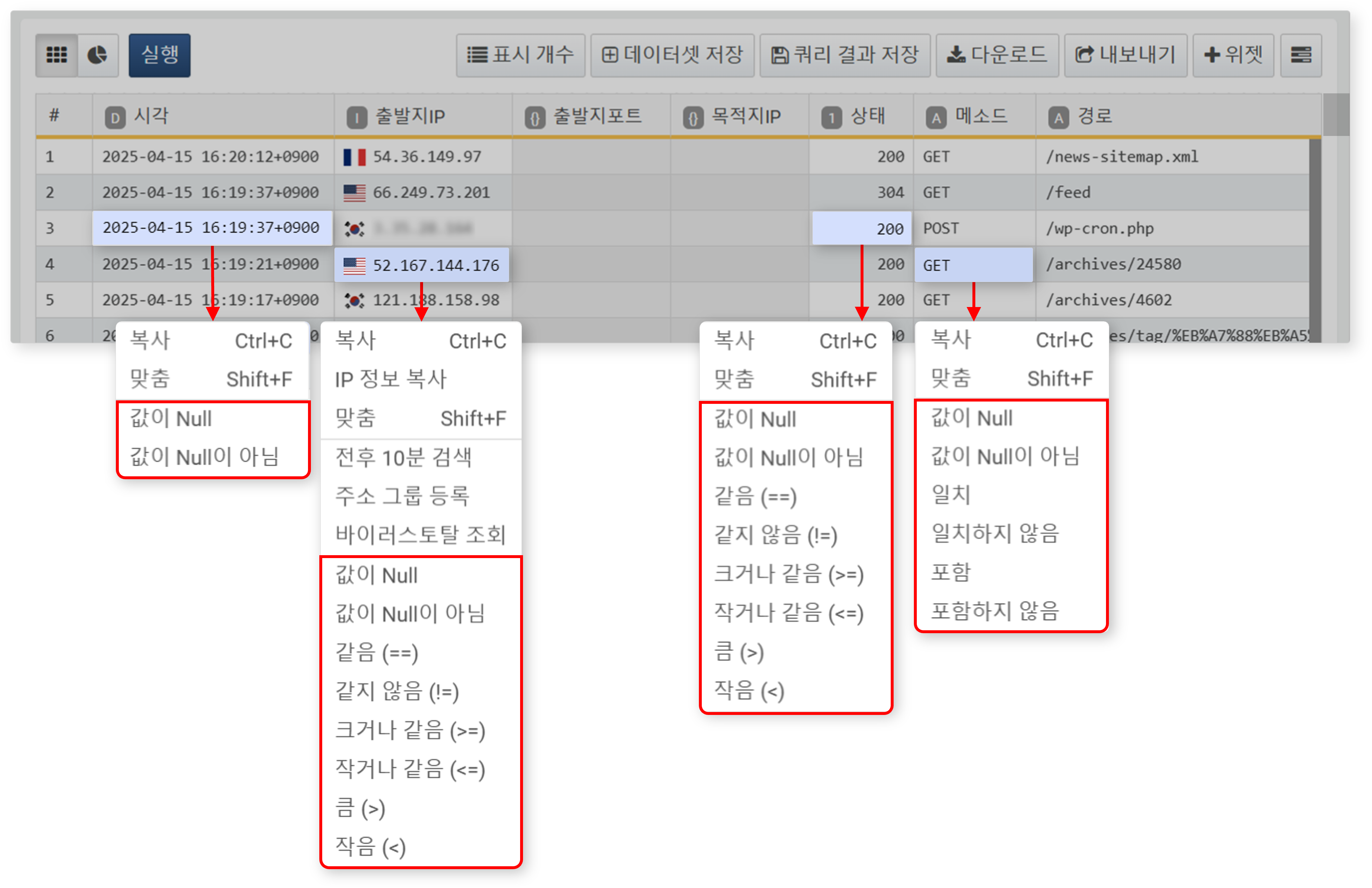
- 셀을 보조 클릭
- 작업 공간의 특정 셀을 보조 클릭하면, 해당 셀 값을 기준으로 필터를 적용할 수 있습니다.
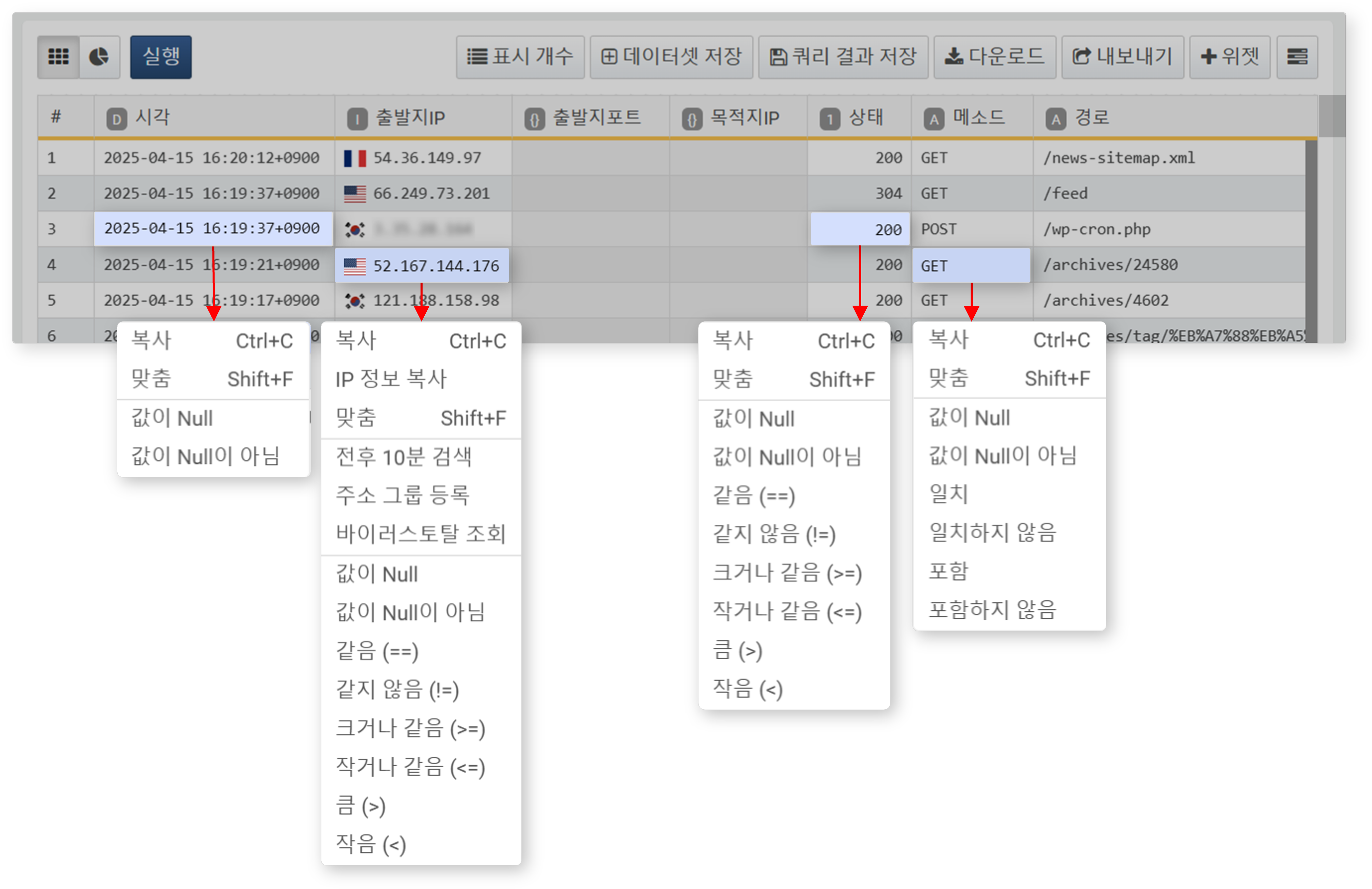
- 셀 값을 기준으로 조건 필터를 적용할 수 있으며, 필터 항목은 데이터 유형에 따라 다르게 표시됩니다.
- IP 주소 데이터가 포함된 셀을 클릭하면 전후 10분 검색, 주소 그룹 등록, 바이러스토탈 조회 기능을 사용할 수 있습니다.
입력/결과 필터
필터, 정렬 설정과 수식은 모두 쿼리로 변환되어 실행됩니다. 필터/수식/정렬이 적용되는 시점에 따라 입력 필터와 결과 필터로 구분됩니다.
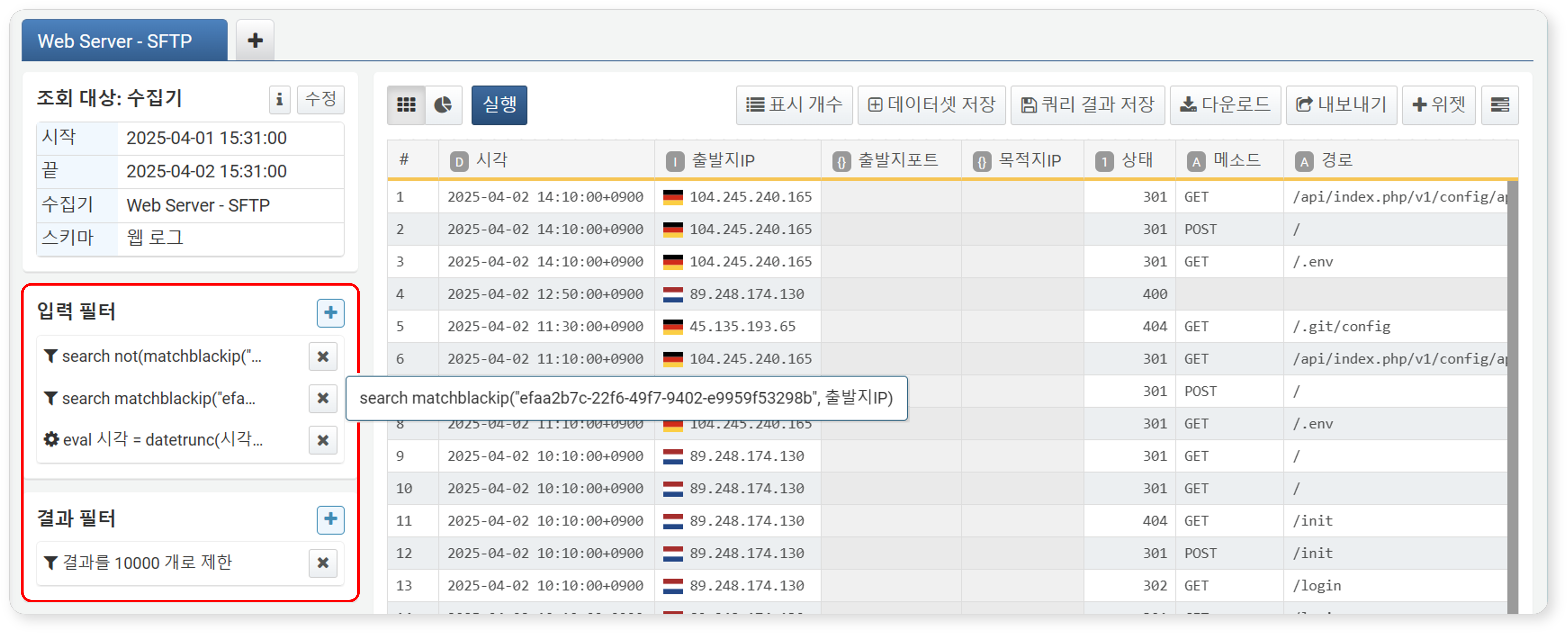
-
입력 필터: 데이터 적재 단계에 적용되는 전처리 필터입니다. 집계가 수행되기 전, 필터/수식/정렬이 지정되면 입력 필터로 처리되며, 이들은 쿼리문 보기로 확인할 수 있습니다.
-
결과 필터: 데이터 분석 단계에서 적용되는 후처리 필터입니다. 행, 열, 값이 설정되어 집계가 수행된 이후, 집계된 데이터에 조건을 적용할 때 결과 필터로 처리됩니다.
- 깔때기 아이콘: 일반 필터
- 톱니바퀴 아이콘: 사용자 정의 변수가 포함된 필터
필터 해제
입력 또는 결과 필터에서 적용된 필터를 제거하려면, 필터 오른쪽에 있는  아이콘을 클릭하세요.
아이콘을 클릭하세요.
필터
필터는 조건에 맞는 데이터만 선별하여 분석에 집중할 수 있도록 도와주는 도구입니다.
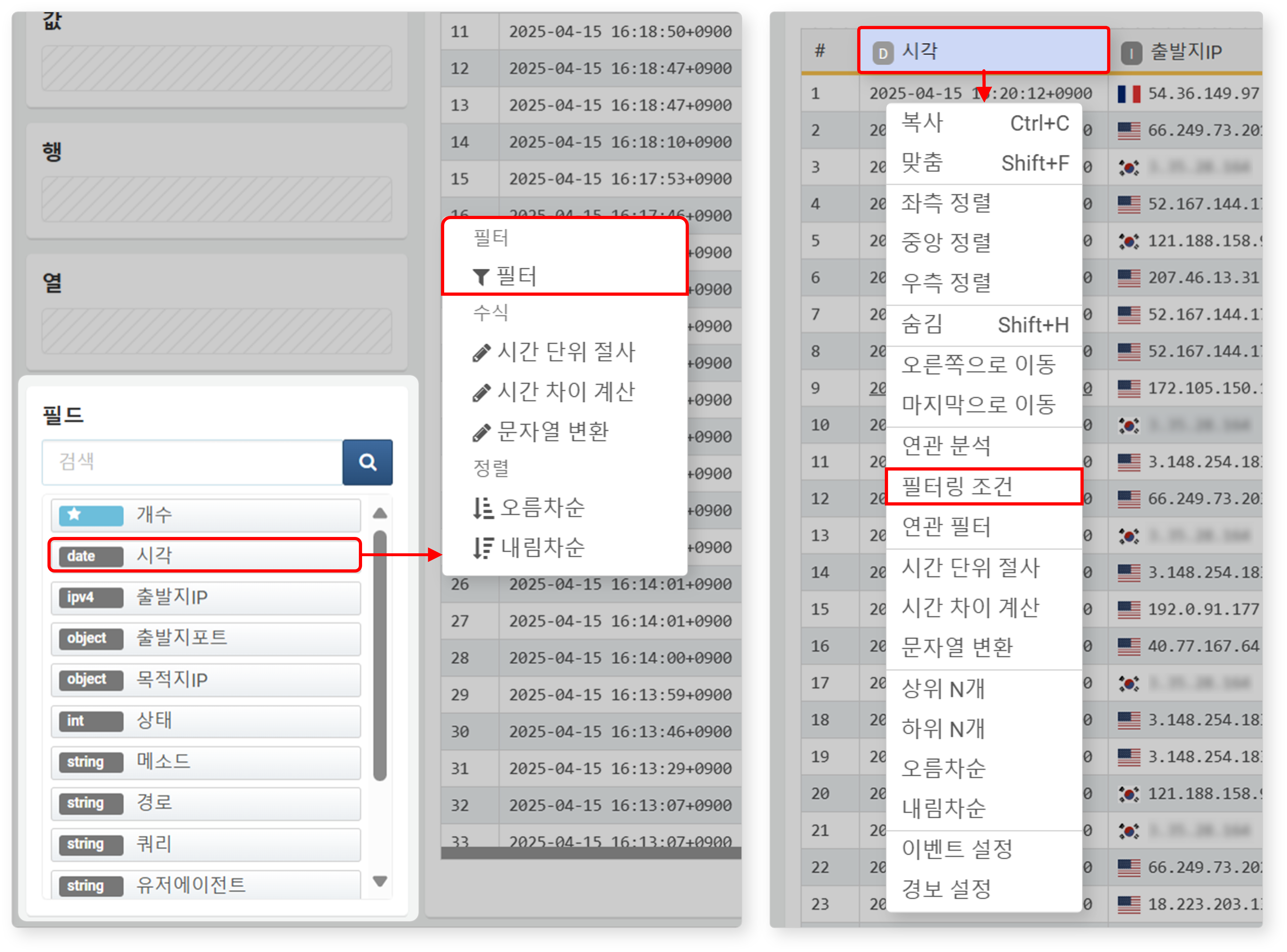
필터링 조건 (또는 필터)
지정한 필드 값이 특정 조건을 만족하는 데이터만 선별하려면 필터를 사용하세요. 필드 팝업 메뉴에서 필터를 클릭하거나, 열 이름의 팝업 메뉴에서 필터링 조건을 클릭해 필터를 설정할 수 있습니다.
필터 추가 대화상자에서 필터 설정을 지정할 수 있습니다.
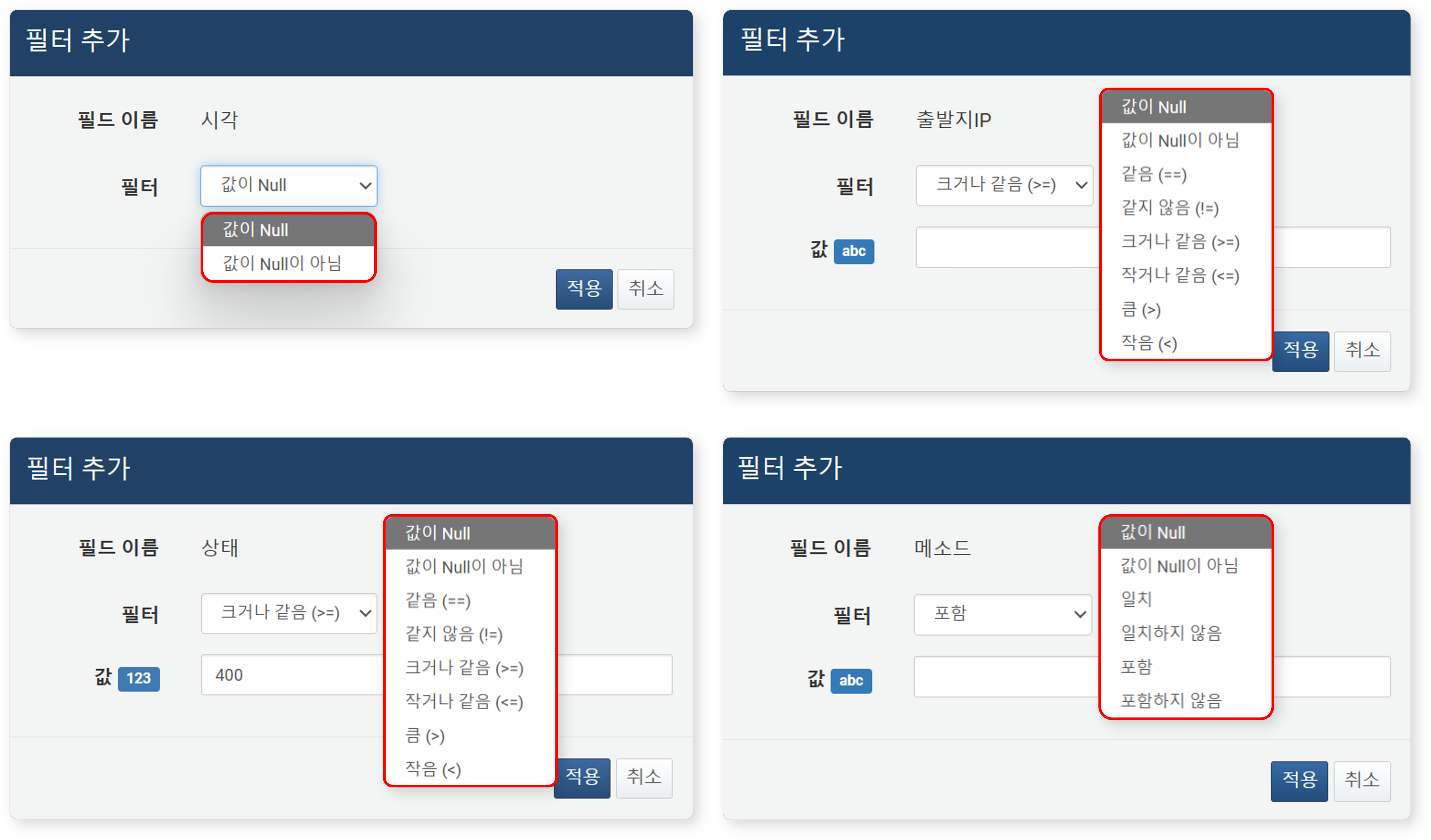
- 필드 이름: 필터를 적용할 필드(열 이름)를 선택하세요.
- 필터: 적용할 비교 조건을 선택하세요. 데이터 유형에 따라 제공되는 조건이 달라집니다.
- 값: 비교 기준이 되는 값을 입력하세요.
또는, 셀 팝업 메뉴를 통해 셀 값을 기준으로 직접 비교 조건을 설정할 수 있습니다.
데이터 유형별로 지원하는 비교 조건은 다음을 참고하세요.
| 조건 | 데이터 유형 | 쿼리 |
|---|---|---|
| 값이 Null | 모든 유형(리스트, 객체 포함) | search isnull(FIELD_NAME) |
| 값이 Null이 아님 | 모든 유형(리스트, 객체 포함) | search isnotnull(FIELD_NAME) |
| 같음(==) | IP 주소, 정수, 실수 | search FIELD_NAME == VALUE_EXPR |
| 같지 않음(!=) | IP 주소, 정수, 실수 | search FIELD_NAME != VALUE_EXPR |
| 크거나 같음(>=) | IP 주소, 정수, 실수 | search FIELD_NAME >= VALUE_EXPR |
| 작거나 같음(<=) | IP 주소, 정수, 실수 | search FIELD_NAME <= VALUE_EXPR |
| 큼(>) | IP 주소, 정수, 실수 | search FIELD_NAME > VALUE_EXPR |
| 작음(<) | IP 주소, 정수, 실수 | search FIELD_NAME < VALUE_EXPR |
| 일치 | 문자열 | search FIELD_NAME == "STR" |
| 일치하지 않음 | 문자열 | search FIELD_NAME != "STR" |
| 포함 | 문자열 | search contains(FIELD_NAME, "STR") |
| 포함하지 않음 | 문자열 | search not(contains(FIELD_NAME, "STR")) |
불리언 값(true, false 중 하나)을 갖는 필드에 필터를 적용하려면, 일반 필터(쿼리 필터) 설명을 참고하세요.
주소 그룹 필터
주소 그룹 필터는 IP 주소 필드에 적용할 수 있는 전용 필터로, 필드 값이 특정 주소 그룹에 포함되거나 포함되지 않은 경우만 조회하고자 할 때 사용합니다. IP 주소를 그룹 단위로 효율적으로 관리하고, 보안 정책 또는 분석 목적에 맞게 빠르게 필터링할 수 있습니다.
필터를 설정하려면 필드 목록 또는 데이터 열 이름의 팝업 메뉴에서 주소 그룹 필터를 클릭하세요.
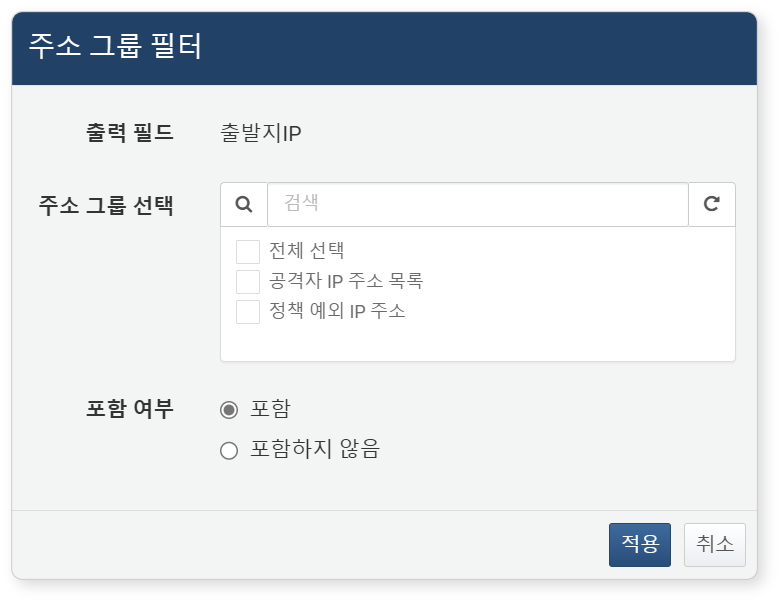
- 출력 필드: 필터를 적용할 필드(예: 출발지IP, 목적지IP 등)를 선택하세요.
- 주소 그룹 선택: 주소 그룹을 하나 이상 선택하세요.
- 포함 여부: 필드 값이 주소 그룹에 포함되는지 여부를 조건으로 지정하세요.
- 포함: 주소 그룹에 포함된 IP 주소만 조회(기본값)
- 포함하지 않음: 주소 그룹에 포함되지 않은 IP 주소만 조회
주소 그룹 필터는 다음과 같은 쿼리로 자동 변환되어 입력 필터 또는 결과 필터로 등록됩니다.
| 조건 | 쿼리 |
|---|---|
| 포함 | search matchblackip("ADDRGRP_GUID", FIELD_NAME) |
| 포함하지 않음 | search not(matchblackip("ADDRGRP_GUID", FIELD_NAME) |
주소 그룹을 2개 이상 선택하면 다음과 같이 "or" 조건으로 결합된 쿼리로 변환됩니다.
search not(
(
matchblackip("efaa2b7c-22f6-49f7-9402-e9959f53298b", 출발지IP)
or matchblackip("c310a9a0-5c04-414a-8b7e-66cd1807c2ab", 출발지IP)
)
)
네트워크 대역 필터
네트워크 대역 필터는 IP 주소 필드에 적용 가능한 전용 필터로, 필드 값이 특정 네트워크 대역에 포함되거나 포함되지 않은 경우만 조회하고자 할 때 사용합니다. 네트워크 구조에 따라 특정 대역의 IP만 선별하고자 할 때 유용하게 사용할 수 있습니다.
필터를 설정하려면 필드 목록 또는 데이터 열 이름의 팝업 메뉴에서 네트워크 대역 필터를 클릭하세요.
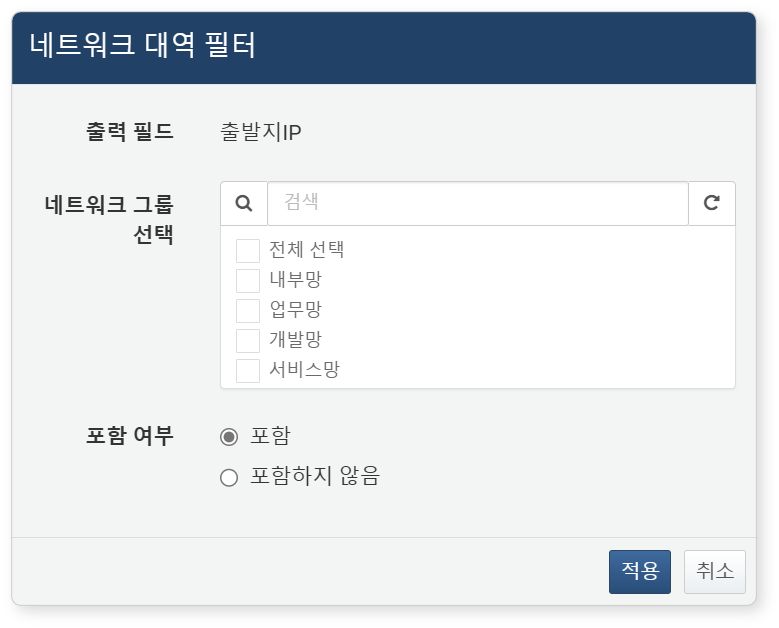
- 출력 필드: 필터를 적용할 필드(열 이름)를 선택하세요.
- 네트워크 그룹 선택: 네트워크 대역을 하나 이상 선택하세요.
- 포함 여부: 필드 값이 네트워크 대역에 포함되는지 여부를 조건으로 지정하세요.
- 포함: 선택한 대역에 포함된 IP만 조회(기본값)
- 포함하지 않음: 선택한 대역에 포함되지 않은 IP만 조회
네트워크 대역 필터는 다음과 같은 형태의 쿼리로 자동 변환되어 입력 필터 또는 결과 필터로 등록됩니다.
| 조건 | 쿼리 |
|---|---|
| 포함 | search matchnet("SUBNETGRP_GUID", FIELD_NAME) |
| 포함하지 않음 | search not(matchnet("SUBNETGRP_GUID", FIELD_NAME)) |
네트워크 대역을 2개 이상 선택하면 다음과 같이 "or" 조건으로 결합된 쿼리로 변환됩니다.
search matchnet("bb994ca4-1471-4b91-89f2-99a61bd529b5", 출발지IP)
or matchnet("bb8525ea-791a-4b8b-94c6-7720da420eb8", 출발지IP)
고급 필터
일반 필터 (쿼리 필터)
기본 제공 필터로 구현할 수 없는 고급 조건을 직접 쿼리문으로 입력하여 고급 검색을 실행할 수 있습니다.
-
입력 필터 또는 결과 필터 영역에서
 > 일반 필터를 클릭하세요.
> 일반 필터를 클릭하세요.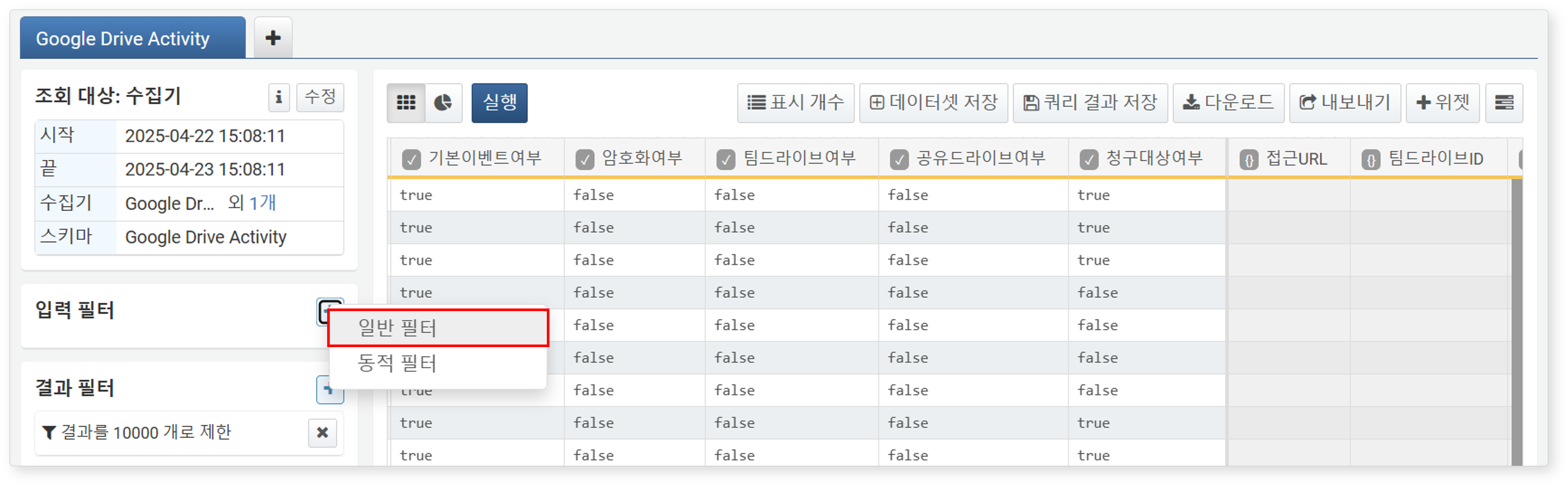
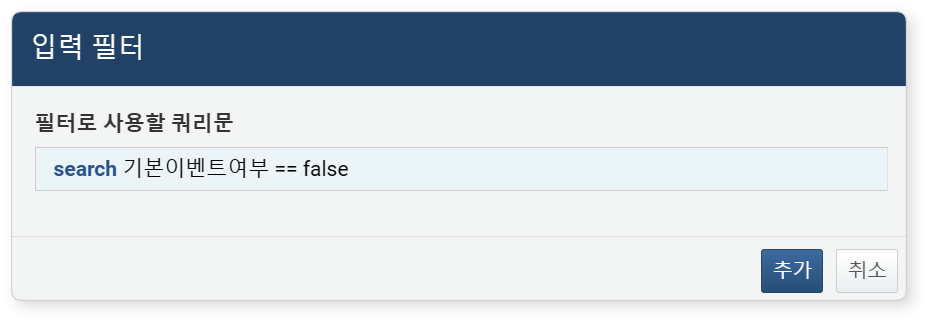
-
필터로 사용할 쿼리문을 입력하세요. 예를 들어, 불리언 타입 필드에서
true또는false값을 가진 레코드만 조회하려면 다음과 같이 입력하세요:search FIELD_NAME == true- 또는
search FIELD_NAME == false
-
쿼리를 작성한 후 추가 버튼을 클릭하세요. 지정한 쿼리문에 따라 필터가 적용되고, 결과가 데이터에 반영됩니다.
동적 필터
동적 필터는 사용자가 입력 컨트롤 위젯을 통해 입력한 값을 기반으로 데이터를 필터링하는 기능입니다. 주로 분석 데이터를 대시보드 위젯에서 동적으로 조회할 수 있도록 설정할 때 사용됩니다.
동적 필터가 동작하려면 입력 컨트롤 위젯과 동적 필터는 반드시 동일한 사용자 정의 변수를 공유해야 합니다의
-
입력 필터 또는 결과 필터 영역에서
> 동적 필터를 클릭하세요.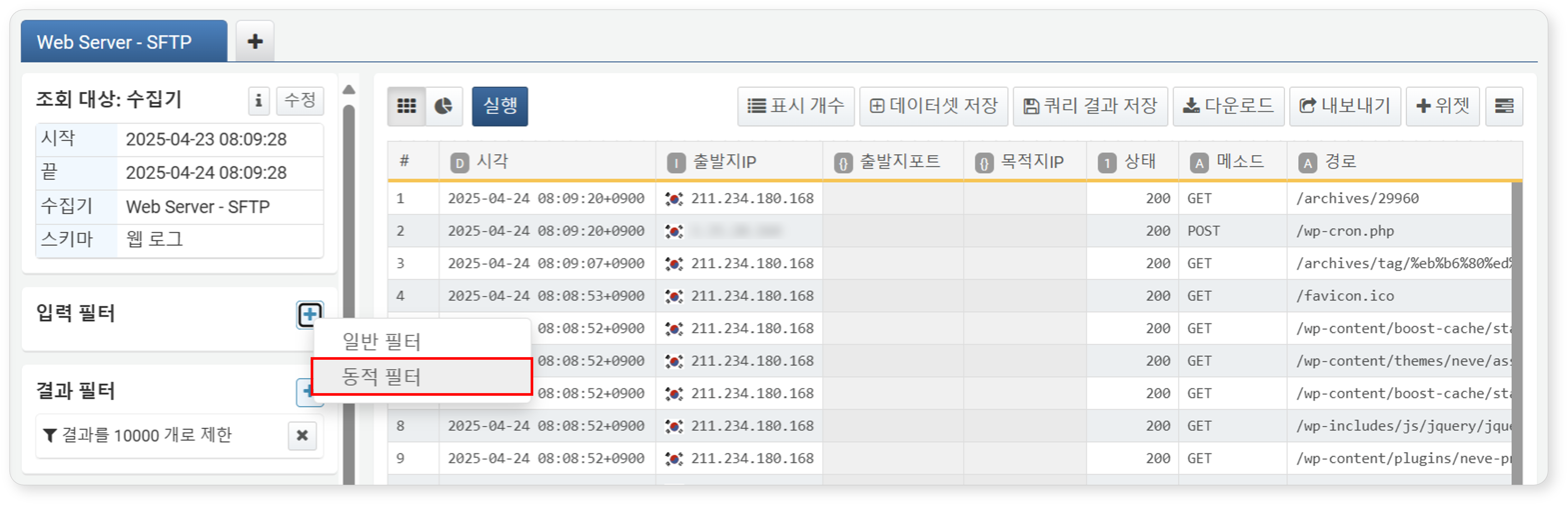
-
동적 필터의 속성을 설정하세요.
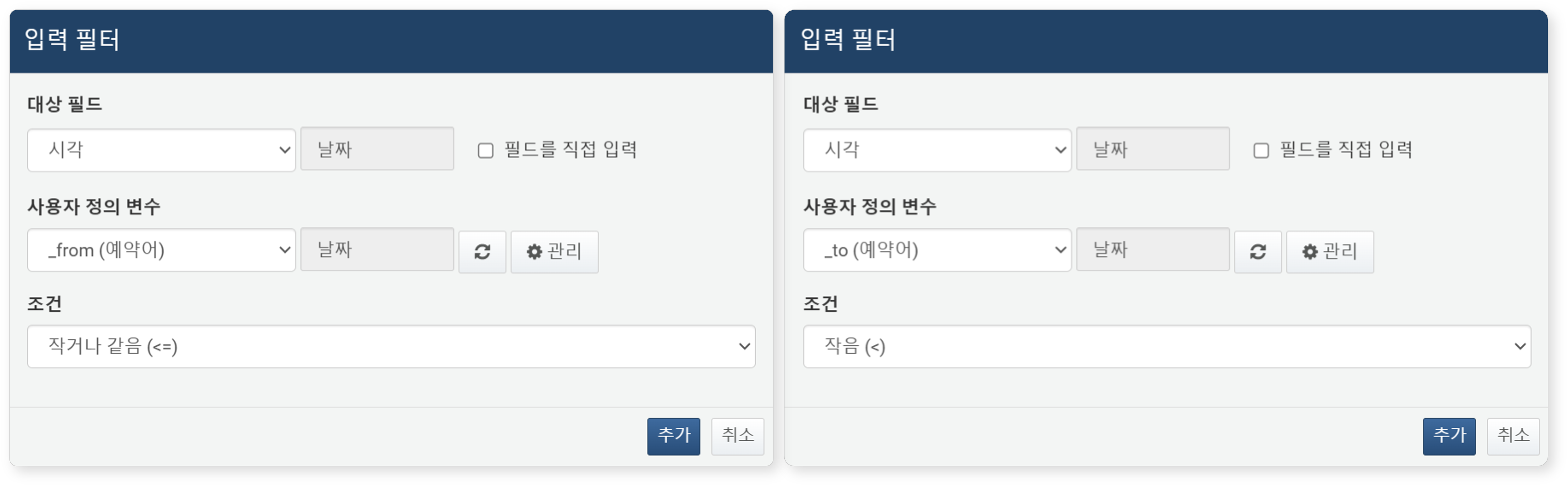
- 대상 필드: 필터를 적용할 필드를 선택하세요. 필요한 경우 필드를 직접 입력할 수도 있습니다.
- 사용자 정의 변수: 입력 컨트롤 위젯에서 사용자가 입력한 값을 받을 변수입니다. 목록에서 선택하거나,아이콘을 클릭하여 새로운 변수를 생성할 수 있습니다.
- 조건: 대상 필드 값과 사용자 정의 변수 값을 비교할 조건을 선택하세요.
- 비교식은 대상 필드 값(좌항) 과 사용자 정의 변수(입력값, 우항)의 비교로 동작합니다.
- 데이터 유형에 따라 사용할 수 있는 조건이 다릅니다. 자세한 내용은 필터링 조건 (또는 필터)을 참고하세요.
 버튼을 클릭하면 새 창에서 사용자 정의 변수 목록을 조회하거나, 새 사용자 정의 변수를 추가할 수 있습니다.
버튼을 클릭하면 새 창에서 사용자 정의 변수 목록을 조회하거나, 새 사용자 정의 변수를 추가할 수 있습니다. 버튼을 클릭하면 사용자 정의 변수 목록을 갱신할 수 있습니다.
버튼을 클릭하면 사용자 정의 변수 목록을 갱신할 수 있습니다.
-
필터가 정상적으로 적용되었는지 확인하세요.
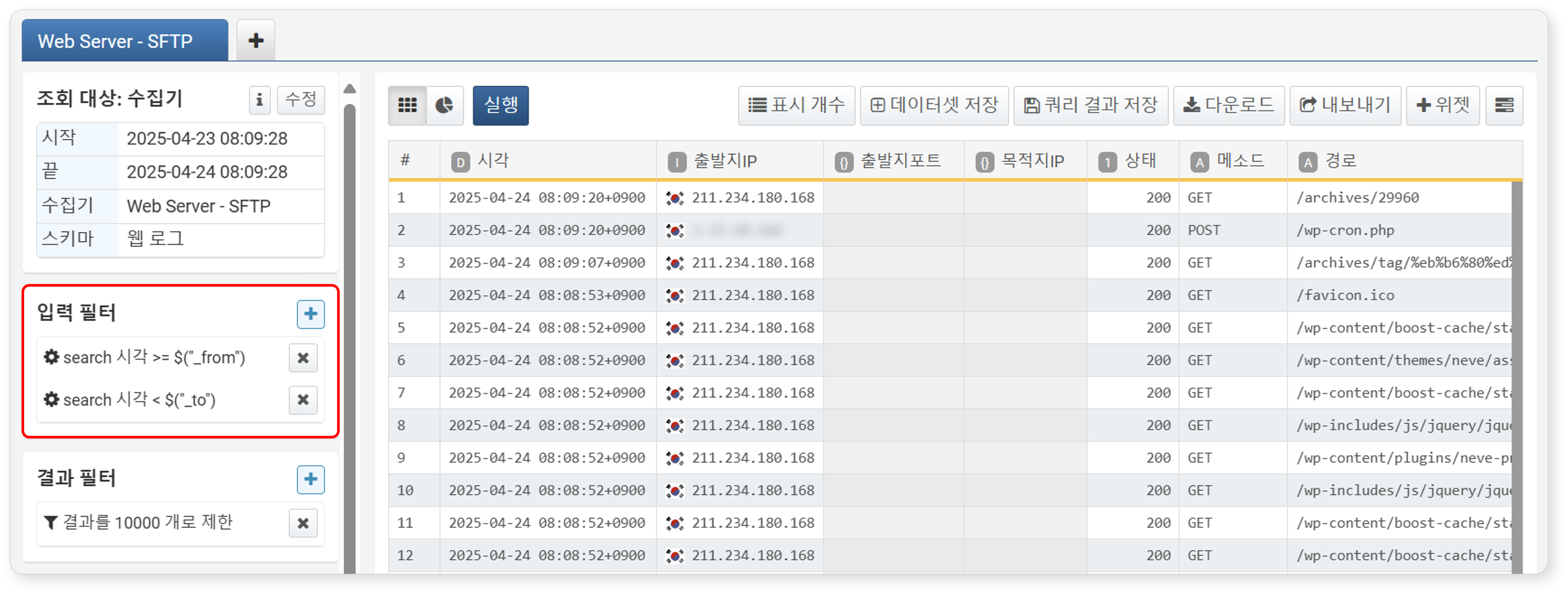
table,fulltext같은 쿼리 명령어에서from,to시구간 옵션을 사용하면 시작 시각은 포함되지만, 마지막 시각은 포함되지 않습니다. 예시의 동적 필터도_to변수로 주어진 시각은 포함되지 않도록 설정되어 있습니다.- 동적 필터는 설정 직후에는 필터 쿼리로만 존재하며, 실제 필터링은 대시보드에서 입력 컨트롤을 통해 값을 입력 또는 선택한 후에 적용됩니다.
연관 필터
연관 필터는 하나의 피벗 화면에서 분석한 결과를 다른 피벗 탭의 필터 조건으로 활용할 수 있는 기능입니다. 예를 들어, 첫 번째 피벗 탭에서 상위 공격 IP 주소 5개를 추출하고, 두 번째 탭에서는 해당 IP가 포함된 방화벽 로그만 필터링해서 분석할 수 있습니다.
연관 필터는 두 개 이상의 피벗 탭 간에 데이터를 비교한다는 점에서 연관 분석과 유사하지만, 분석보다는 데이터 필터링에 중점을 둔다는 점에서 차이가 있습니다. 연관 필터는 특정 필드를 기준으로 분석 범위를 좁히는 데 사용됩니다.
연관 필터를 사용하려면 두 개 이상의 피벗 탭이 열려 있어야 합니다. 사용 방법은 아래와 같습니다.
-
작업 공간에서 연관 필터를 적용할 필드를 보조 클릭한 뒤, 연관 필터 메뉴를 클릭하세요.
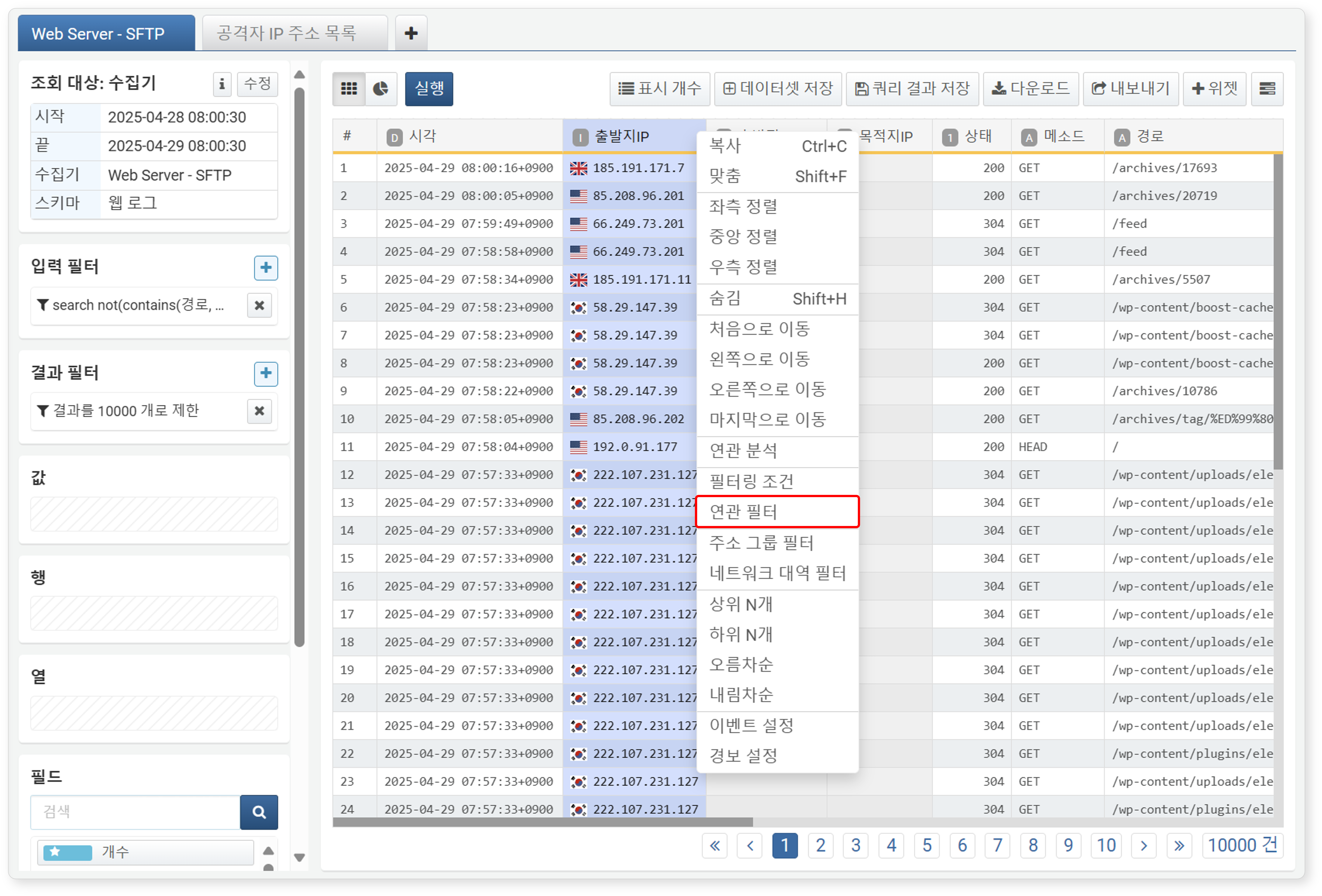
-
연관 필터 대화상자에서 아래 항목을 설정하고 적용 버튼을 클릭하세요.
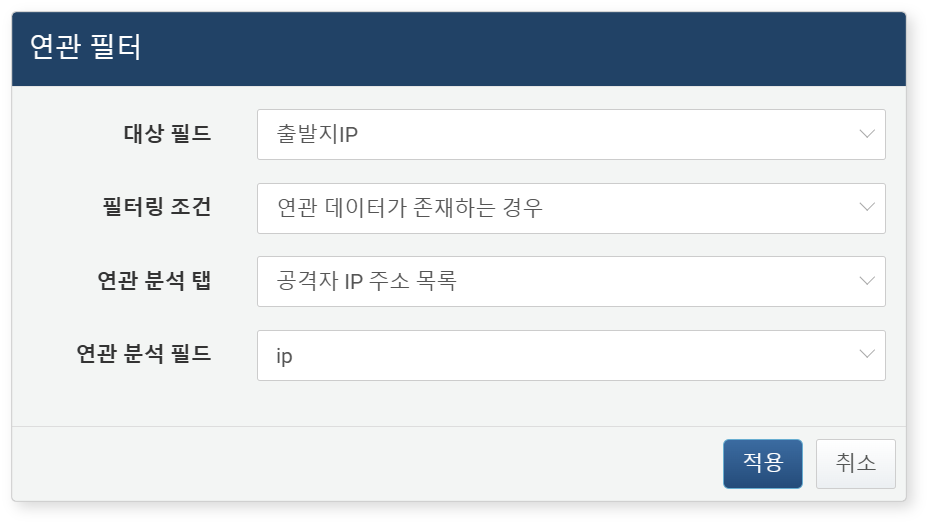
- 대상 필드: 필터를 적용할 필드를 선택하세요(기본값: 선택된 필드).
- 필터링 조건: 검색 조건을 설정하세요.
- 연관 데이터가 존재하는 경우: 대상 필드 값이 연관 분석 필드 값과 일치하는 경우만 조회(기본값)
- 연관 데이터가 존재하지 않는 경우: 대상 필드 값이 연관 분석 필드 값과 일치하지 않는 경우만 조회
- 연관 분석 탭: 비교 기준이 될 연관 필드가 포함된 다른 피벗 탭을 선택하세요.
- 연관 분석 필드: 연관 탭에서 비교 대상으로 사용할 필드를 선택하세요.
-
필터를 적용하면 현재 피벗 탭은 연관 분석 결과 화면으로 전환됩니다. 적용된 필터 조건에 따라 대상 필드 값이 다른 탭의 값과 일치 또는 불일치하는 경우만 남기고 나머지 데이터는 제외됩니다.
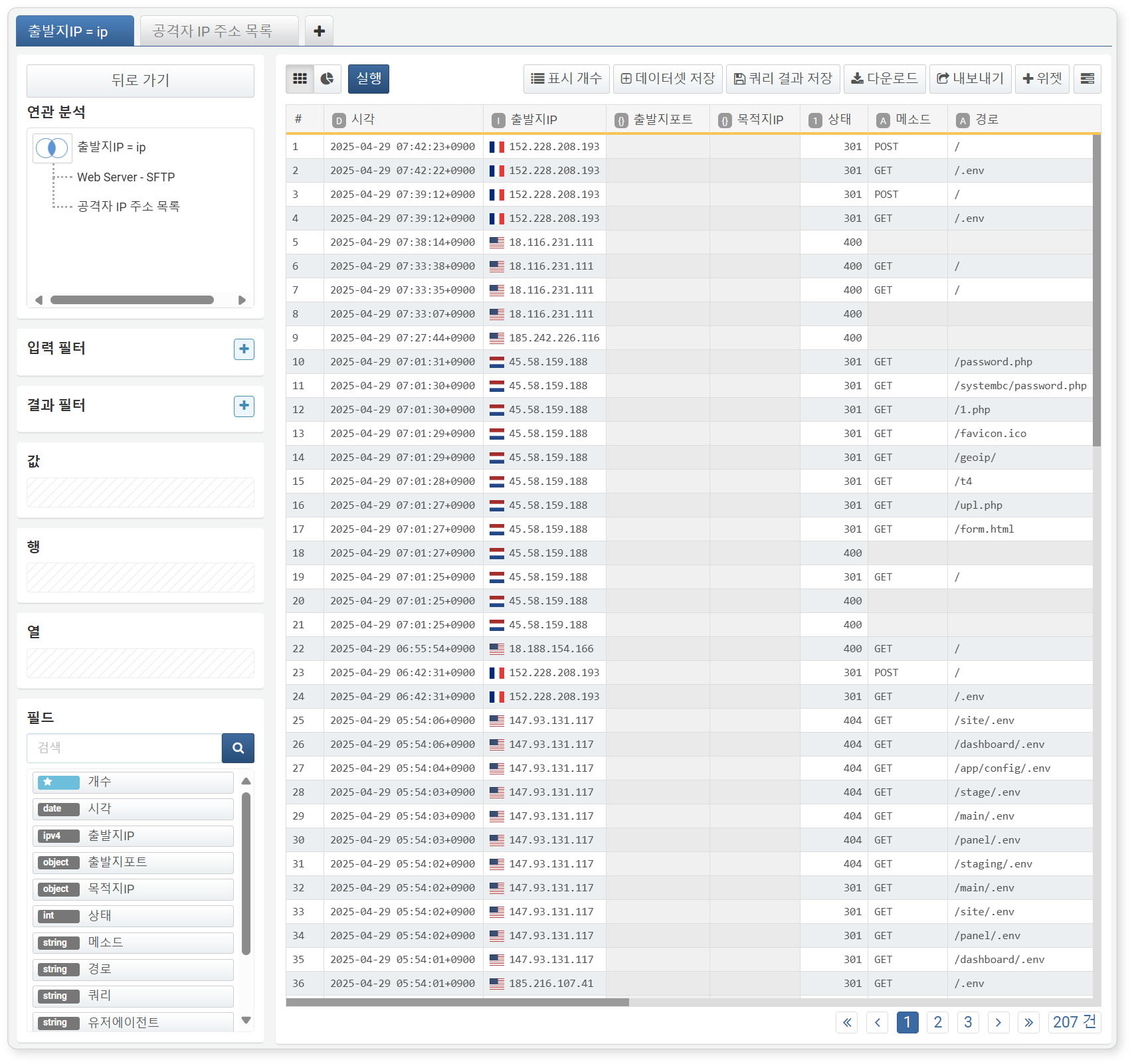
- 기존 피벗 탭과 동일하게 필터, 정렬, 수식, 추가 분석을 적용할 수 있습니다.
- 좌측 상단의 뒤로 가기 버튼을 클릭하면 필터 적용 전 상태로 복귀할 수 있습니다.
- 화면에서 수행할 수 있는 작업은 연관 분석을 참고하세요.
수식
날짜형 데이터를 가져온 경우, 수식을 사용해 시간 단위로 절사하거나, 시간차를 계산하거나, 문자열로 변환할 수 있습니다. 이를 통해 시간 데이터를 정밀하게 분석하고, 원하는 형태로 변환하거나 비교할 수 있습니다.
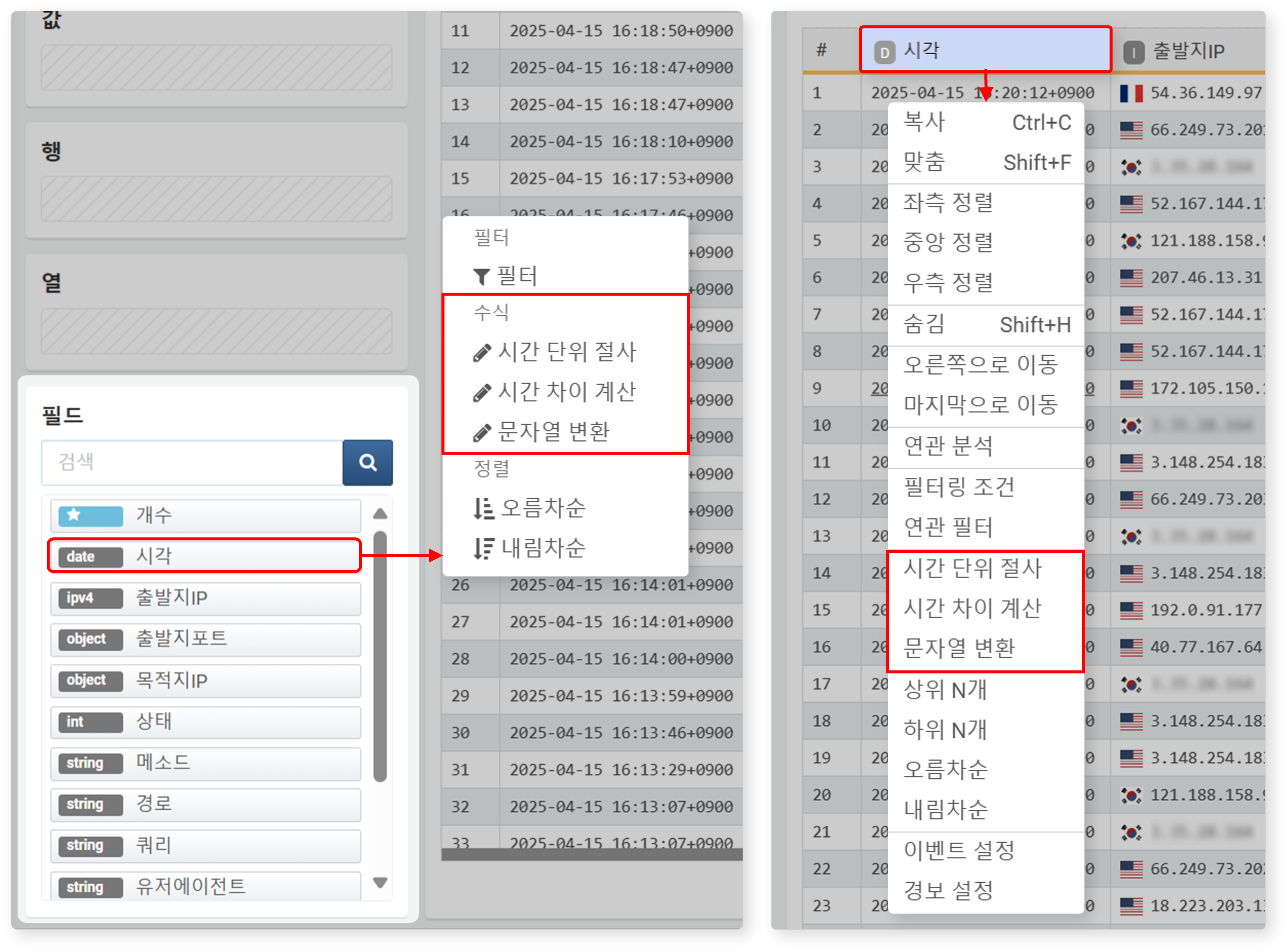
시간 단위 절사
시간 단위 절사는 데이터를 일정한 시구간(예: 5분, 1시간 단위)으로 절사해 시계열 분석에 활용할 수 있도록 가공하는 기능입니다. 일반적으로 _time 또는 시각 필드에 적용됩니다.
날짜형 필드 또는 데이터 열의 팝업 메뉴에서 시간 단위 절사 메뉴를 클릭하면 아래와 같은 설정 대화상자가 열립니다.
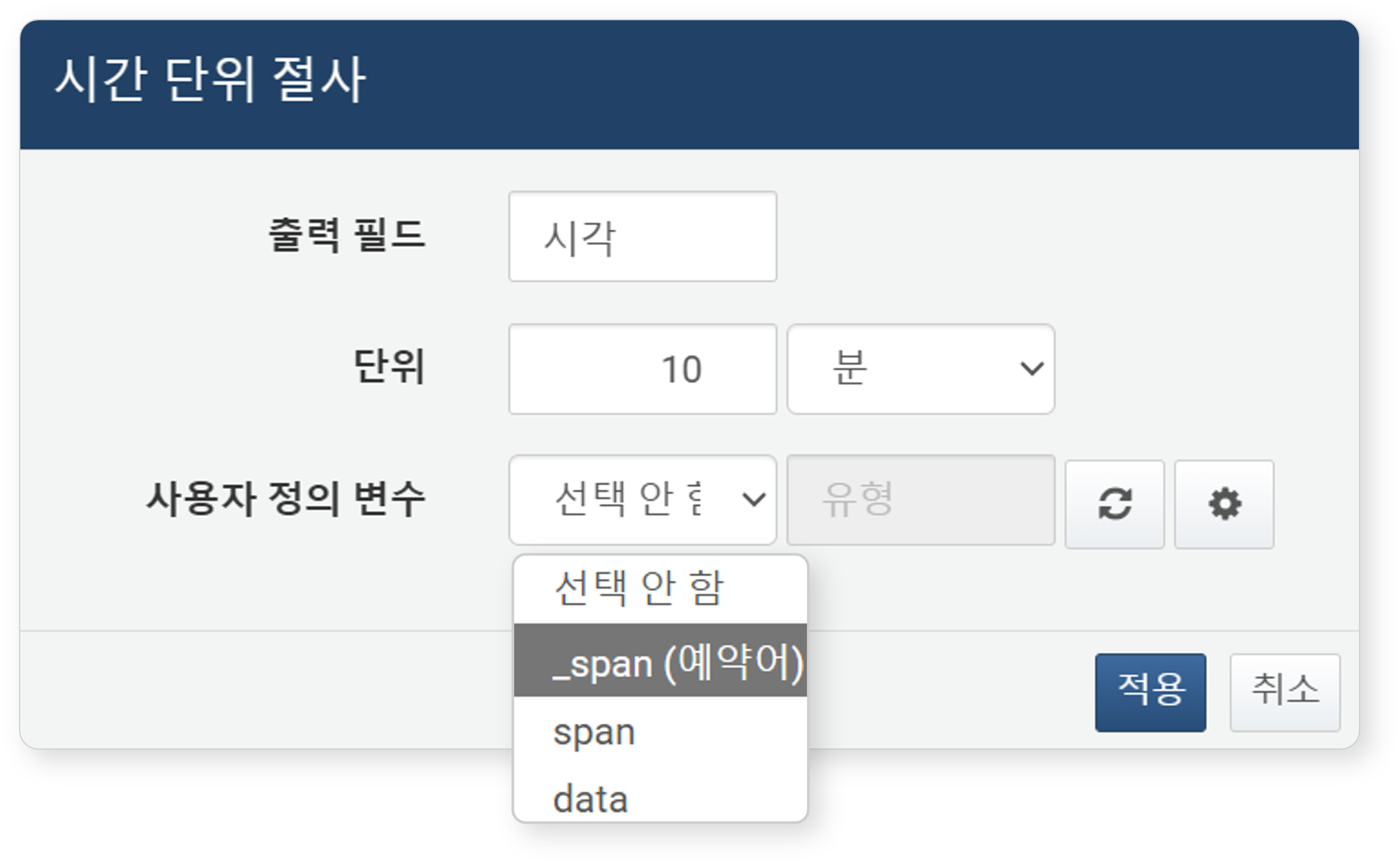
- 출력 필드(필수): 수식을 적용할 필드를 입력하세요.
- 단위(필수): 절사할 시간 단위를 설정하세요(기본값: 10분). 단위는 년, 월, 주, 일, 시, 분, 초, 밀리초 중에서 선택할 수 있습니다.
- 사용자 정의 변수(선택): 입력 컨트롤 위젯을 통해 입력된 값을 시간 단위로 사용할 경우 선택하세요. 목록에서 사용자 정의 변수를 선택하세요.
- 버튼을 클릭하면 새 창에서 사용자 정의 변수 목록을 조회하거나, 새 사용자 정의 변수를 추가할 수 있습니다.
- 버튼을 클릭하면 사용자 정의 변수 목록을 갱신할 수 있습니다.
입력한 설정값은 다음과 같은 쿼리로 변환되어 필터로 추가됩니다.
eval 시각 = datetrunc(시각, $("_span_", "10m"))
시간 차이 계산
시간 차이 계산는 현재 시각과 선택한 필드 값 간의 차이를 지정한 시간 단위(예: 초, 분, 시, 일 등)로 계산해 표시하는 기능 입니다. 예를 들어, 특정 이벤트 발생 시각과 현재 시각 간의 차이를 ‘분’ 단위로 계산해볼 수 있으며, 이벤트 간 시차를 빠르게 파악할 때 유용합니다.
날짜형 필드의 팝업 메뉴에서 시간 차이 계산 메뉴를 클릭하면 다음과 같은 설정 대화상자가 열립니다.
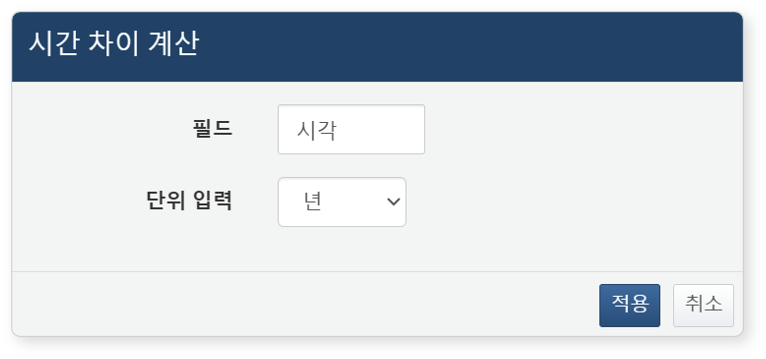
- 필드: 수식을 적용할 필드를 입력하세요.
- 단위 입력: 시차 계산 단위를 입력하세요(기본값: 년). 단위는 년, 월, 주, 일, 시, 분, 초, 밀리초 중에서 선택할 수 있습니다.
입력한 설정값은 다음과 같은 쿼리로 변환되어 필터로 추가됩니다.
eval 시각 = datetdiff(시각, now(), "min")
문자열 변환
문자열 변환은 날짜 값을 지정한 형식의 문자열로 변환하는 기능입니다. 이 기능은 날짜 데이터를 사람이 읽기 쉬운 형식으로 출력하거나, 지정한 형식에 맞춰 출력할 때 유용합니다. 예를 들어, "2025-01-22 15:30:00" 값을 "2025년 1월 22일"과 같이 문자열로 변환할 수 있습니다.
날짜형 필드의 팝업 메뉴에서 문자열 변환 메뉴를 클릭하면 다음과 같은 설정 대화상자가 열립니다.
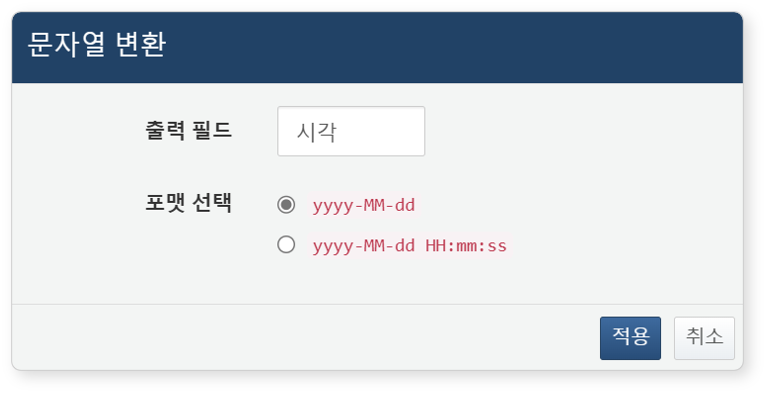
- 출력 필드: 수식을 적용할 필드를 입력하세요.
- 포맷 선택: 출력 형식을 입력하세요(기본값: yyyy-MM-dd).
입력한 설정값은 다음과 같은 쿼리로 변환되어 입력 필터 또는 결과 필터에 등록됩니다.
eval 시각 = string(시각, "yyyy-MM-dd")
정렬
데이터 정렬 및 필드 표시 구성을 설정할 수 있습니다. 원하는 기준에 따라 데이터를 정렬하거나, 화면에 표시할 필드를 효율적으로 관리할 수 있습니다.
필드 이동
스키마를 지정한 경우 필드는 해당 로그 스키마 정의 순서대로, 그렇지 않은 경우 필드 이름을 기준으로 알파벳 순으로 표시됩니다. 대시보드에서 주요 필드를 쉽게 확인할 수 있도록, 필드 순서를 변경하거나 앞쪽에 배치할 수 있습니다.
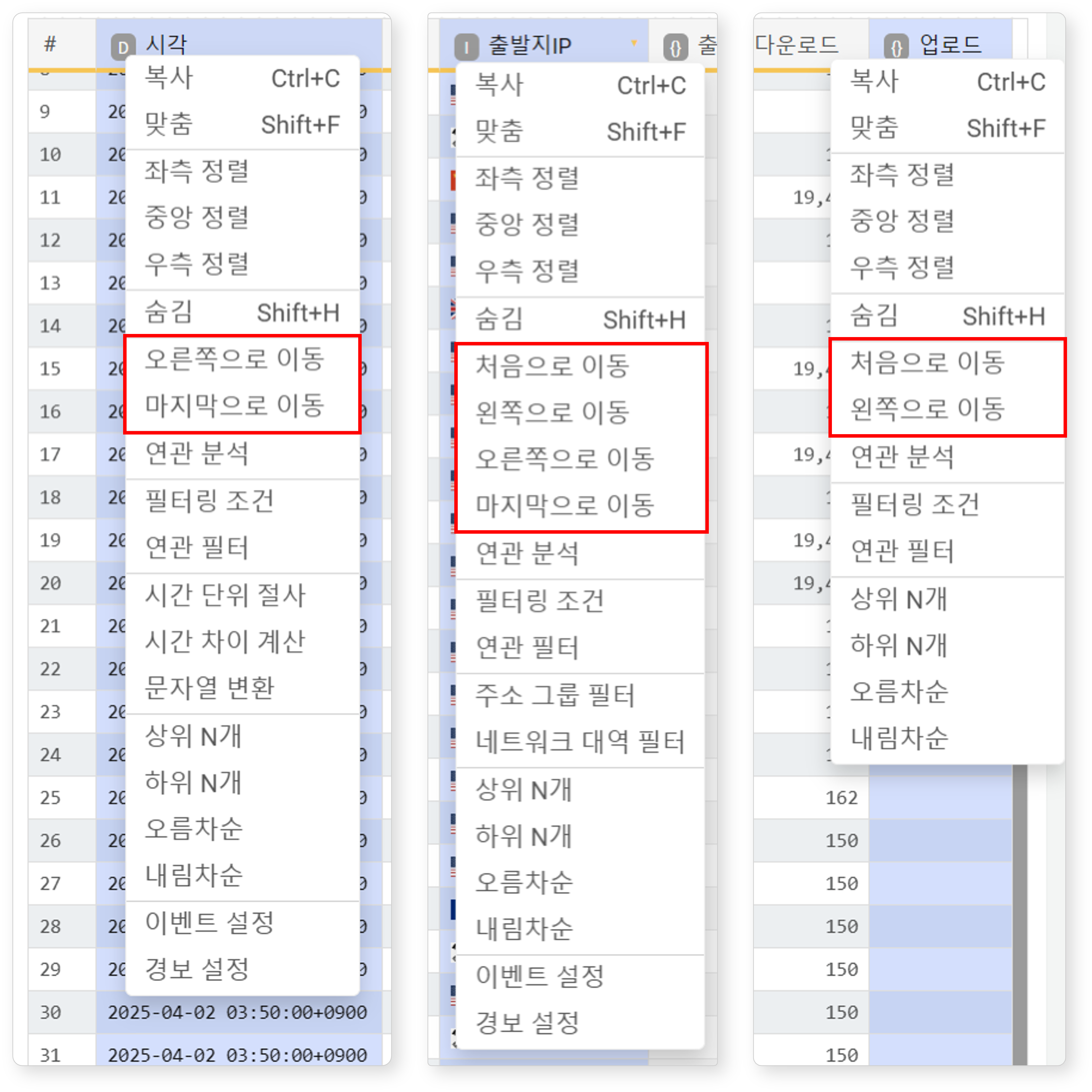
- 처음으로 이동: 선택한 필드를 가장 왼쪽으로 이동
- 왼쪽으로 이동: 선택한 필드를 한 칸 왼쪽으로 이동
- 오른쪽으로 이동: 선택한 필드를 한 칸 오른쪽으로 이동
- 마지막으로 이동: 선택한 필드를 가장 오른쪽으로 이동
필드 숨김/표시
숨기려는 필드를 선택한 뒤 팝업 메뉴에서 숨김을 클릭하거나 Shift+H를 누르세요. 숨겨진 필드는 굵은 실선으로 표시됩니다.
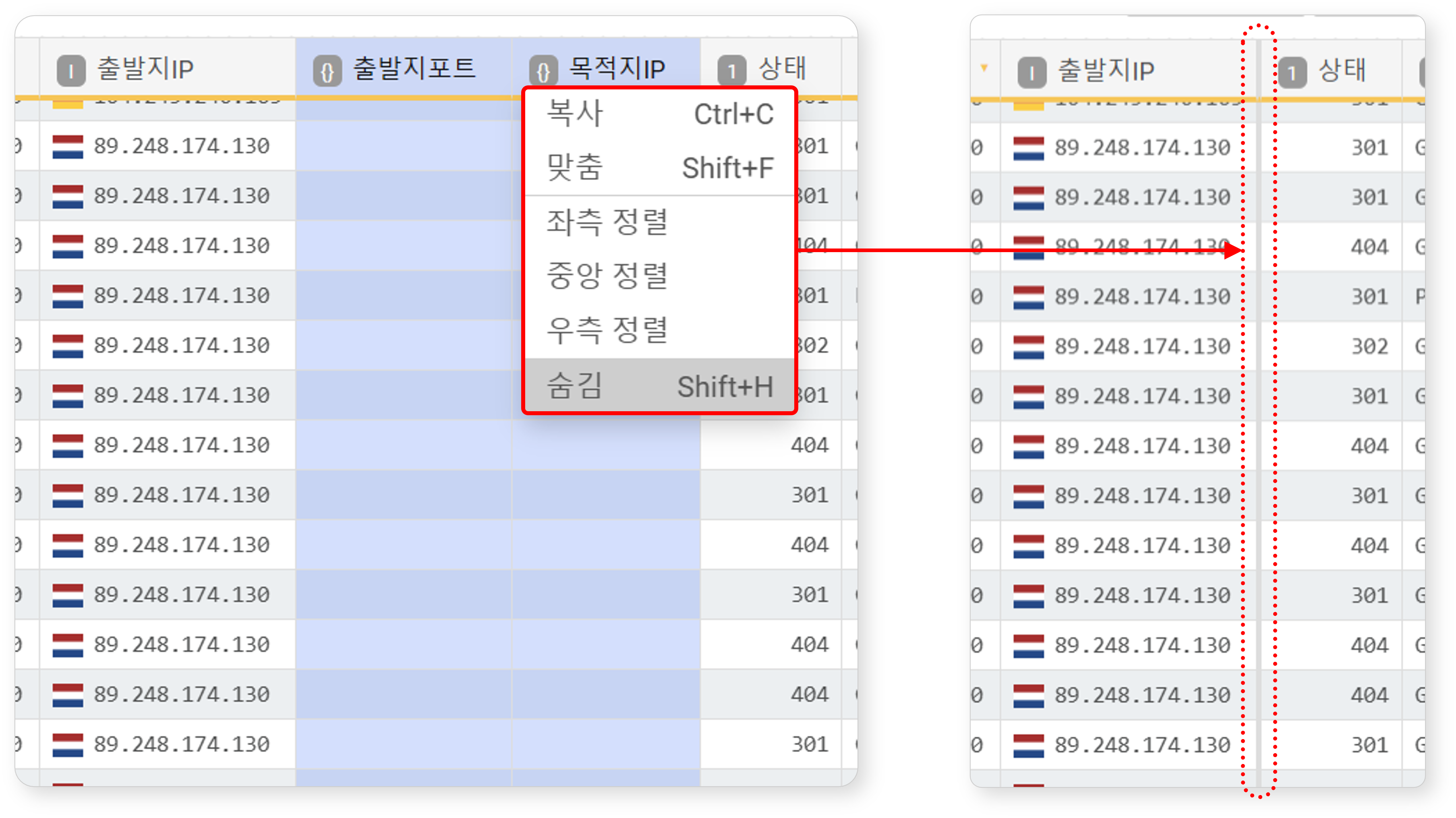
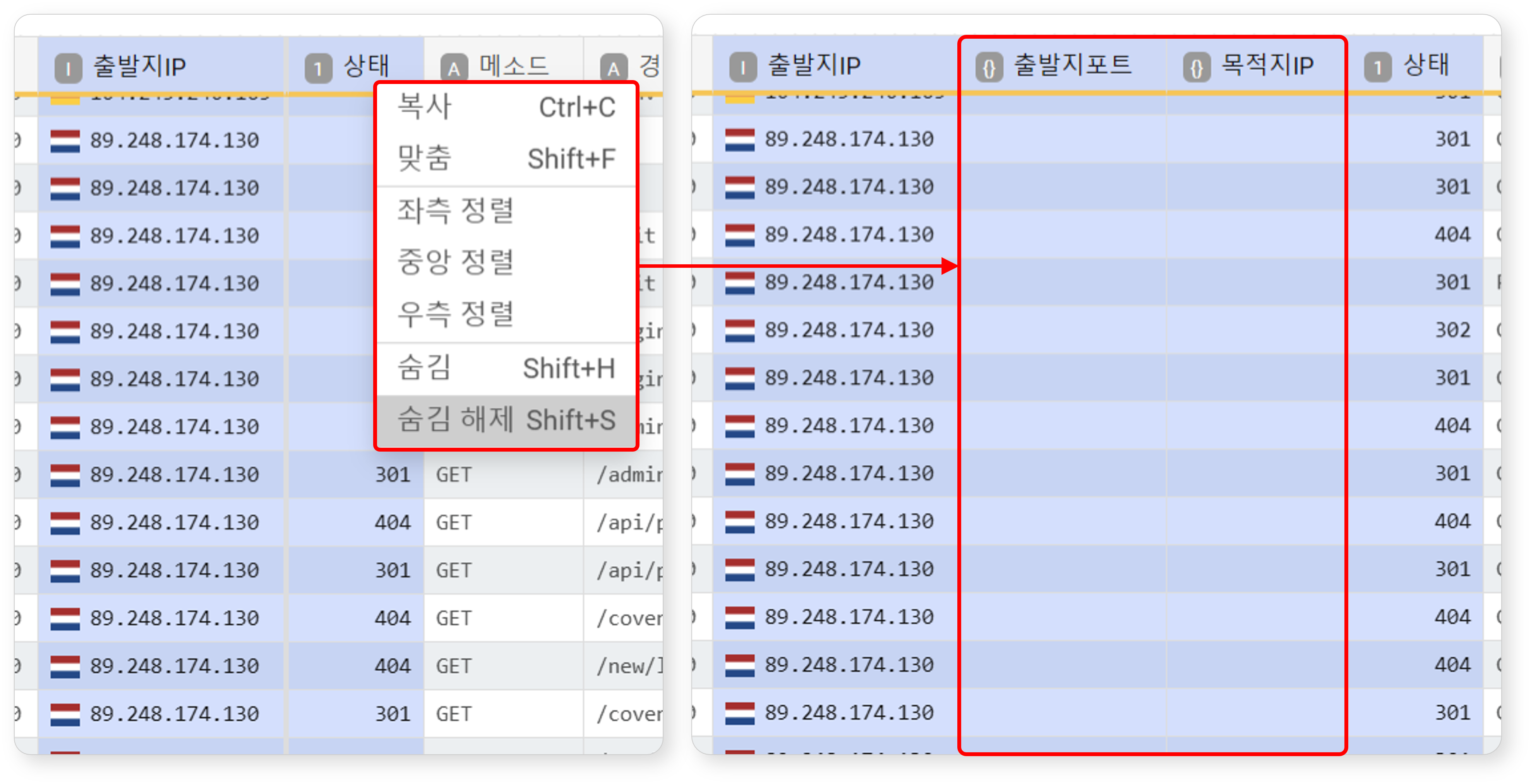
숨긴 필드를 다시 표시하려면 숨겨진 필드 양옆의 필드를 선택한 후 팝업 메뉴에서 숨김 해제를 클릭하거나 Shift+S를 누르세요.
오름차순/내림차순
데이터는 기본적으로 _time 기준 내림차순(최신 순)으로 정렬됩니다. 다른 필드를 기준으로 정렬하려면 해당 필드를 선택하거나 열 이름을 보조 클릭한 뒤, 오름차순 또는 내림차순을 선택하세요.
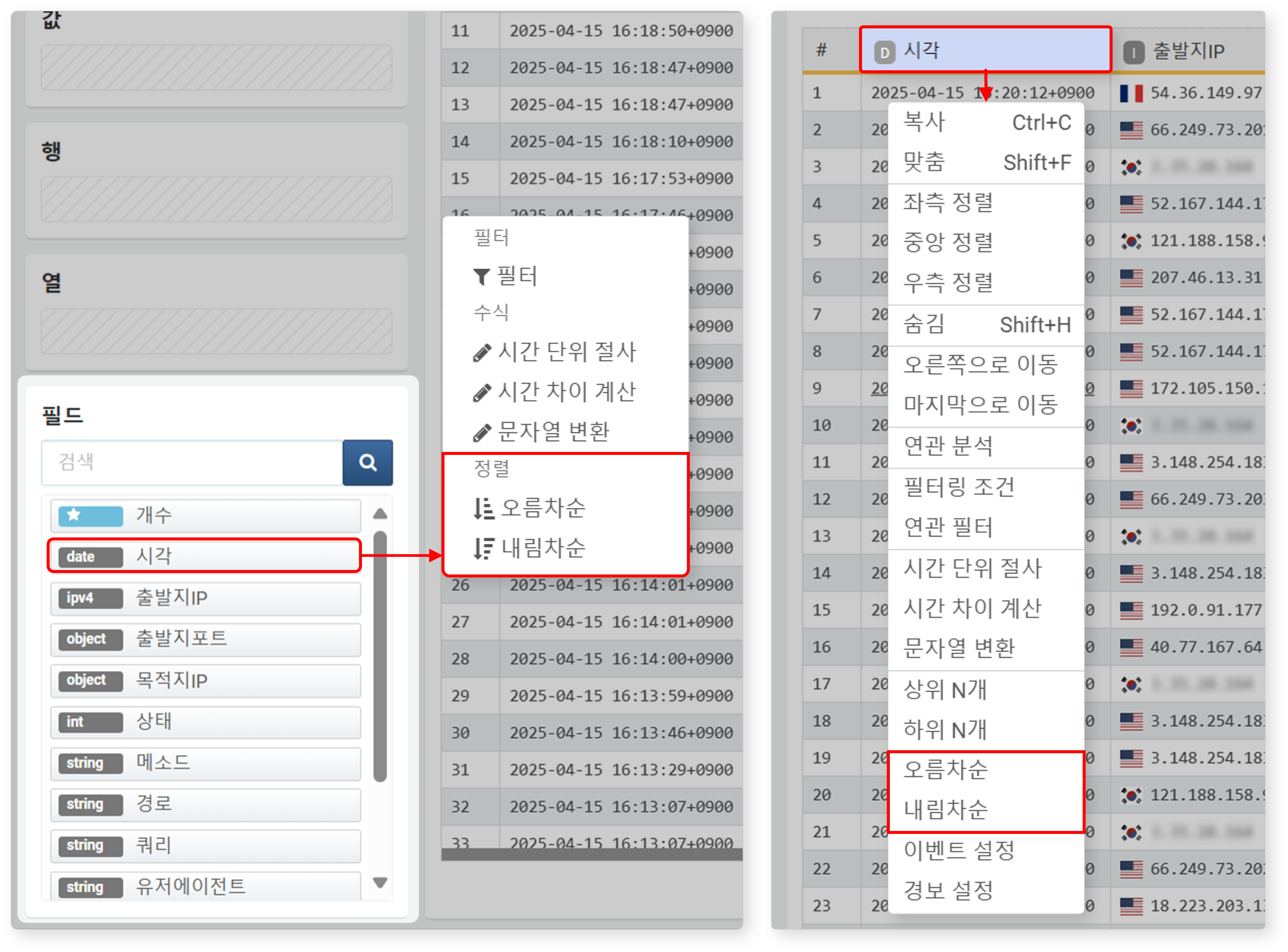
해당 설정은 다음과 같이 sort 쿼리로 변환되어 필터로 추가됩니다:
| 정렬 | 쿼리 |
|---|---|
| 오름차순 | sort FIELD_NAME |
| 내림차순 | sort -FIELD_NAME |
상위 N개/하위 N개
특정 필드를 기준으로 상위 또는 하위 N개의 레코드만 조회할 수 있습니다. 예를 들어, 상위 5개 IP 주소 또는 하위 10개 사용자 ID를 조회할 수 있습니다.
-
작업 영역에서 기준 필드를 보조 클릭하고 상위 N개 또는 하위 N개를 클릭하세요.
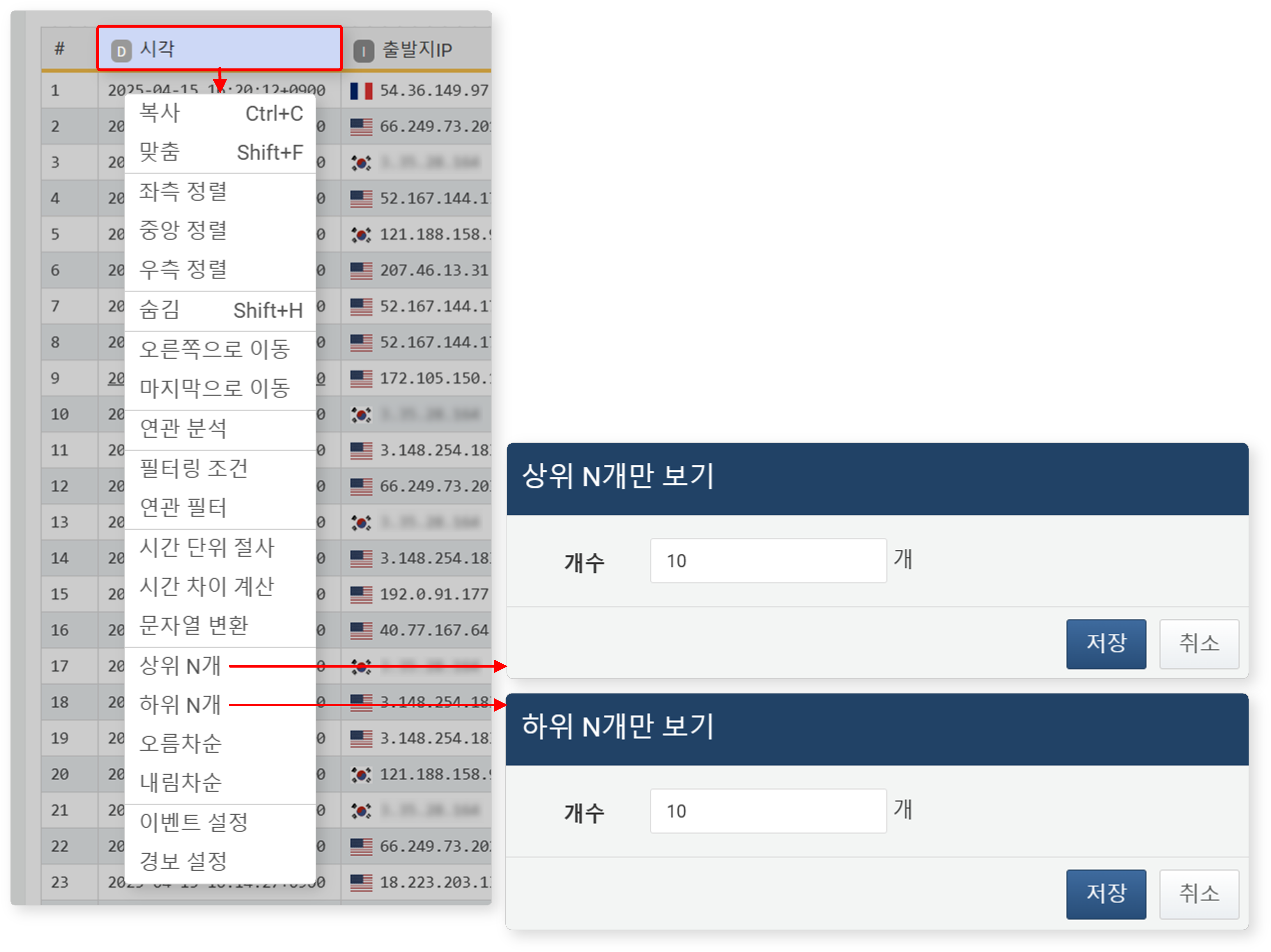
-
개수를 입력하고 저장 버튼을 클릭하세요.
설정은 다음과 같은 쿼리로 변환되어 필터로 추가됩니다:
| 정렬 | 쿼리 |
|---|---|
| 상위 N개 | sort limit=N -FIELD_NAME |
| 하위 N개 | sort limit=N FIELD_NAME |
좌측/중앙/우측 정렬
문자열 필드는 기본적으로 좌측 정렬, 숫자형 필드는 우측 정렬됩니다. 정렬 방식을 변경하려면 필드를 선택한 후 좌측 정렬, 중앙 정렬, 우측 정렬 중 하나를 선택하세요.

맞춤
필드 너비를 데이터 길이에 맞춰 자동 조정할 수 있습니다. 필드를 선택한 후 팝업 메뉴에서 맞춤을 클릭하거나 Shift+F를 누세요. 가장 긴 값 기준으로 열 폭이 설정됩니다.
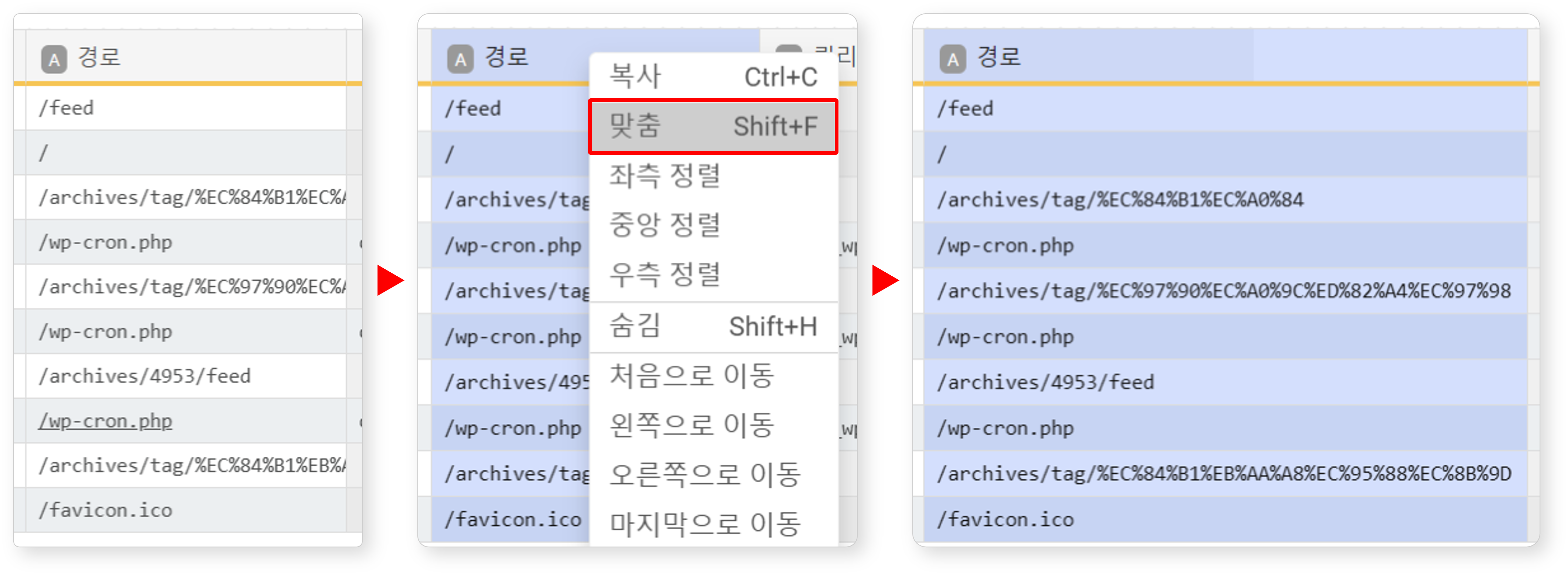
분석 도구
복사
필드를 선택한 후 팝업 메뉴에서 복사를 클릭하거나 Ctrl+C를 누르면, 해당 열의 표시된 데이터를 TSV 형식(탭으로 구분된 텍스트)으로 클립보드에 복사할 수 있습니다.
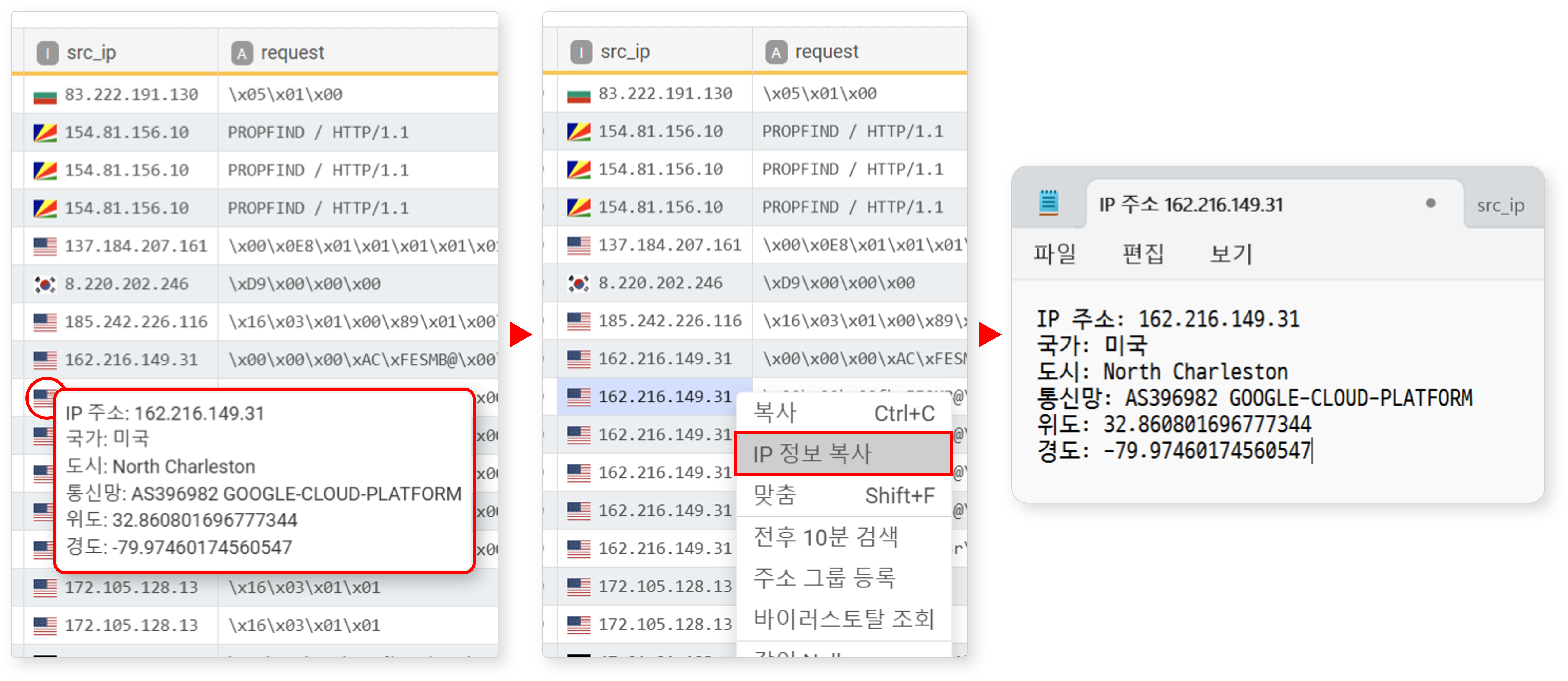
IP 정보 복사
IP 주소 필드에서 IP 주소 옆에 표시된 국기 아이콘 위에 커서를 올리면 해당 주소의 위치 정보(국가, 도시, 통신망, 위도, 경도)가 표시됩니다. 팝업 메뉴에서 IP 정보 복사를 클릭하면 해당 위치 정보를 클립보드에 복사할 수 있습니다.
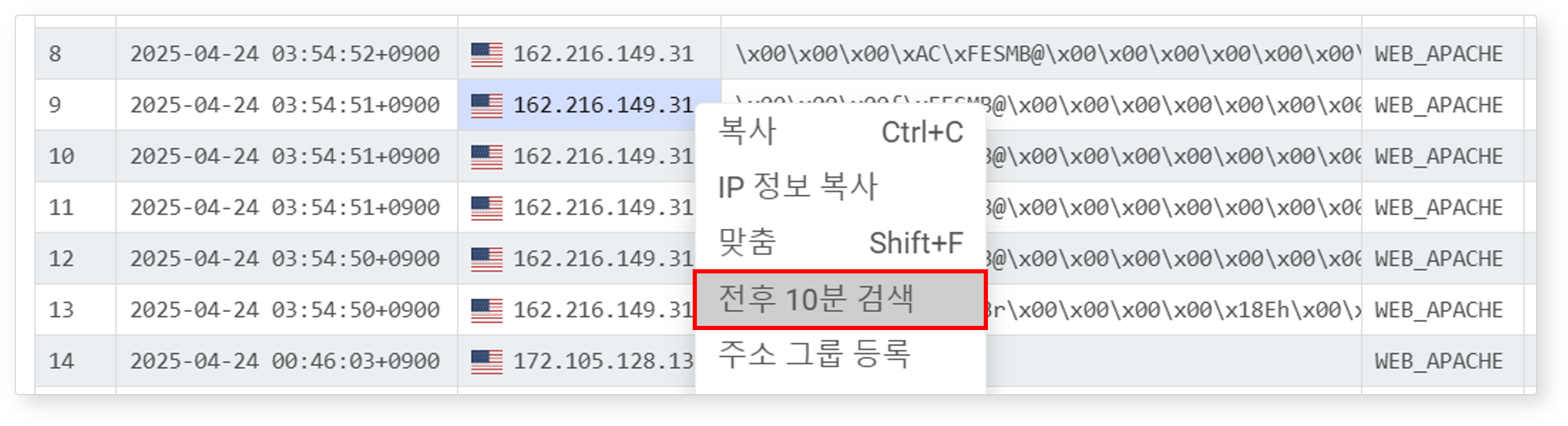
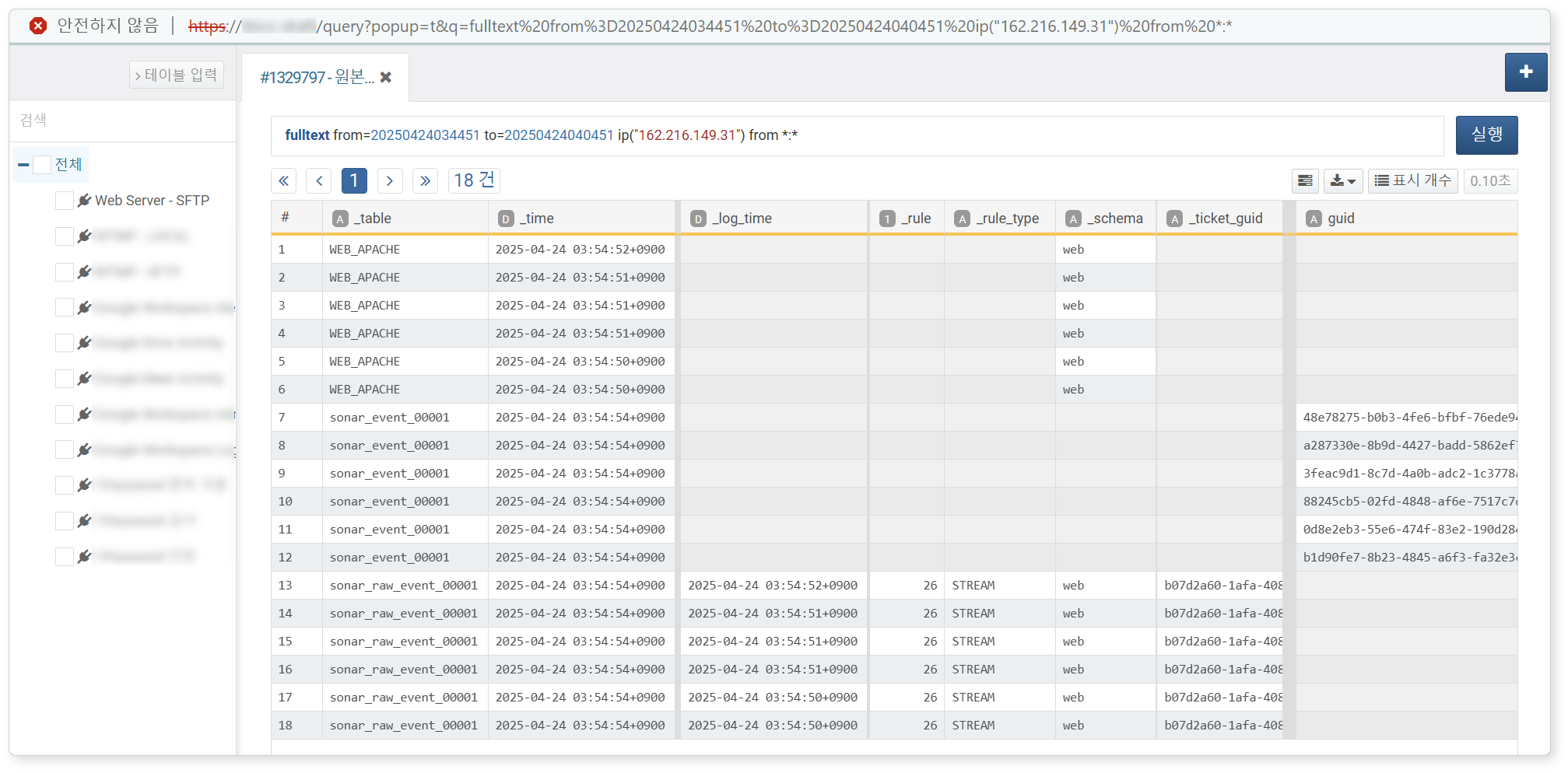
전후 10분 검색
IP 주소 필드에서 셀을 선택한 후 팝업 메뉴에서 전후 10분 검색을 클릭하면, 해당 이벤트 시각 기준 앞뒤 10분 내에 동일 IP가 포함된 데이터를 조회합니다. 결과는 팝업 창으로 표시되며, 이벤트의 전후 맥락 파악에 유용합니다.
아래는 실행 결과 예시입니다(관련 명령어: fulltext).
주소 그룹 등록
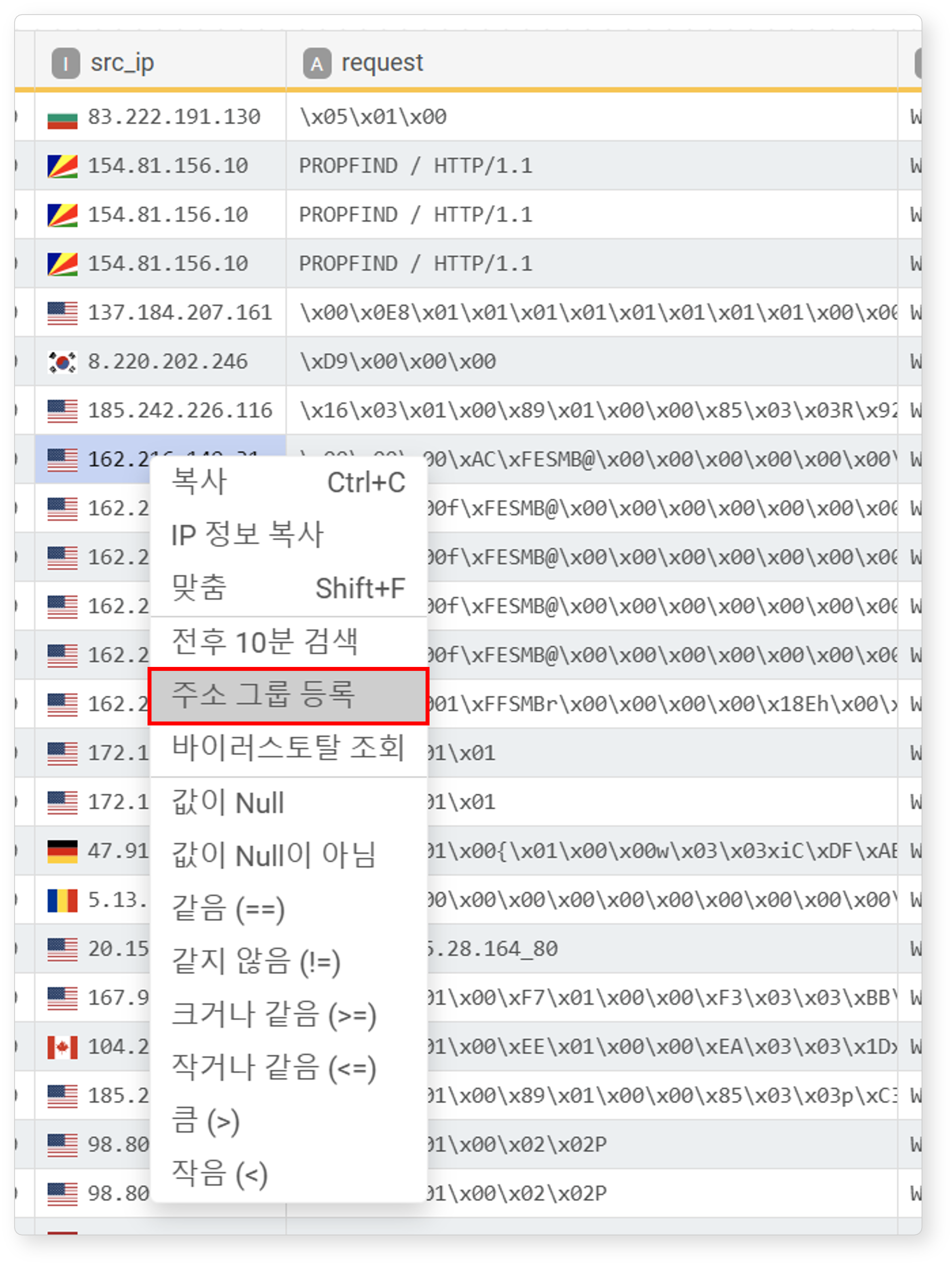
IP 주소 필드에서 선택한 IP 값을 주소 그룹에 등록할 수 있습니다. 이 기능은 반복적으로 나타나는 악성 IP 등을 그룹화하여 관리하거나 필터링할 때 유용합니다.
-
IP 주소 셀을 선택한 후 팝업 메뉴에서 주소 그룹 등록을 클릭하세요.
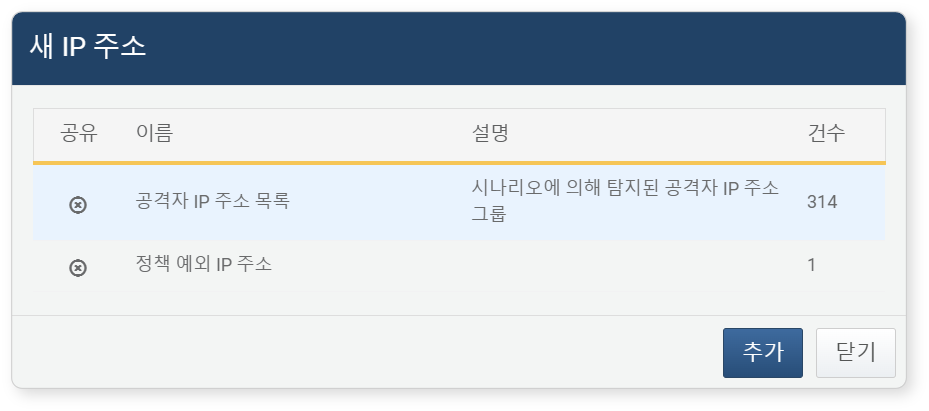
-
새 IP 주소 창에서 등록할 주소 그룹을 선택한 후 추가 버튼을 클릭하세요.
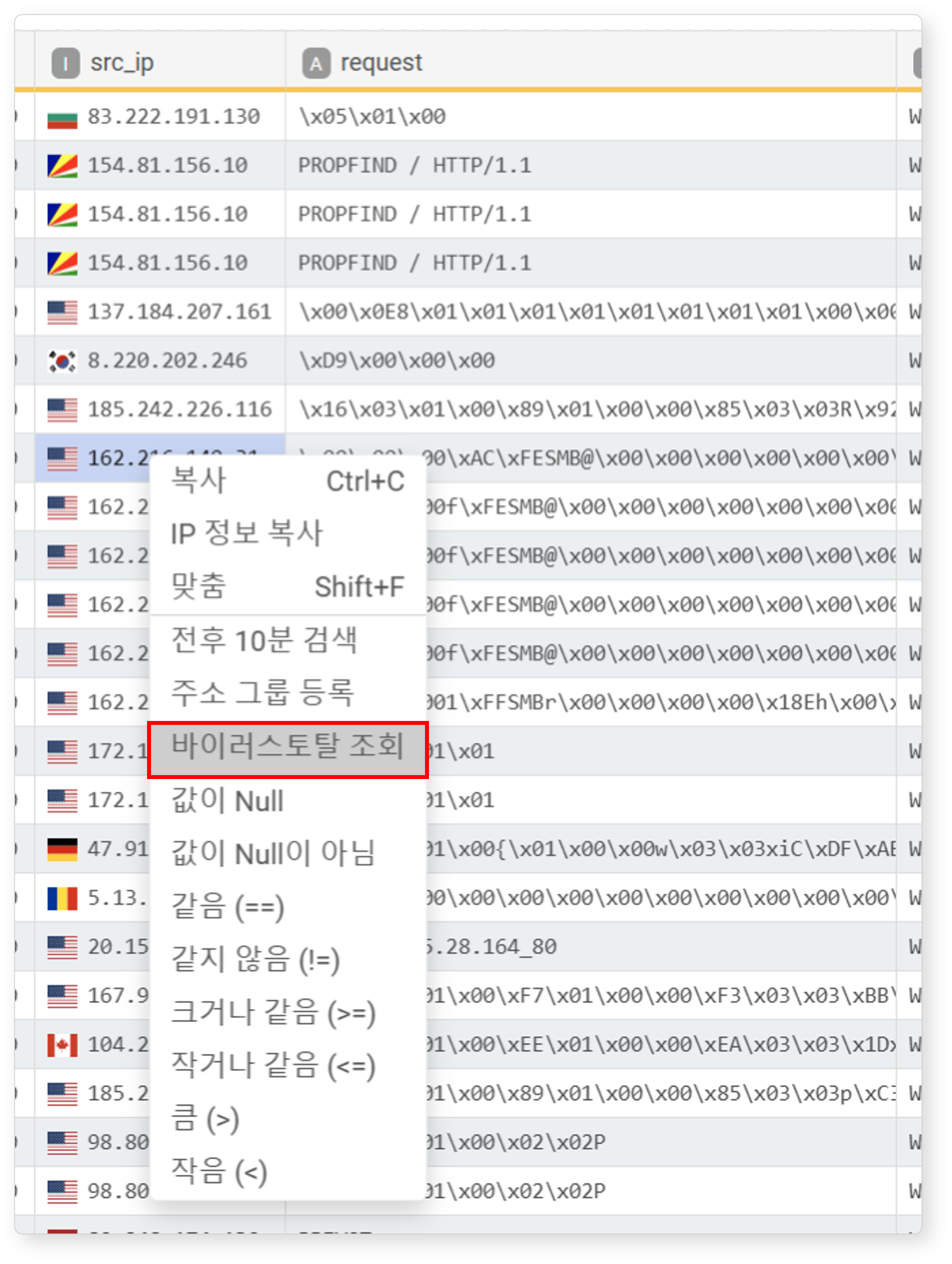
바이러스토탈 조회
IP 주소 필드에서 셀을 선택한 후 팝업 메뉴에서 바이러스토탈 조회를 클릭하면, 새 창에서 VirusTotal가 제공하는 해당 IP 주소에 대한 진단 정보를 확인할 수 있습니다. 이 기능은 의심스러운 IP에 대한 신속한 대응에 활용할 수 있습니다.
아래는 실행 결과 예시입니다.
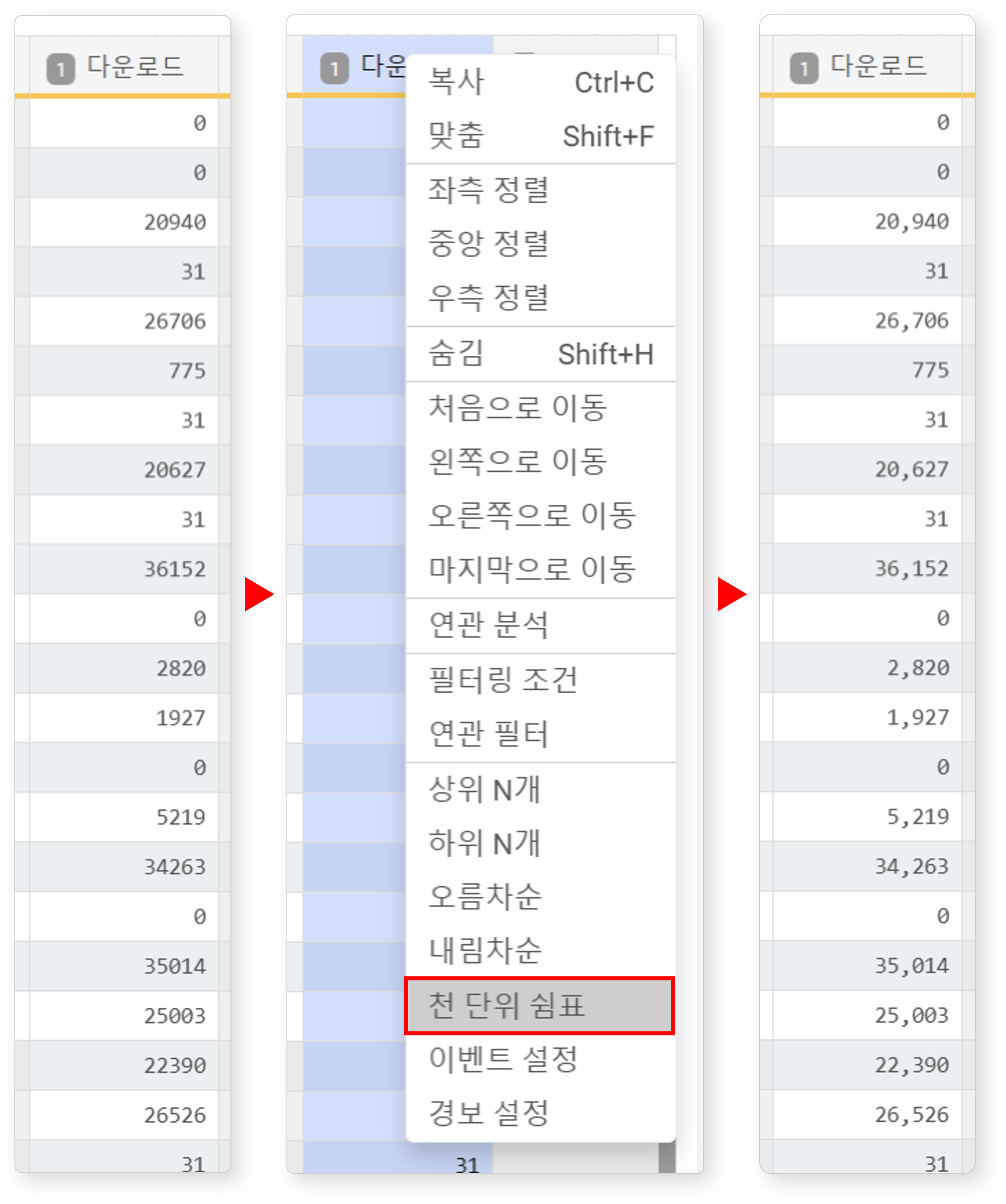
천 단위 쉼표
숫자형 필드(정수, 실수)를 선택한 후 팝업 메뉴에서 천 단위 쉼표를 클릭하면, 숫자 값에 천 단위 구분 기호(쉼표)를 적용할 수 있습니다. 이 기능은 큰 수치를 직관적으로 파악해야 할 때 유용합니다.
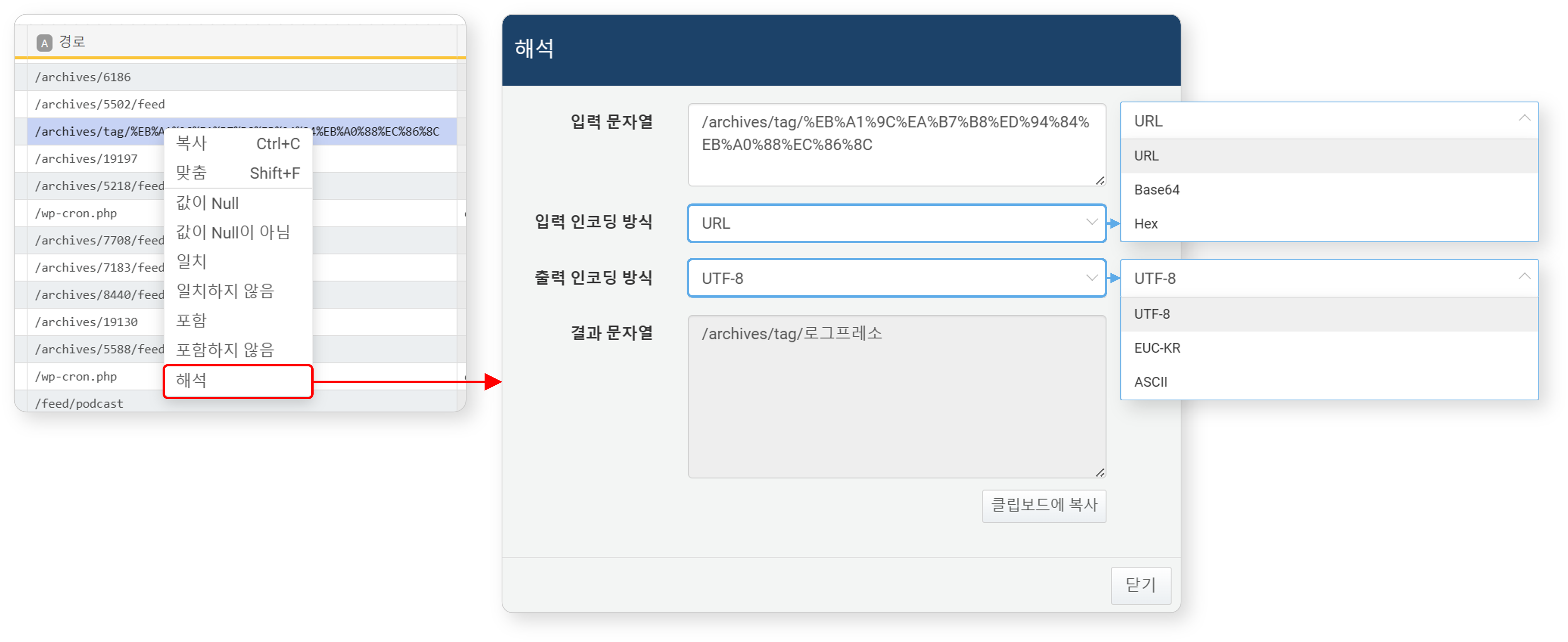
해석
문자열 필드에서 셀을 선택한 후 팝업 메뉴에서 해석을 클릭하면 해당 문자열의 디코딩값을 확인할 수 있습니다.
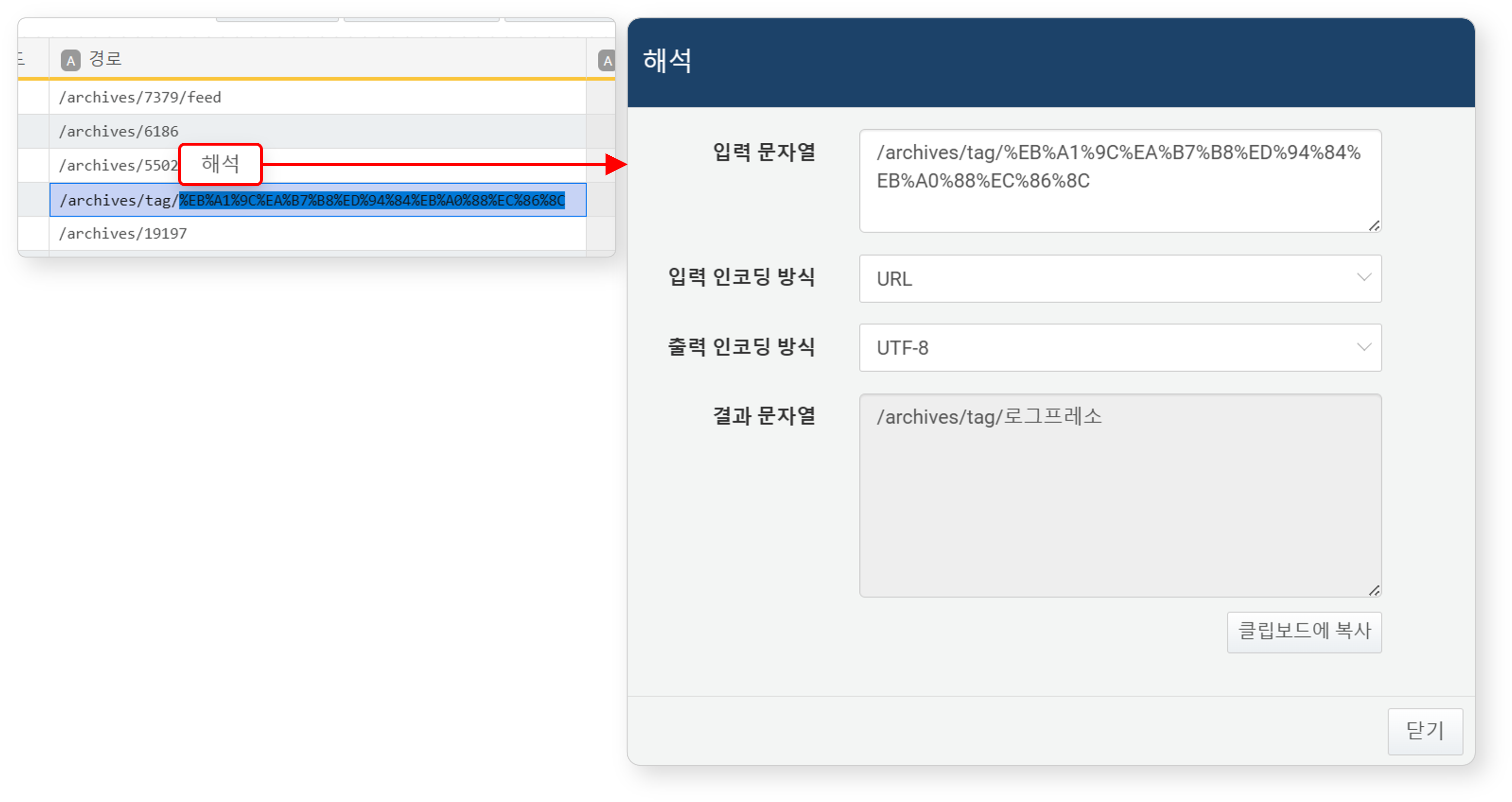
셀 내에서 문자열 일부를 드래그로 선택한 후, 마찬가지로 해석을 클릭하면 해당 부분만 디코딩할 수 있습니다.
사용자 정의 변수
사용자 정의 변수는 입력 컨트롤 위젯을 통해 사용자가 입력한 값을 기반으로, 대시보드 위젯의 표시 결과를 동적으로 제어하는 데 사용됩니다. 예를 들어 날짜, 시간, IP 주소 등 사용자의 입력값에 따라 위젯 내 분석 결과를 달리 표시할 수 있습니다.
이 변수는 피벗 기반 대시보드에서 동적 필터와 시간 단위 절사 설정 시 지정할 수 있습니다.
변수 목록 조회
- 대시보드 화면에서 조회
-
대시보드에서 사용자 정의 변수 메뉴 버튼을 클릭하면 새 창에서 사용자 정의 변수 목록을 확인할 수 있습니다.
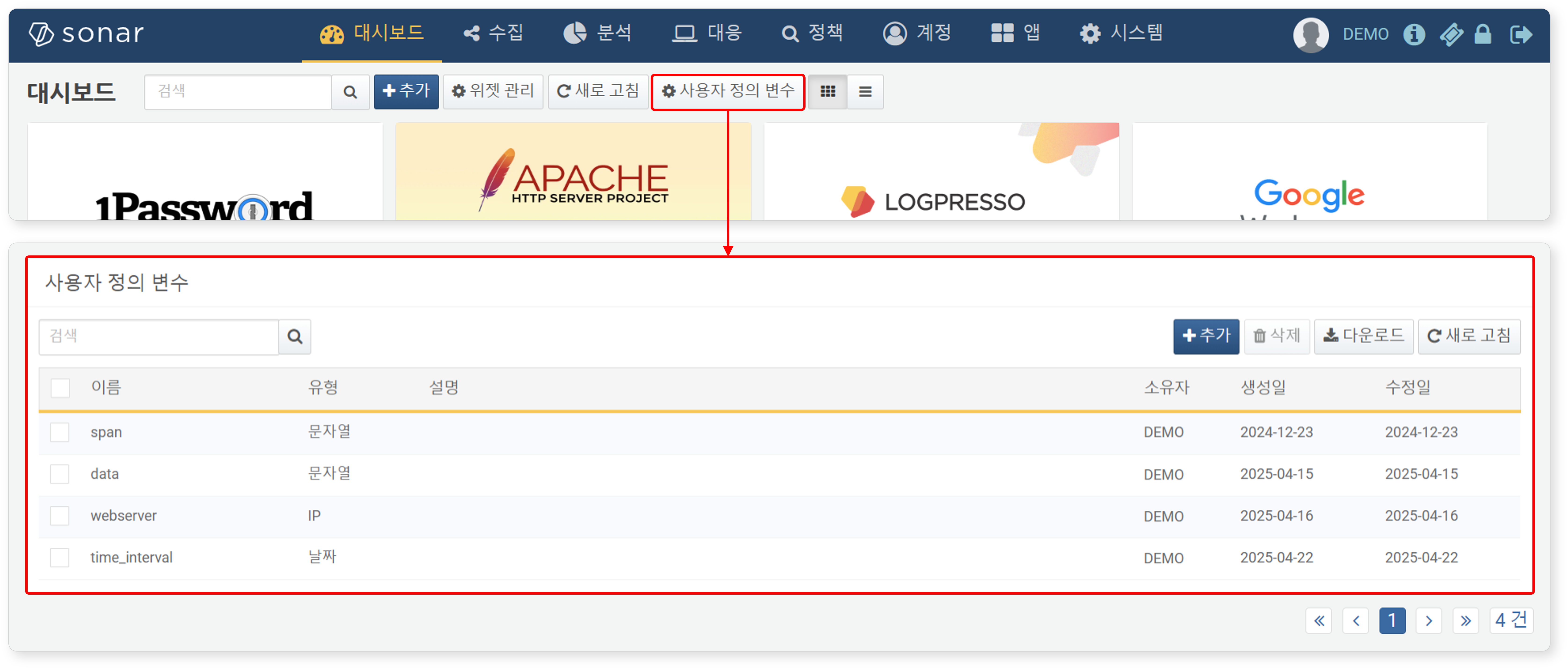
- 피벗 화면에서 조회
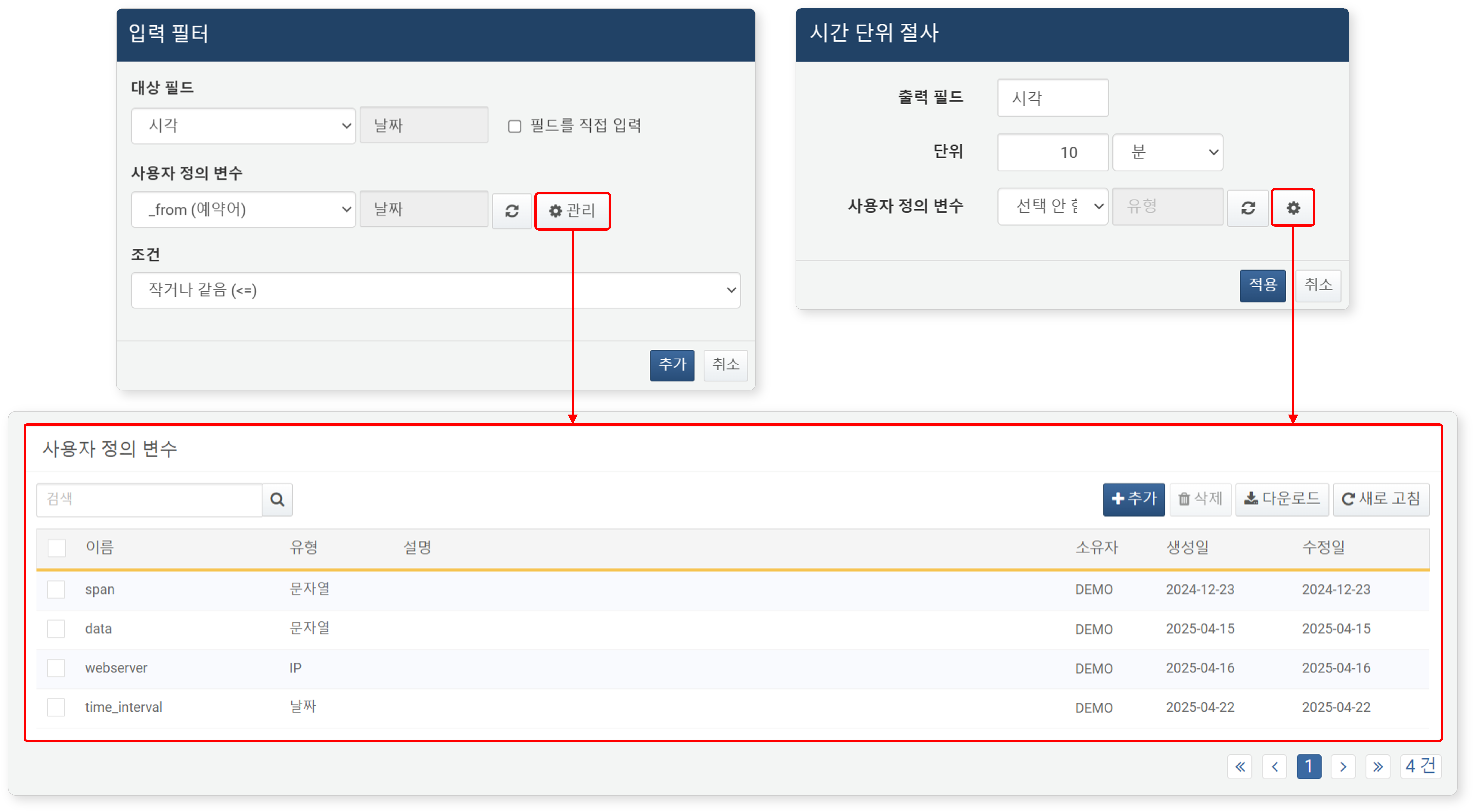
-
피벗 화면에서 동적 필터 또는 시간 단위 절사 수식을 설정할 때
아이콘을 클릭하면 새 창에서 사용자 정의 변수 목록을 확인할 수 있습니다.
목록에서 특정 사용자 정의 변수를 찾으려면 검색창을 사용하세요. 검색은 이름 기준으로 동작하며, 대소문자를 구분합니다.
변수 추가
-
변수 목록 조회 화면에서 추가 버튼을 클릭하세요.
-
사용자 정의 변수 추가 화면에서 사용자 정의 변수의 속성을 입력한 다음 확인 버튼을 클릭하세요.
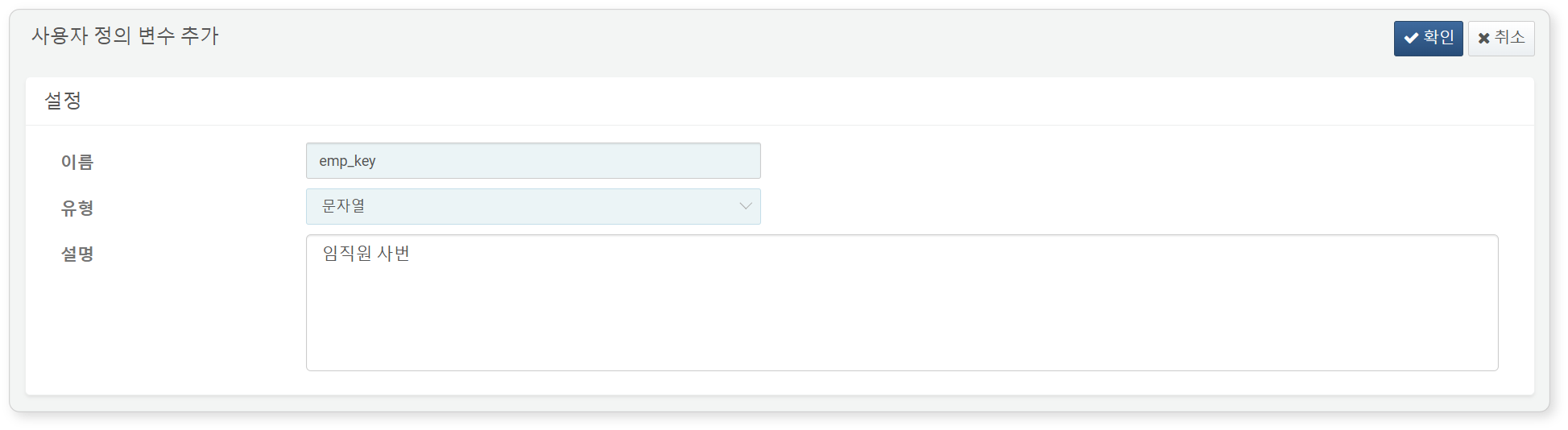
- 이름: 변수의 고유 이름을 입력하세요(최대 50자)
- 유형: 입력받을 값의 데이터 유형을 지정하세요. 기본값은 문자열입니다.
- 설명: 변수에 대 세부 설명을 입력하세요(최대 2,000자).
변수 수정
- 변수 목록 조회 화면에서 수정할 변수의 이름을 클릭하세요.
- 수정 화면에서 정보를 수정한 후 확인 버튼을 클릭하세요. 변수의 이름은 수정할 수 없습니다.
변수 삭제
- 변수 목록 조회 화면에서 삭제할 변수의 체크박스를 선택하세요.
- 도구 모음에서 삭제 버튼을 클릭하세요.
- 사용자 정의 변수 삭제 대화상자에서 목록을 확인한 후 삭제 버튼을 클릭하세요.
데이터 분석
이 섹션에서는 피벗 테이블을 구성하여 항목 간 관계를 요약하고 데이터를 집계하거나, 다른 데이터와의 연관 분석을 통해 의미 있는 정보로 변환하는 방법을 설명합니다.
데이터 분석과 가공은 논리적으로 구분할 수 있지만, 실제로는 하나의 과정에서 함께 수행됩니다.
피벗 테이블
피벗 테이블은 필드 목록을 드래그 앤 드롭하여 데이터를 시각적으로 재구성하고 분석할 수 있는 도구입니다. MS Excel의 피벗 테이블과 유사한 방식으로 작동하며, 대량의 데이터를 효율적으로 집계하고 주요 패턴이나 통계를 빠르게 도출하는 데 유용합니다.
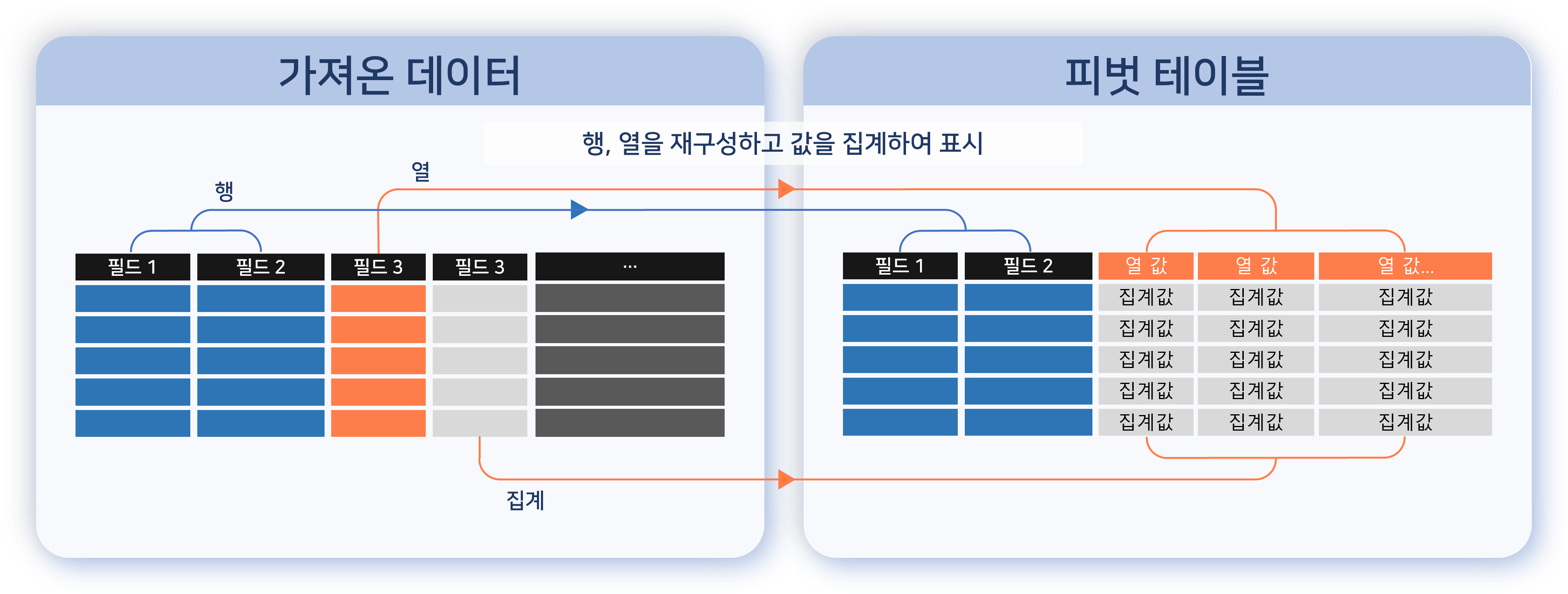
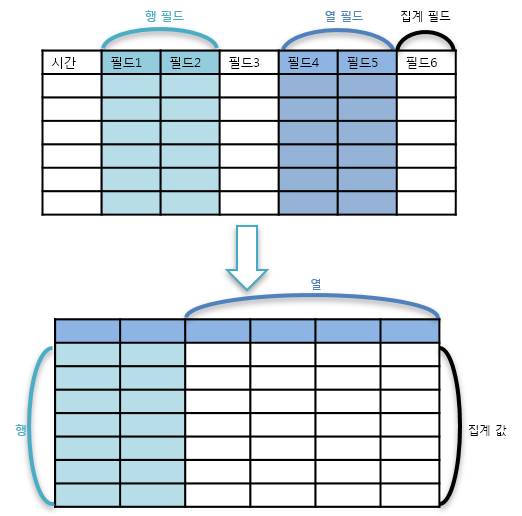
행렬
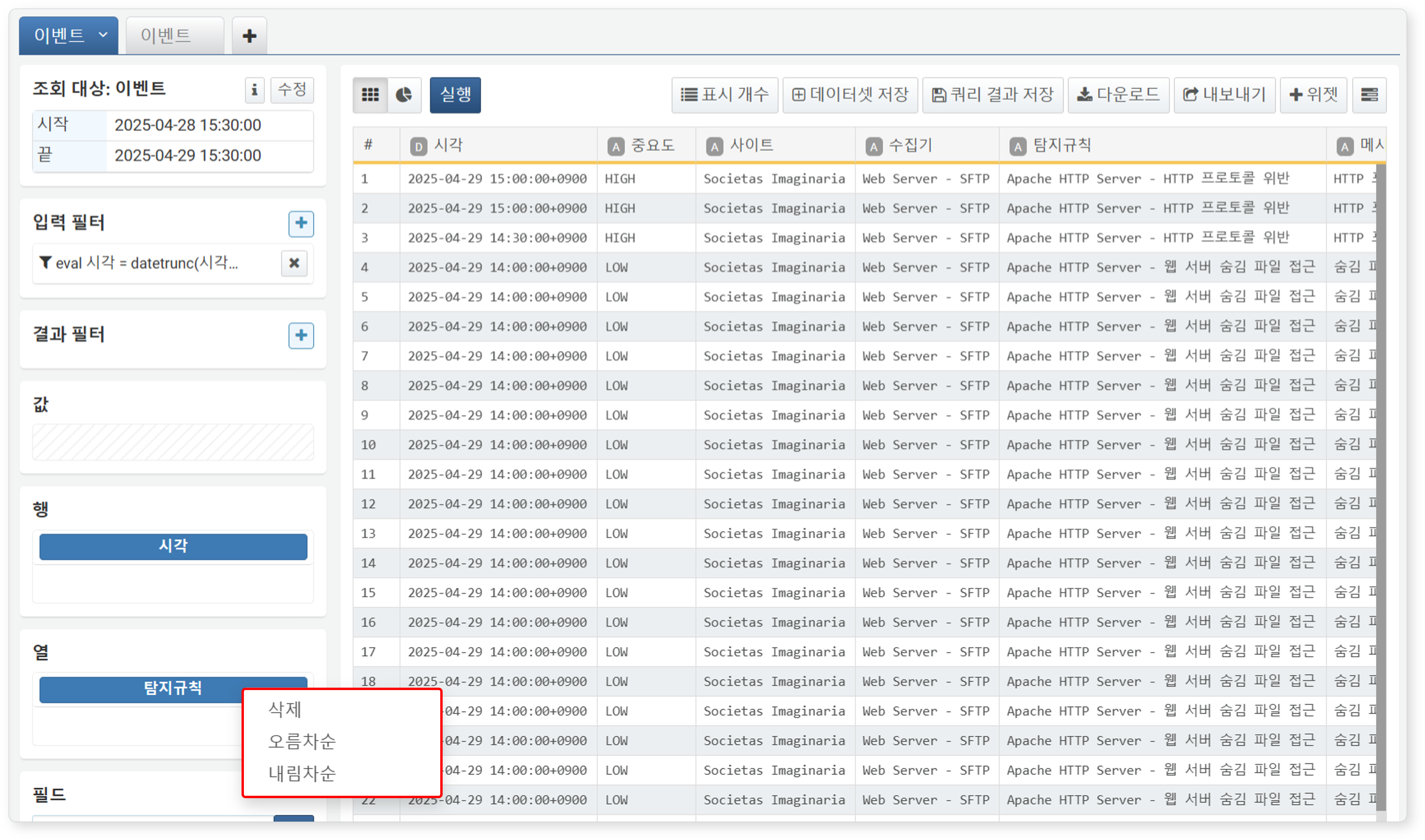
피벗 테이블을 구성하려면 먼저 분석에 사용할 행과 열 필드를 지정해야 합니다. 일반적으로 키 필드 또는 분류 기준이 되는 필드를 차원으로 설정합니다. 왼쪽 하단의 필드 목록에서 원하는 필드를 선택해 행 또는 열 영역으로 드래그하면 피벗 테이블이 자동으로 생성됩니다.
-
행: 분석 기준 필드를 지정하세요. 각 행 필드 값의 조합이 레코드를 구성합니다.
-
열: 분석 대상 필드를 지정하세요. 각 열 필드의 고유값을 기준으로 열이 생성됩니다. 중복 값은 1개의 값으로 간주되어 1개의 열로 변환됩니다. 열 필드의 고유값은 최대 1,000개까지만 지원되며, 이를 초과하면 피벗 테이블을 생성할 수 없습니다.
-
행 또는 열 영역에 추가된 필드를 클릭하면 팝업 메뉴가 표시되며, 정렬 또는 필드 제거 등의 작업을 수행할 수 있습니다.
집계 값/함수
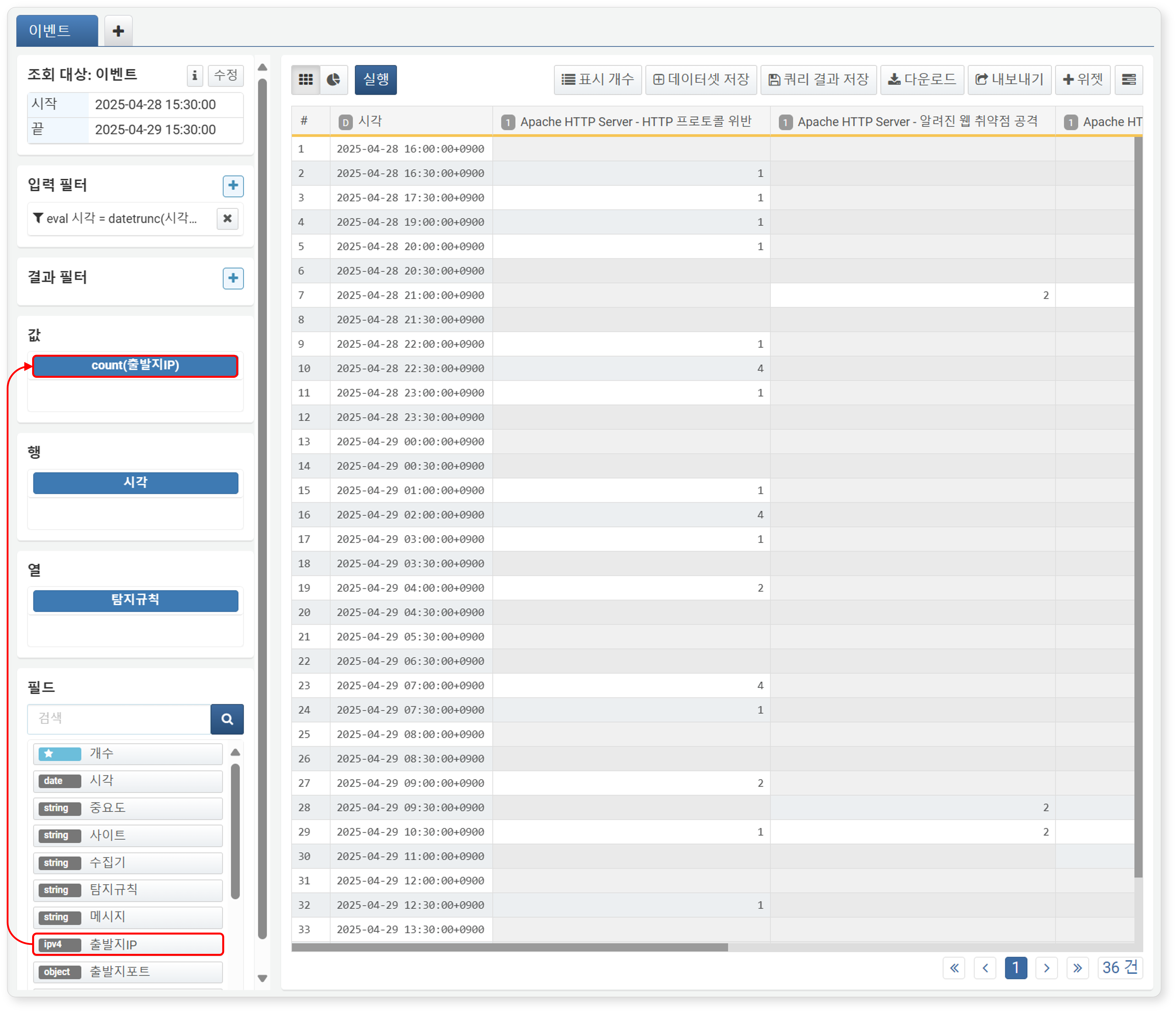
피벗 테이블에서 행과 열을 설정한 뒤, 집계할 필드를 값 영역으로 드래그하세요. 주로 집계 함수를 적용할 수 있는 필드를 사용하며, 기본적으로 count() 함수가 자동 적용됩니다.
행 필드 기준으로 열 필드가 포함된 레코드 수를 집계하려면, 필드 목록 상단의 개수 항목을 값 영역으로 드래그하세요.
-
값: 집계 연산 대상 필드
-
개수: 행과 열의 조합별로 레코드 개수를 집계하려면 개수 필드를 값 영역에 추가하세요.
-
값 영역에 추가된 필드를 클릭하면 집계 함수를 변경할 수 있는 팝업이 나타납니다. 원하는 함수를 선택하고 수정 버튼을 클릭하면 적용됩니다.
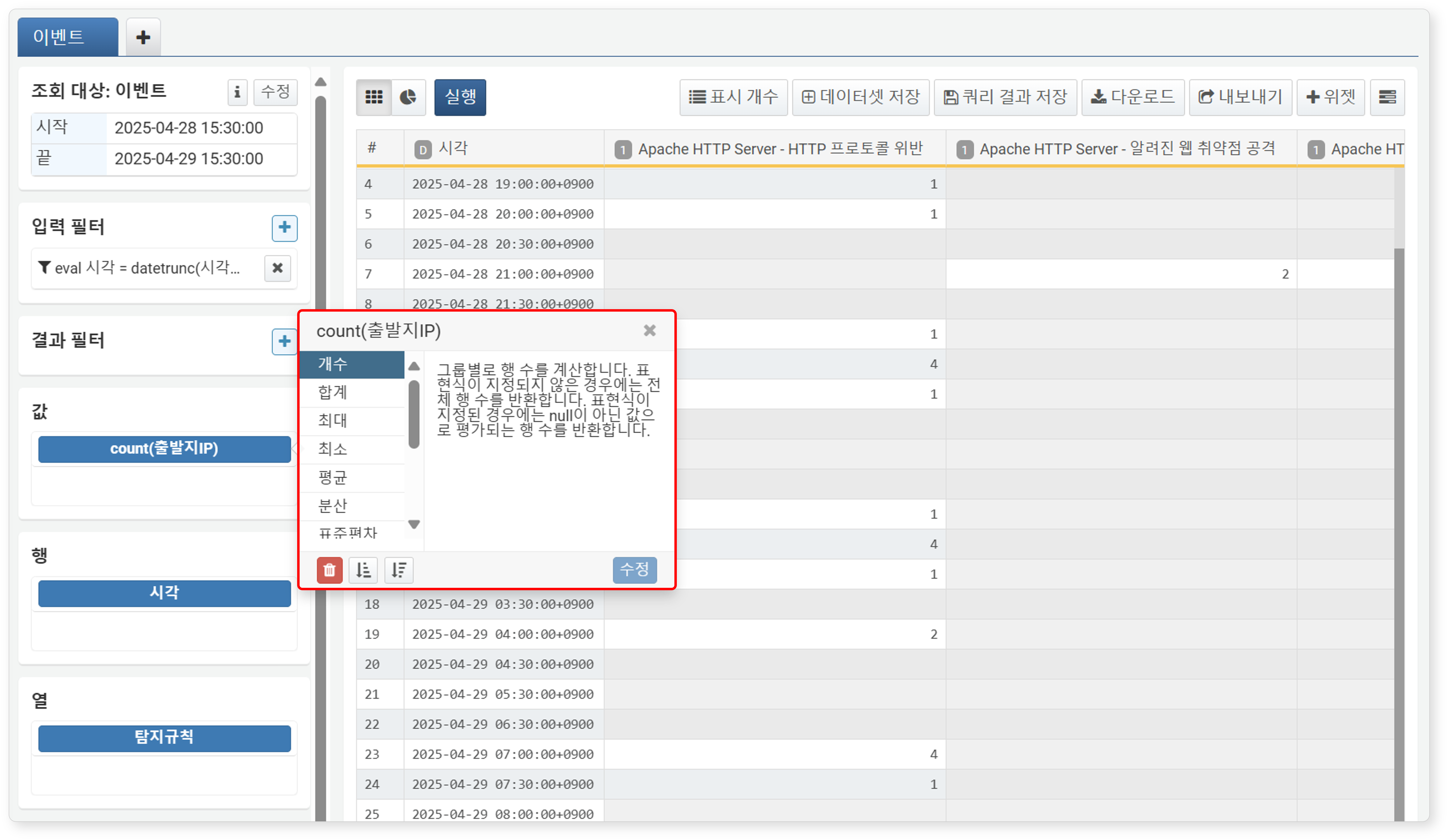
지원하는 집계 함수는 다음과 같습니다.
- 개수(count()): 그룹별 행 개수를 계산. 표현식이 없으면 전체 행 수, 표현식이 있으면 null이 아닌 값의 수를 반환
- 합계(sum()): 그룹 내 숫자형 표현식의 총합 계산.
null이거나 숫자(short,int,long,float,double)가 아닌 표현식은 무시. - 최대(max()): 그룹 내 최댓값 계산. null인 표현식은 무시.
- 최소(min()): 그룹 내 최솟값 계산. null인 표현식은 무시.
- 평균(avg()): 그룹 내 숫자형 표현식의 평균 계산.
null이거나 숫자(short,int,long,float,double)가 아닌 표현식은 무시. - 분산(var()): 그룹 내 숫자형 표현식의 분산 계산,
null이거나 숫자(short,int,long,float,double)가 아닌 표현식은 무시. - 표준편차(stddev()): 그룹 내 숫자형 표현식의 표준편차 계산
null이거나 숫자(short,int,long,float,double)가 아닌 표현식은 무시. - 첫번째 값(first()): 그룹 내 첫 번째 값 반환.
- 마지막 값(last()): 그룹 내 마지막 값 반환.
- 유일한 값(values()): 중복 제거된 고유값 배열 반환(최대 100개).
- 유일개수(dc()): 고유값의 개수 계산.
- 추정유일개수(estdc()): 고유값 개수를 추정 계산.
연관 분석
여러 보안 장비에서 수집된 데이터를 통합한 뒤, join 또는 union 명령을 이용해 데이터 테이블 간 연산을 수행하면, 보안 이벤트 간의 연관 관계를 분석할 수 있습니다. 이를 통해 서로 다른 로그 간의 관계를 식별하고, 위협 요소나 이상 징후를 효과적으로 탐지할 수 있습니다.
연관 분석은 정제된 데이터를 결합하고 필터링하는 과정을 포함하며, 복잡한 데이터를 신속하게 해석하고, 보안 대응의 정확성과 효율성을 높이는 데 유용합니다.
연관 유형
연관 분석은 데이터 간 관계를 분석하기 위해 두 데이터 테이블을 결합하는 방식에 따라 아래 6가지 유형을 제공합니다.
- Union
- 두 데이터 집합(각 피벗 탭의 테이블)에 포함된 모든 레코드를 결합하여 출력합니다. 레코드는 원형 그대로 유지되며, 연관 필드 일치 여부와 관계없이 전체 레코드를 포함합니다. 단, 레코드의 순서는 보장되지 않습니다.

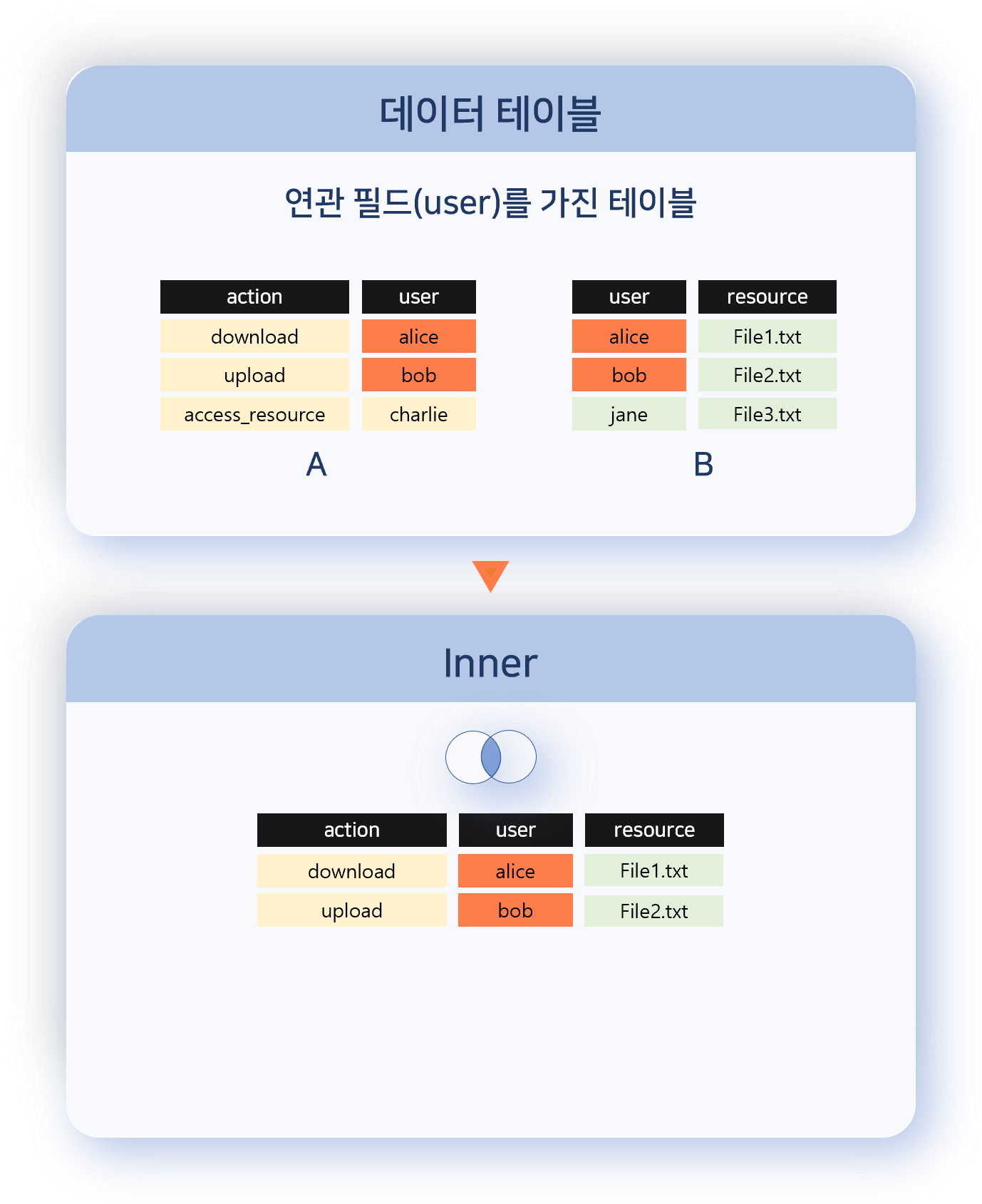
- Inner
- 양쪽 데이터 집합에서 연관 필드 값이 일치하는 레코드만 결합하여 출력합니다. 공통된 데이터만 분석 대상으로 사용할 경우 유용합니다.
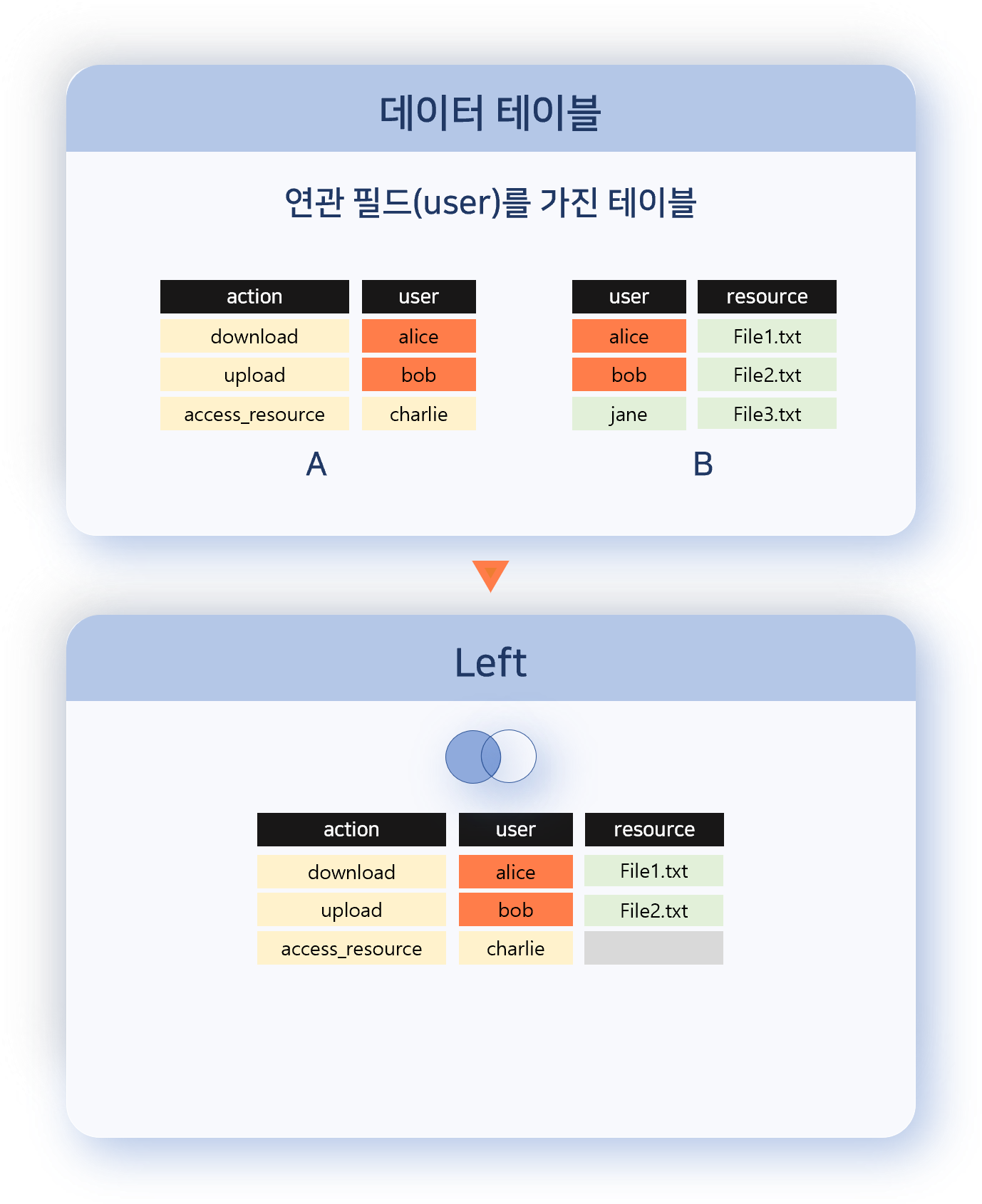
- Left
- 왼쪽 데이터 집합의 모든 레코드를 유지하면서, 오른쪽에서 연관 필드 값이 일치하는 레코드가 있을 경우 결합합니다.
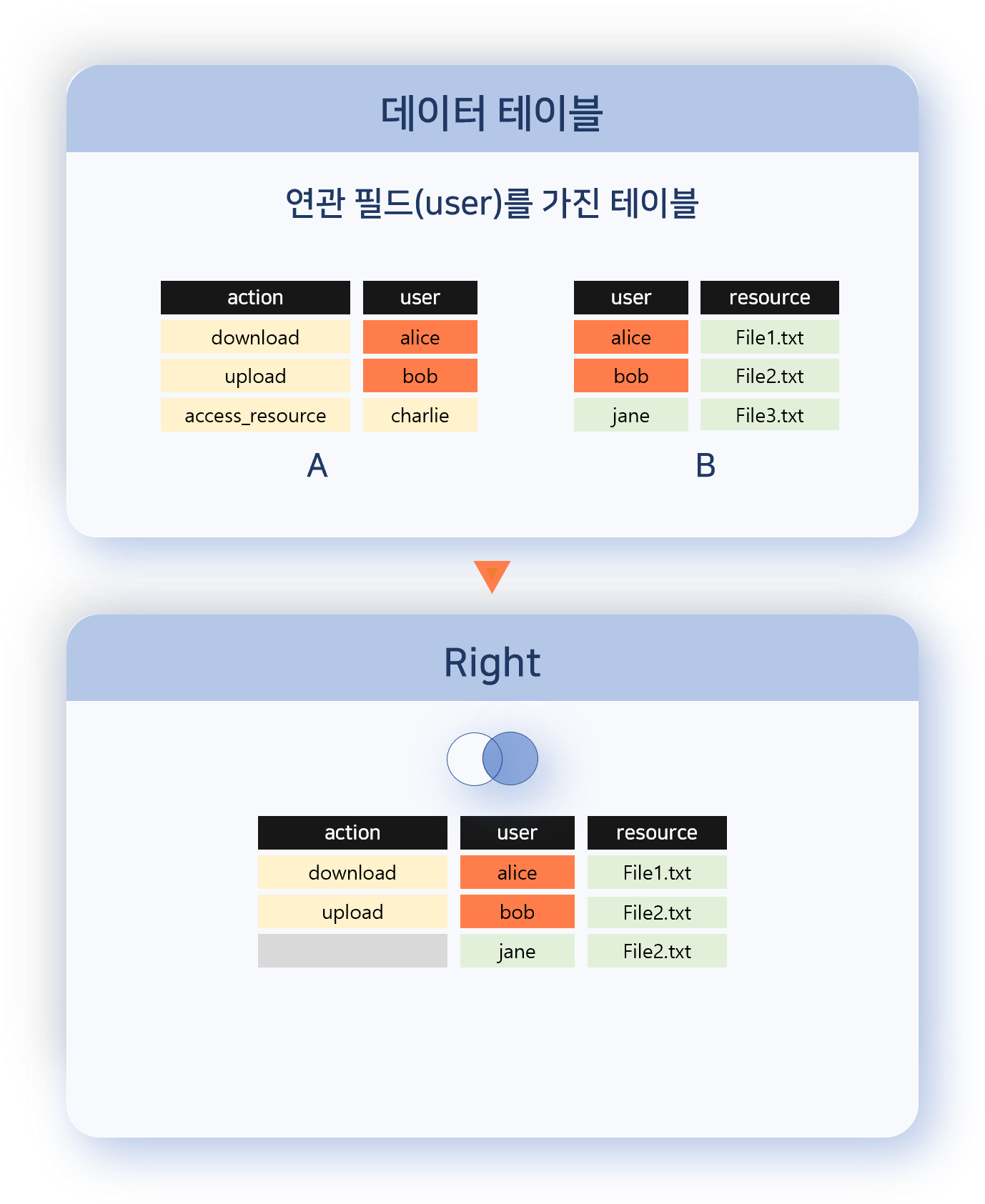
- Right
- 오른쪽 데이터 집합의 모든 레코드를 유지하며, 왼쪽에서 연관 필드 값이 일치하는 레코드가 있을 경우 결합합니다.
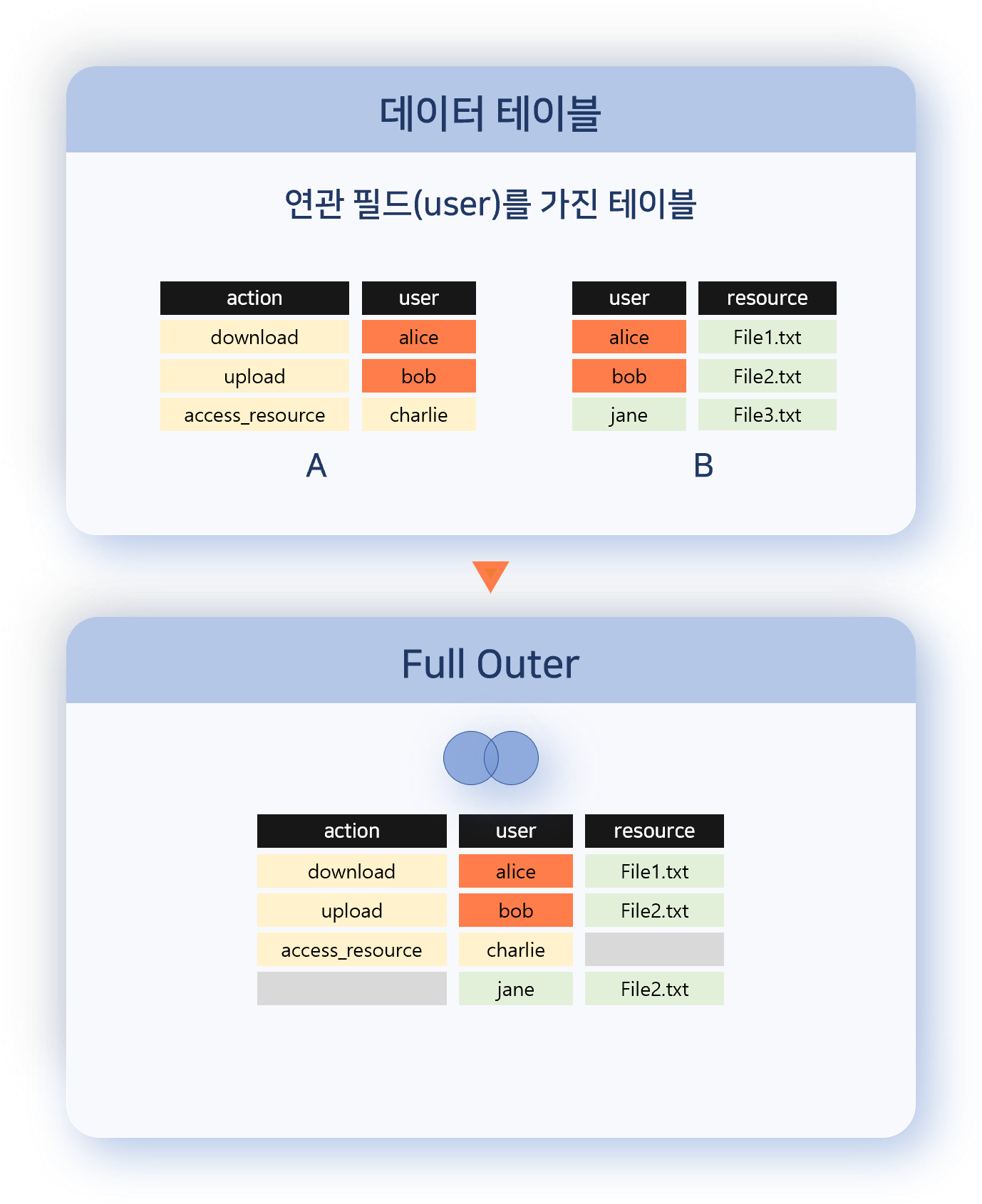
- Full Outer
- 양쪽 데이터 집합의 모든 레코드를 출력합니다.
- 연관 필드가 일치하는 경우: 데이터를 결합해 출력
- 일치하지 않는 경우: 각 데이터 집합의 레코드를 그대로 출력
- Left Only
- 왼쪽 데이터 집합 중에서 오른쪽과 연관 필드 값이 일치하지 않는 레코드만 출력합니다. Inner 유형과 반대 개념이며, 누락되거나 단독 발생한 항목 분석에 유용합니다.

분석 수행
아래에서는 공격자 IP 주소가 포함된 주소 그룹과 웹 서버 로그를 연관 분석하여, 웹 서버를 대상으로 발생한 공격 현황을 확인하는 방법을 설명합니다.
- 데이터 준비
-
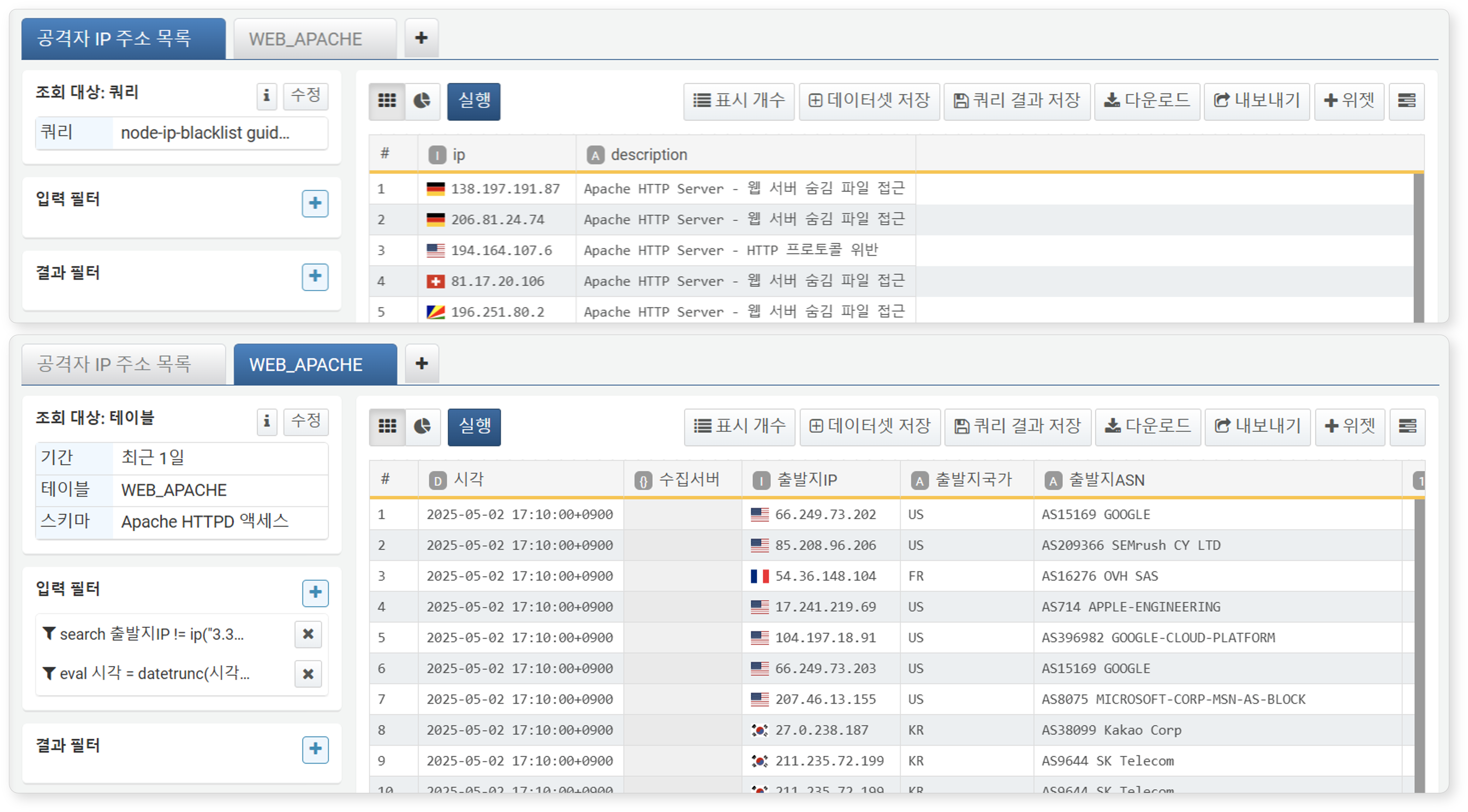
연관 분석을 수행하려면 2개 이상의 데이터 그룹이 필요합니다. 피벗 탭을 2개 이상 열고, 각각 분석할 데이터를 적재하고 필요한 형태로 가공하세요. 탭 이름을 명확하게 설정하면 작업 중 데이터 그룹을 쉽게 식별할 수 있습니다.
-
아래는 공격자 IP 주소 목록 탭과 WEB_APACHE 탭에 각각 데이터를 조회한 예시입니다.
연관 조건 지정
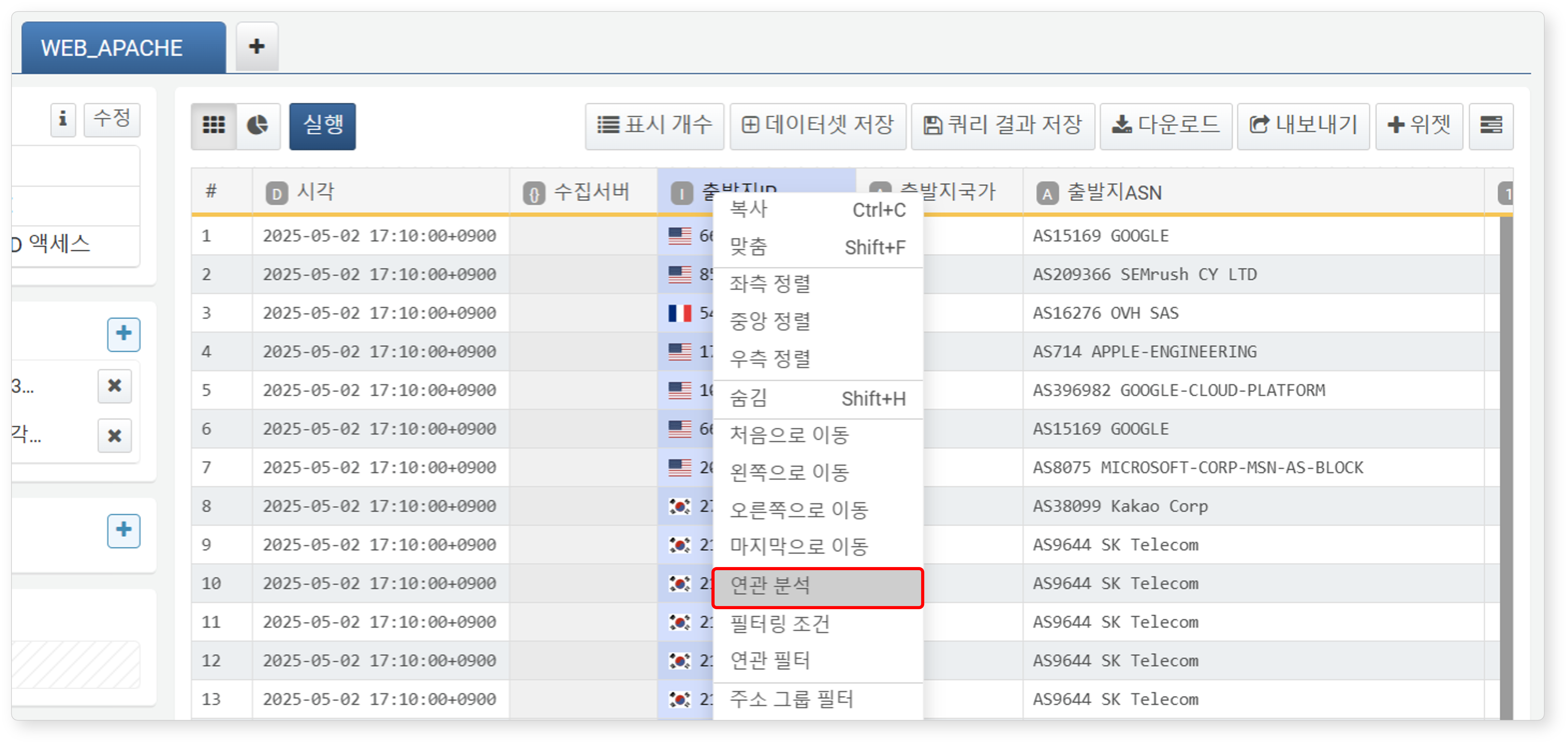
-
연관 기준이 될 필드(예: WEB_APACHE 탭의 출발지IP)를 선택한 후, 팝업 메뉴에서 연관 분석을 클릭하세요.
-
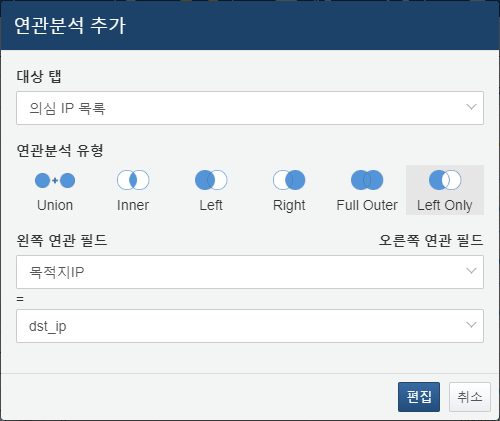
연관 분석 추가 대화상자에서 다음 항목을 설정한 뒤 확인 버튼을 클릭하세요.
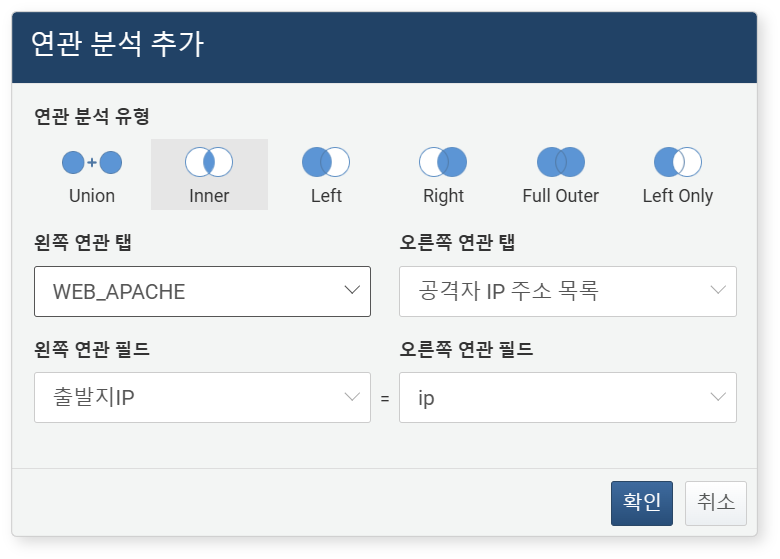
- 연관 분석 유형: Union, Inner, Left, Right, Full Outer, Left Only 중에서 선택하세요. 예시에서는 Inner를 선택했습니다.
- 왼쪽 연관 탭: 왼쪽 데이터 그룹으로 지정할 피벗 탭을 선택하세요.
- 왼쪽 연관 탭: 오른쪽 데이터 그룹으로 지정할 피벗 탭을 선택하세요.
- 왼쪽 연관 필드: (유형이 Union인 경우는 제외) 두 데이터 집합 간 비교에 사용할 필드를 지정하세요.
- 오른쪽 연관 필드: (유형이 Union인 경우는 제외) 두 데이터 집합 간 비교에 사용할 필드를 지정하세요.
- 피벗 테이블 구성
-
연관 조건을 적용하면 연관 분석 결과가 표시됩니다.
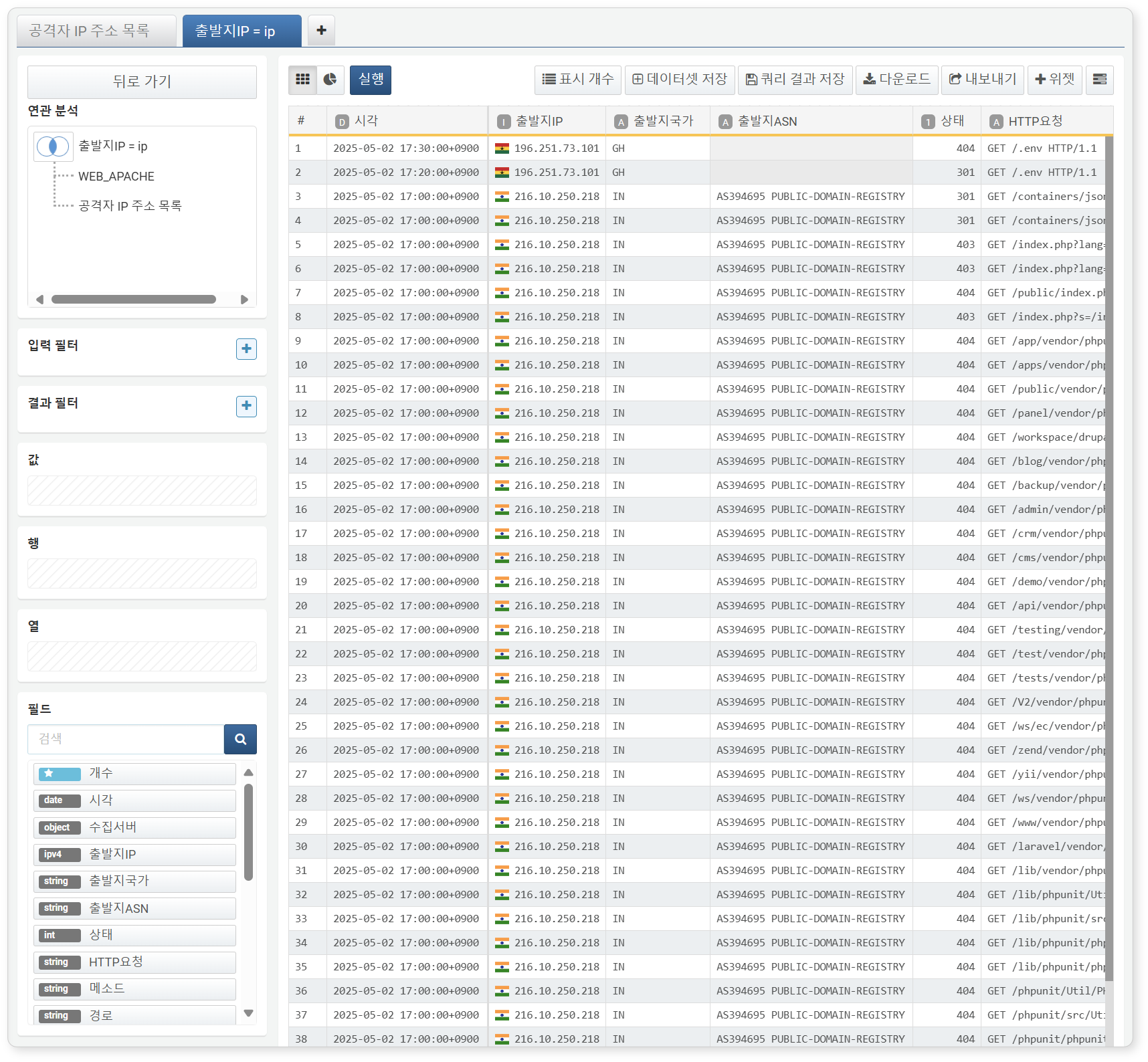
-
결과 화면에서도 일반 피벗 테이블과 동일하게 행/열/값을 지정하여 분석할 수 있습니다.
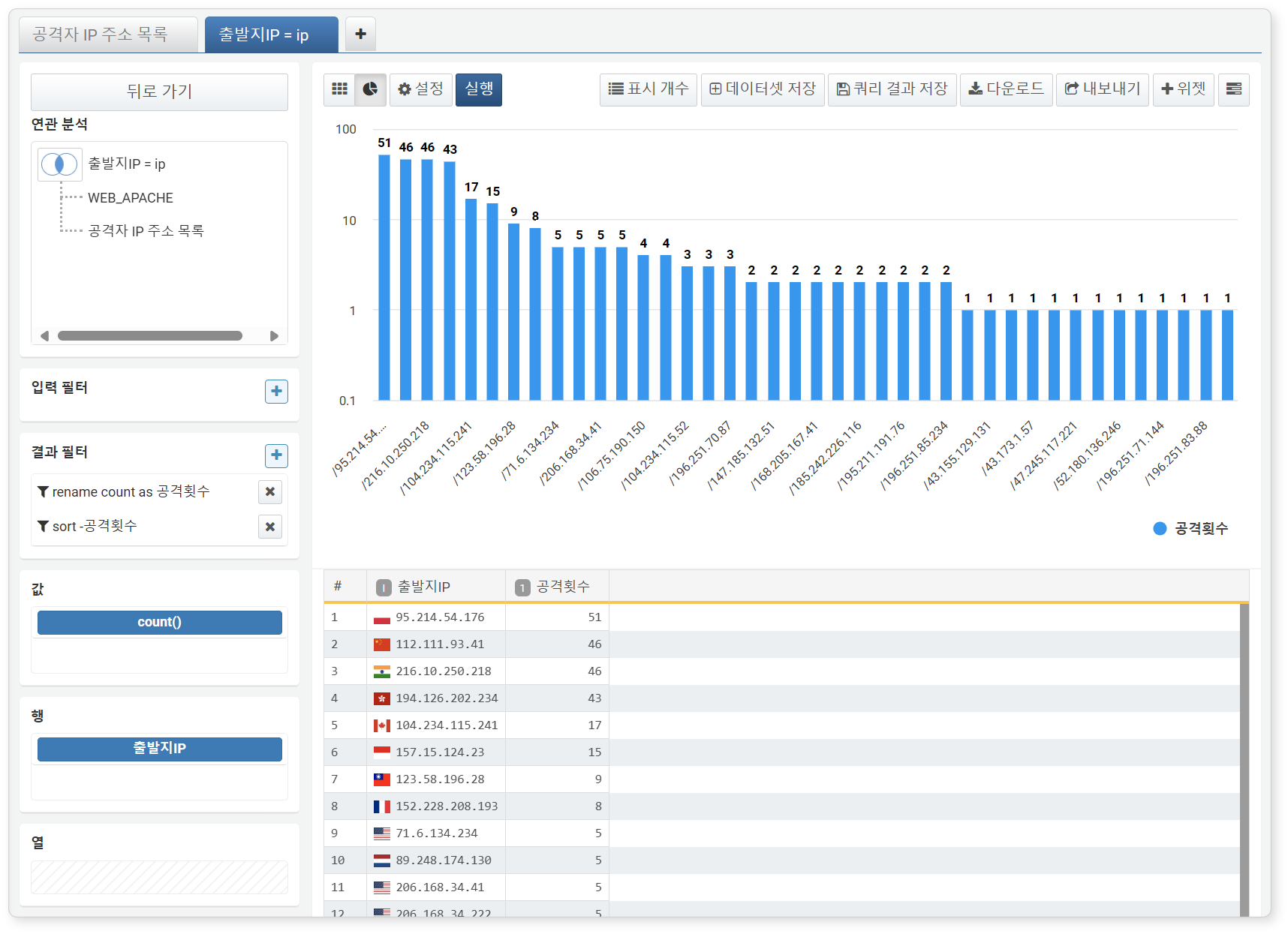
-
예시에서는 공격자 IP 주소를 행으로, 웹 서버 로그의 개수를 값으로 설정해 IP 주소별 공격 횟수를 집계했습니다.
- 행: 공격자 IP 주소
- 열: 미지정
- 값: 웹 서버 로그의 개수
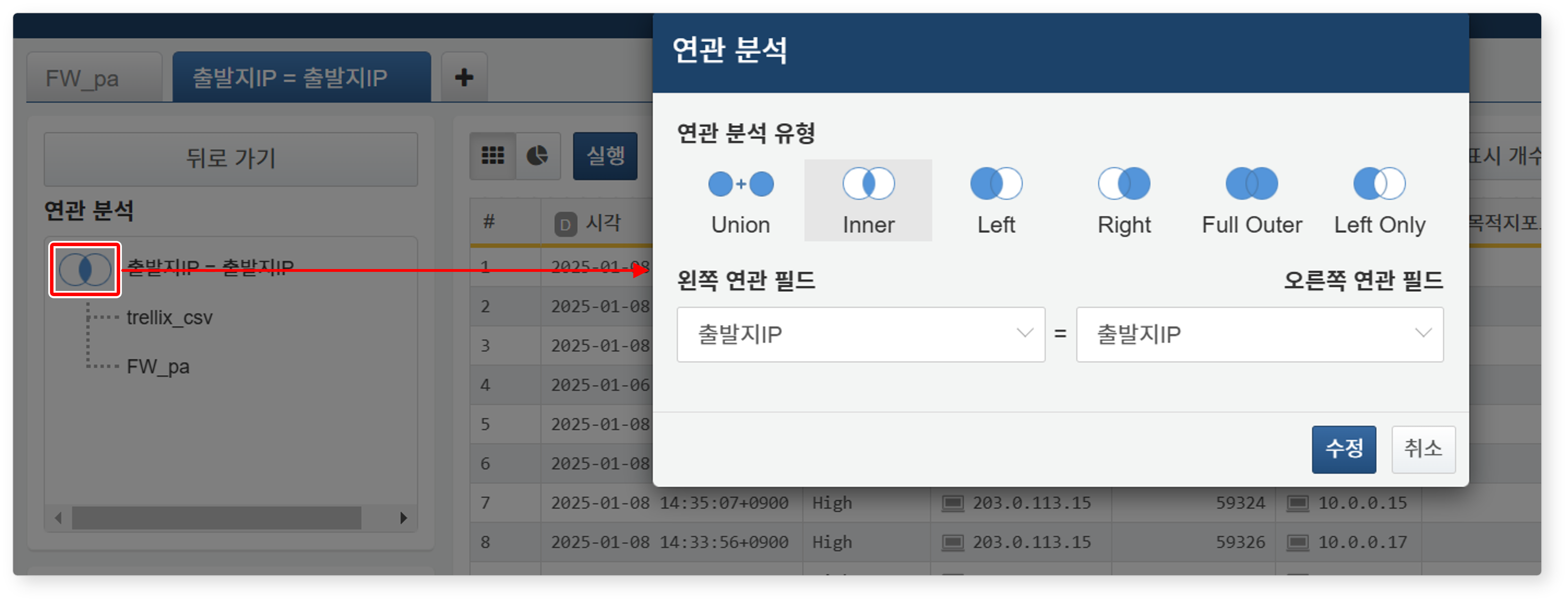
- 연관 조건 변경
-
화면 왼쪽의 연관 분석 유형 아이콘(다이어그램 아이콘)을 클릭하면 연관 조건 및 필드를 변경할 수 있습니다.
- 기타 작업
-
연관 분석 트리에서 탭 또는 연관 분석 이름을 보조 클릭하면 다음 작업을 수행할 수 있습니다.
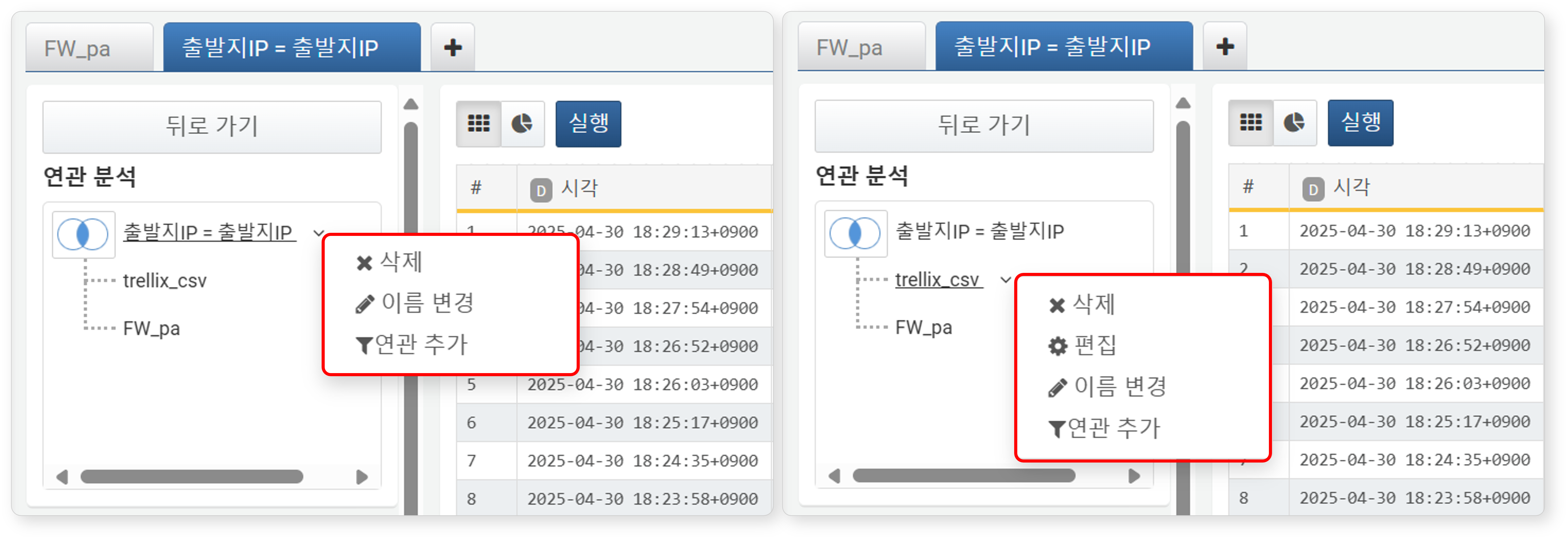
- 삭제
-
선택한 연관 분석을 또는 데이터 그룹을 삭제할 수 있습니다. - 연관 분석을 삭제하면 연관 분석이 종료됩니다. - 특정 데이터 그룹(탭) 삭제 시 해당 데이터 그룹만 분석에서 제거됩니다.
- 편집
-
연관 분석에 사용된 데이터 그룹을 재구성하려면 편집을 클릭하세요. - 편집을 클릭하면 해당 데이터 그룹의 편집 화면으로 이동합니다. - 조회 조건, 필터, 집계 방식 등을 재설정할 수 있습니다. - 편집 후 뒤로 가기 버튼을 클릭하면 연관 분석 화면으로 복귀합니다.
- 이름 변경
-
연관 분석 또는 데이터 탭의 이름을 변경할 수 있습니다. 연관 분석 또는 데이터 탭의 팝업 메뉴에서 이름 변경을 클릭하세요. 이름 변경 대화 상자에서 새로운 이름을 입력하고 수정 버튼을 클릭하면 변경 사항이 즉시 적용됩니다.
- 연관 추가
-
기존 연관 분석에 추가 연관 조건을 설정할 수 있습니다. 열 제목 또는 연관 분석 이름을 클릭한 후 팝업 메뉴에서 연관 추가를 클릭하세요. 연관 분석 추가 대화 상자에서 연관 분석 대상 탭, 연관 분석 유형, 연관 필드를 설정해 새로운 연관 분석을 구성하세요.
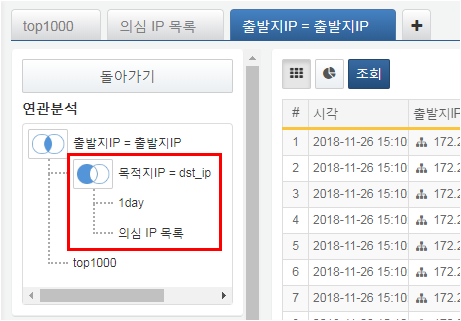
-
추가된 연관 분석은 다음과 같이 화면에 표시됩니다.
- 연관 분석 종료
-
연관 분석 화면에서 뒤로 가기를 클릭하거나 팝업 메뉴에서 삭제를 클릭하면 연관 분석이 종료됩니다. 종료 시 설정된 필터 및 집계 필드는 초기화되며, 원래의 피벗 화면으로 복귀합니다.
분석 결과 활용
피벗에서 분석한 결과는 다양한 방식으로 재활용할 수 있습니다. 예를 들어, 분석 결과를 대시보드 위젯으로 추가해 실시간 모니터링에 활용하거나, 다른 분석의 기반 데이터로 저장하여 반복적인 분석 작업을 효율화할 수 있습니다.
분석 결과를 활용하는 방법은 다음과 같습니다:
- 분석 결과를 데이터셋으로 저장해 여러 대시보드 위젯에서 공통된 기초 데이터로 사용
- 현재의 분석 결과를 쿼리 위젯 형태로 변환하여 대시보드에 추가
- 분석 결과를 CSV 또는 TSV 등의 파일 형식으로 내보내 다른 시스템 또는 외부 분석 도구에서 활용
- 다른 로그프레소 소나 시스템에서 활용할 수 있도록 피벗 파일로 내보내기
- 분석 시점의 결과만 저장하여 이후 분석 과정에서 기준 데이터로 활용
데이터셋
피벗 분석 결과를 데이터셋으로 저장하면, 대시보드 위젯이나 반복 분석의 기초 데이터로 활용할 수 있습니다.
-
데이터셋으로 저장하기에 적합한 형태로 데이터를 구성하세요.
-
데이터 구성이 완료되면, 도구 모음에서 데이터셋 저장 버튼을 클릭하세요.
-
데이터셋 추가 대화상자에서 저장할 데이터셋의 이름(최대 50자)과 설명(최대 2,000자)을 입력한 뒤, 추가 버튼을 클릭하세요.
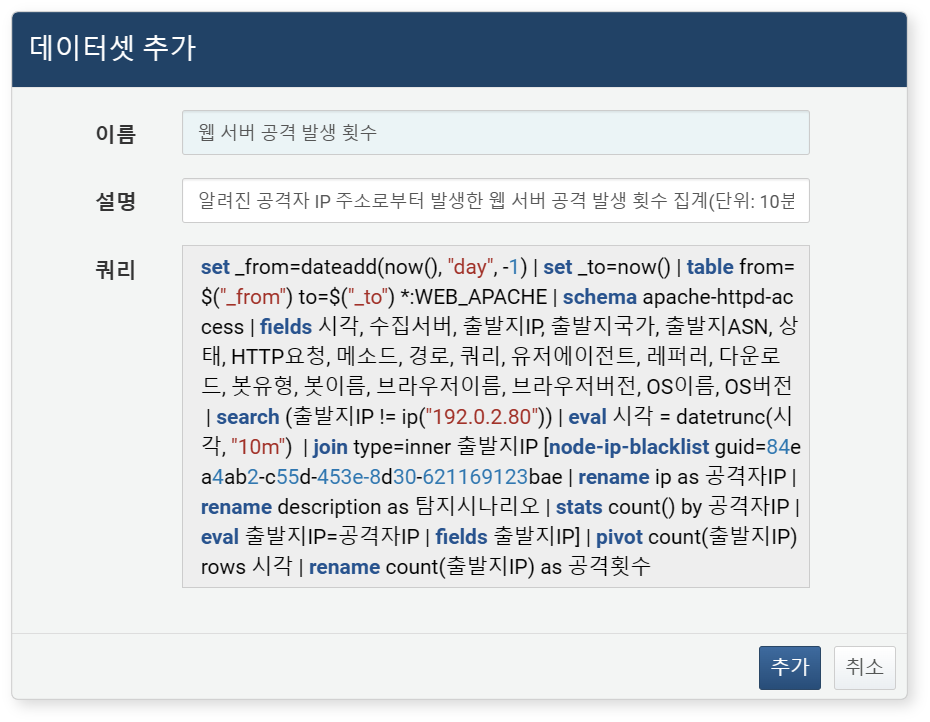
-
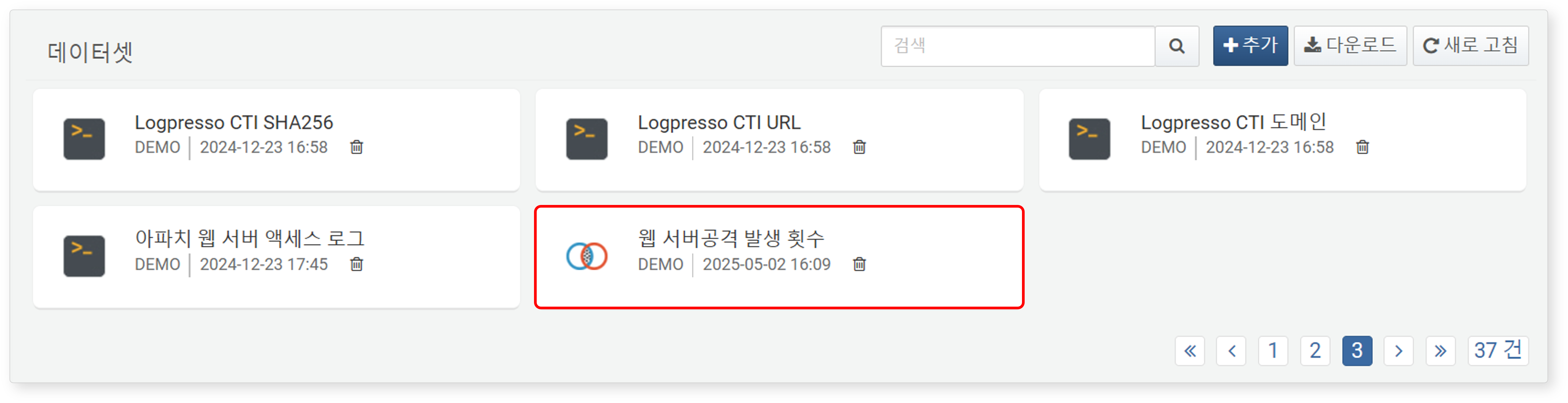
저장된 데이터셋은 분석 > 데이터셋에서 확인할 수 있습니다.
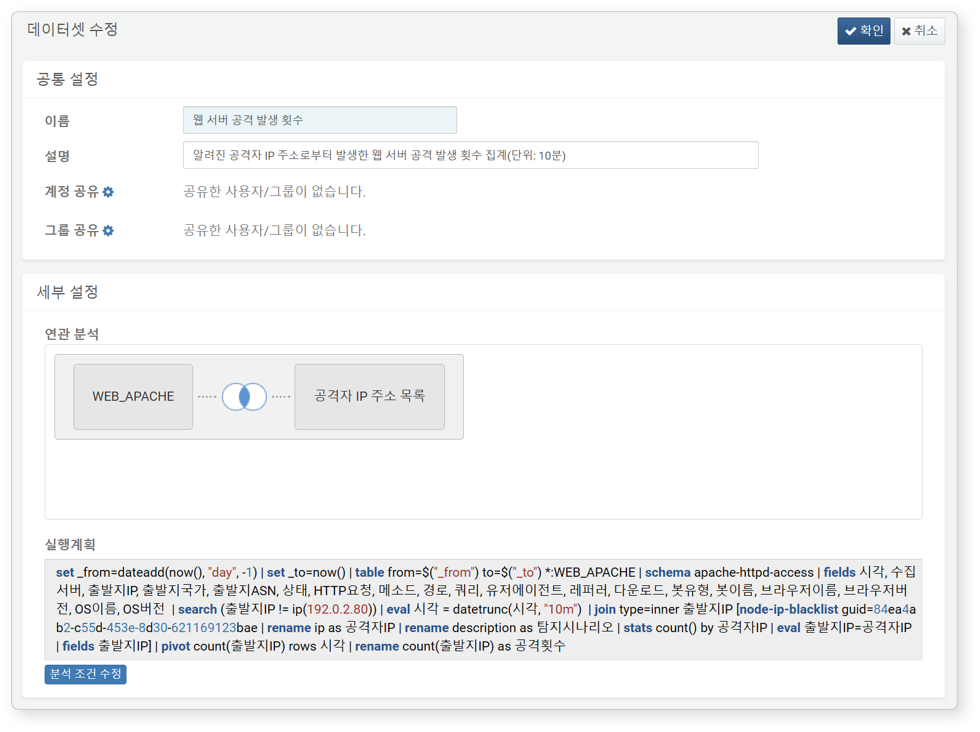
데이터셋 카드를 클릭하면 데이터셋 세부 내용을 확인하거나 수정할 수 있습니다.
위젯
위젯은 대시보드에서 데이터를 시각적으로 표현하는 구성 요소로, 차트나 그리드 형태로 분석 결과를 표시할 수 있습니다. 피벗 테이블에서 구성한 데이터를 위젯으로 전환하면 실시간 모니터링에 활용할 수 있습니다.
그리드
그리드 위젯은 분석한 데이터를 표 형태로 시각화해 실시간으로 모니터링할 수 있는 위젯입니다.
-
데이터를 불러온 뒤 그리드에 적합한 형태로 가공하세요.
-
셀을 클릭했을 때 필터 적용, 쿼리 실행, 브라우저 열기 등과 같은 동작을 수행하려면 이벤트를 설정해야 합니다.
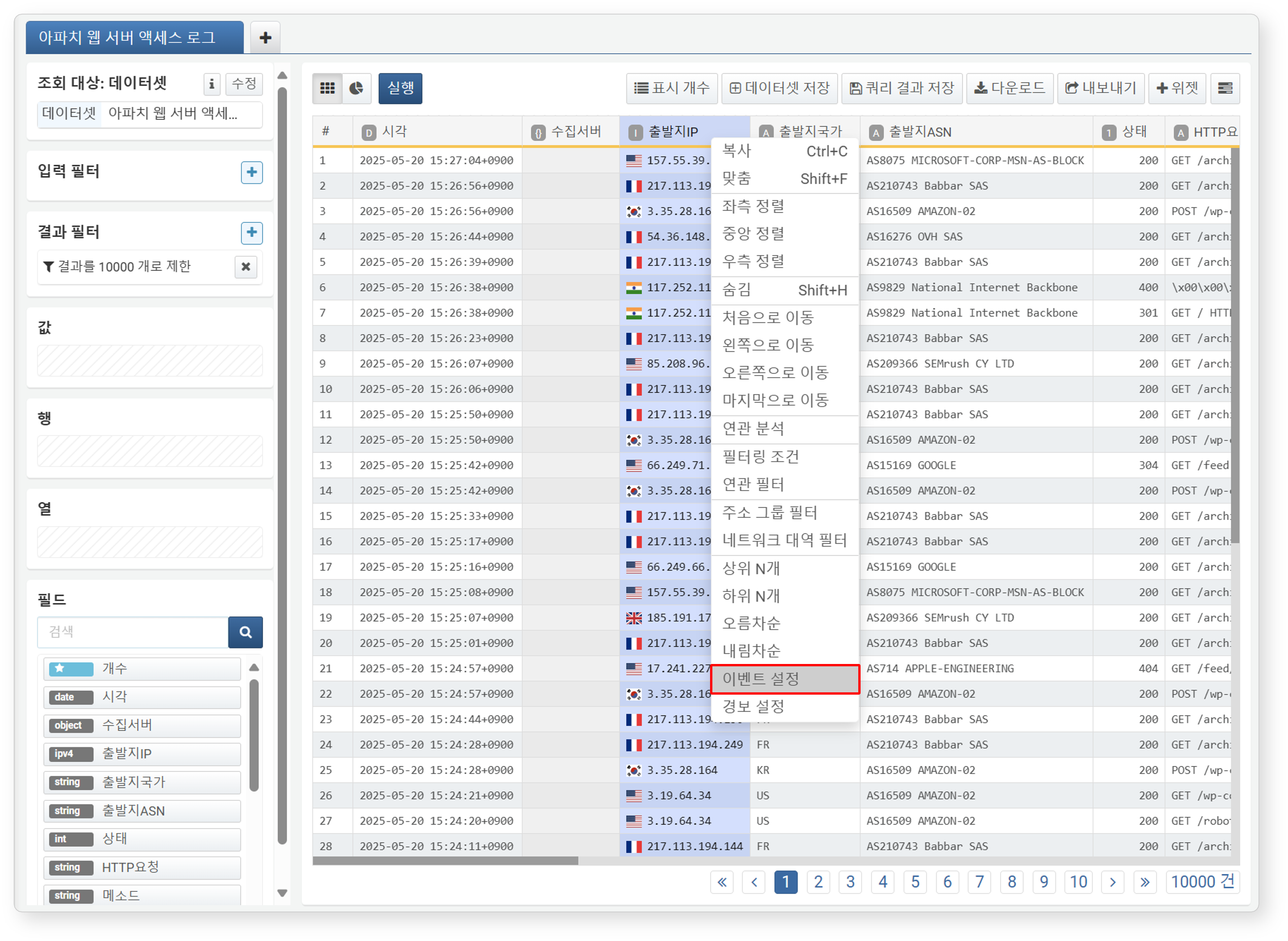
-
특정 필드 값이 임계치를 초과하면 셀 색상을 변경하거나 알림음을 울리도록 경보를 설정할 수 있습니다.
-
도구 모음에서 위젯 버튼을 클릭한 후, 위젯 생성 대화상자에서 아래 항목을 입력하고 추가 버튼을 클릭하세욧.
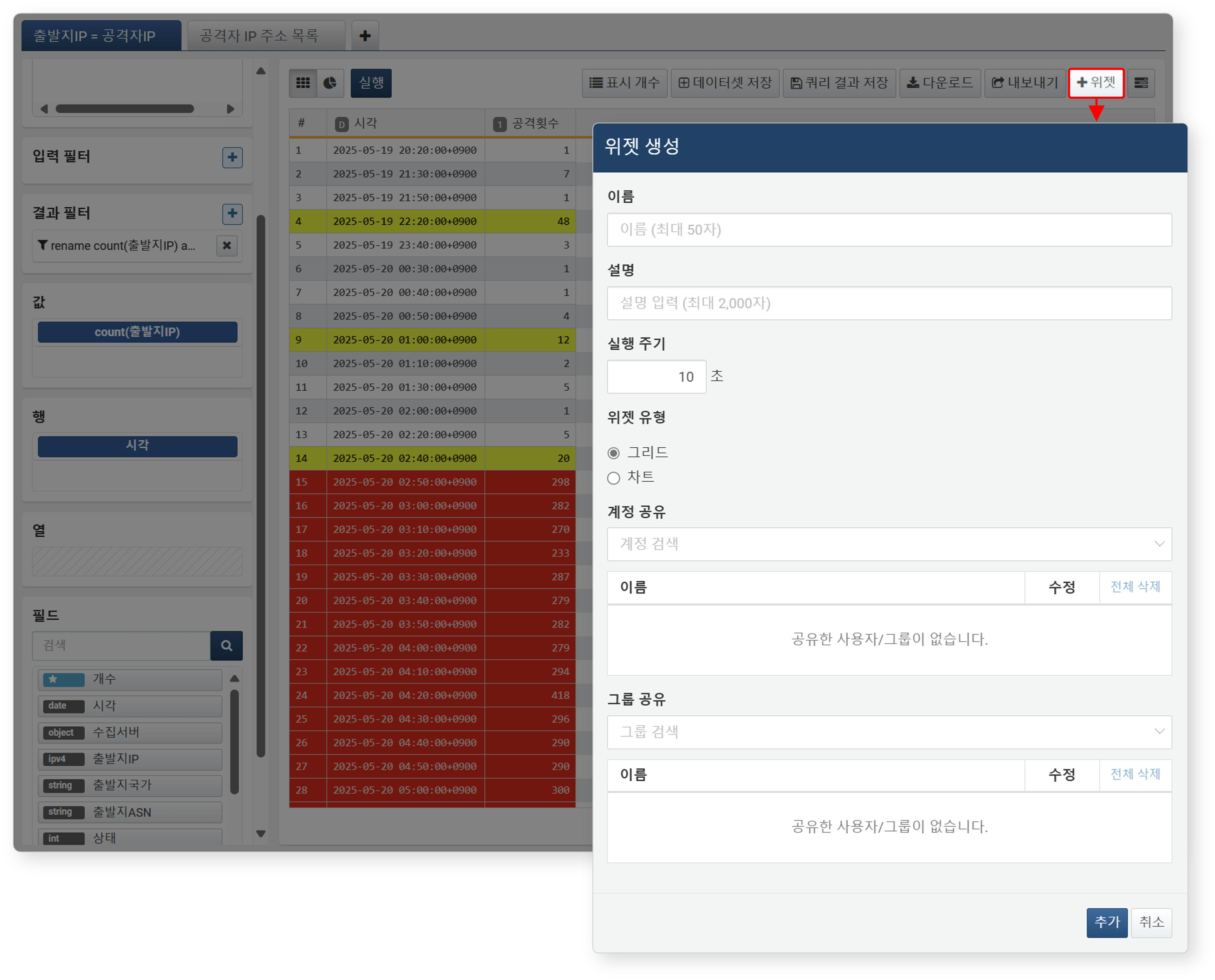
- 이름: 위젯의 고유 이름(최대 50자)을 입력하세요.
- 설명: 위젯에 대한 설명(최대 2,000자)을 입력하세요.
- 실행 주기: 데이터 업데이트 주기(1~2,147,483초)를 설정하세요. 데이터 수집량이 많을 수록 시스템 성능을 고려해 적절한 간격으로 설정하는 것이 중요합니다.
- 위젯 유형: 위젯 유형(기본값: 그리드)을 지정하세요.
- 계정 공유/그룹 공유: 위젯을 공유할 계정 또는 계정 그룹을 지정하세요.
-
추가한 위젯은 대시보드 > 위젯 관리 메뉴에서 확인할 수 있습니다.
차트
차트 위젯은 데이터를 시각적으로 표현하여 시간 흐름, 항목 간 비교, 비율 등을 직관적으로 파악할 수 있도록 도와줍니다.
-
데이터를 불러온 뒤 차트에 적합한 형태로 가공하세요.
- 데이터는 독립 변수(예: 시간, IP 주소, 사용자 ID)와 종속 변수(예: 집계값)로 구성되어야 합니다.
- 피벗 설정 시 집계값이 있는 필드를 값, 분석 기준이 되는 필드를 행 또는 열로 지정하세요.
-
도구 모음에서
 아이콘을 클릭한 뒤, 설정 버튼을 클릭하세요.
아이콘을 클릭한 뒤, 설정 버튼을 클릭하세요.
-
위젯 설정 화면에서 차트의 형식 및 동작을 설정하고, 확인 버튼을 클릭하세요.
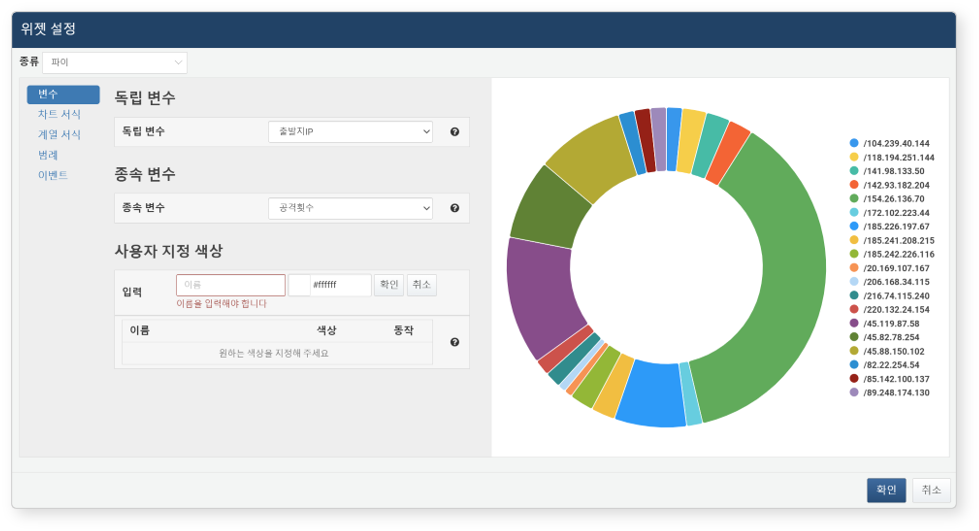
- 종류: 차트 유형을 지정하세요(기본값: 라인).
- 라인: 꺾은 선 시계열 차트
- 스플라인: 부드러운 선 시계열 차트
- 영역: 꺾은 선 아래 영역을 색상으로 채운 차트
- 영역(스플라인): 스플라인 차트에 색상 영역을 추가한 차트
- 가로 막대: 단일 종속 변수 값을 가로 막대로 표현한 차트
- 세로 막대: 단일 종속 변수 값을 세로 막대로 표현한 차트
- 누적 영역: 여러 종속 변수 값을 아래부터 차례로 누적하여 표현한 영역 차트
- 누적 영역(스플라인): 누적 영역 차트를 곡선 기반으로 표현한 형태
- 산포도: 데이터 점을 좌표로 표현하여 두 변수 간의 관계를 시각화한 차트
- 파이: 원형 또는 도넛 형태로 전체 중에서 각 항목이 차지하는 비율을 표현한 차트
- 누적 가로 막대: 여러 종속 변수를 가로 막대로 누적하여 표현한 막대 차트
- 누적 세로 막대: 여러 종속 변수를 새로 막대로 누적하여 표현한 막대 차트
- 트리맵: 면적과 색상으로 항목의 값 크기와 분포를 표현하는 계층적 차트
- 경고 상자: 특정 필드 값이 임계값을 초과하면 색상을 변경하여 경고를 표시하는 메시지 박스
- 세계 지도(마커): 위도, 경도 값을 갖는 데이터를 세계 지도 상에 마커로 표현한 차트
- 세계 지도(버블): 위도, 경도 값을 갖는 데이터를 세계 지도 상에 버블로 표현한 차트
- 이벤트: 사용자가 차트를 클릭하거나 드래그할 때 실행할 동작을 설정하세요. 자세한 내용은 이벤트 설정을 참고하세요.
- 종류: 차트 유형을 지정하세요(기본값: 라인).
-
도구 모음에서 위젯 버튼을 클릭하고 위젯 생성 대화상자에서 다음 항목을 입력한 뒤 추가 버튼을 클릭하세요.
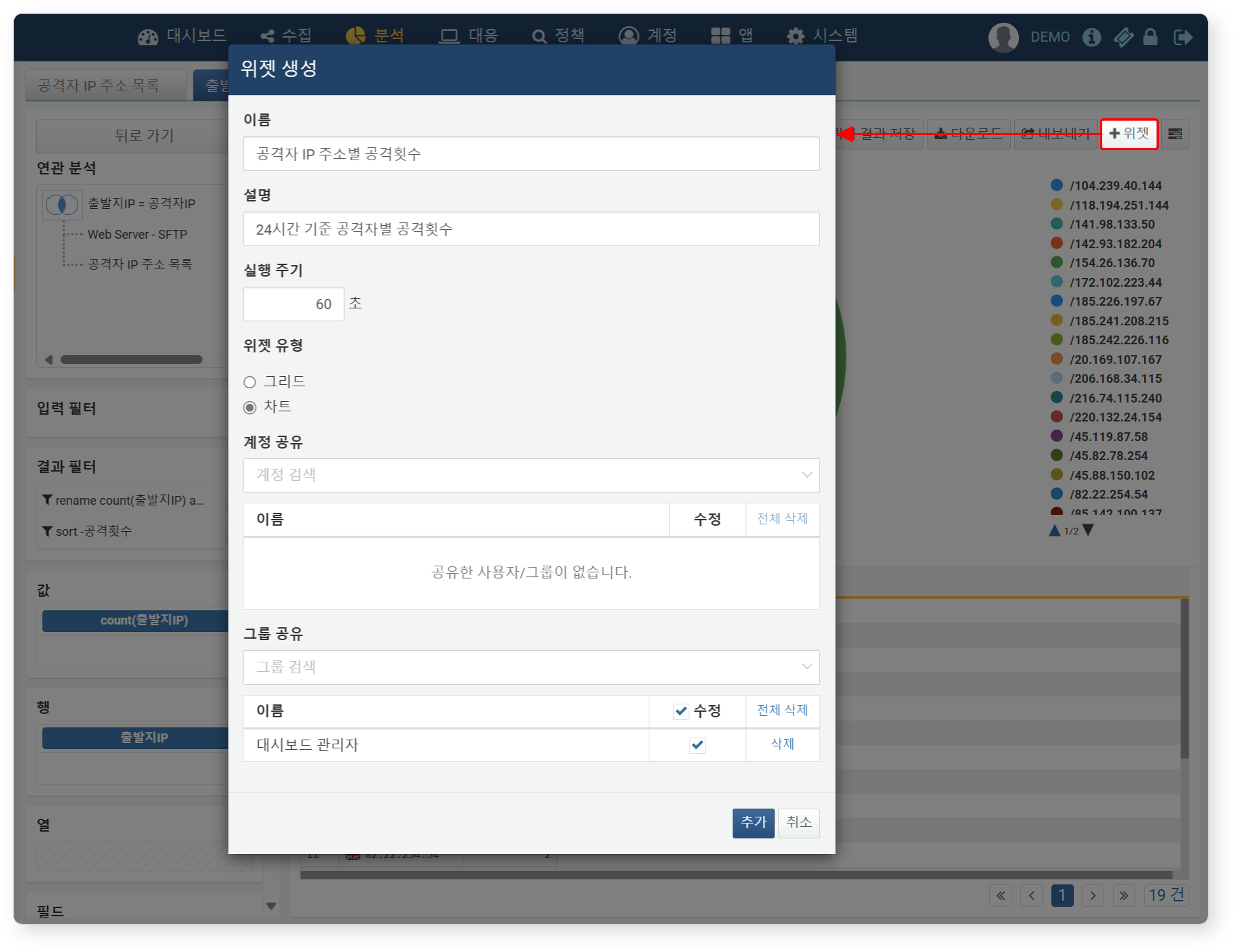
- 이름: 위젯의 고유 이름(최대 50자)을 입력하세요.
- 설명: 위젯에 대한 설명(최대 2,000자)을 입력하세요.
- 실행 주기: 위젯 갱신 간격(1~2,147,483초)을 설정하세요. 데이터 수집량이 많을 수록 시스템 성능을 고려해 적절한 간격으로 설정하는 것이 중요합니다.
- 위젯 유형: 위젯 유형(기본값: 차트)을 지정하세요.
- 계정 공유/그룹 공유: 위젯을 공유할 계정 또는 계정 그룹을 지정하세요.
-
추가된 위젯은 대시보드 > 위젯 관리 메뉴에서 확인할 수 있습니다.
이벤트 설정
그리드 위젯에서 셀을 클릭하거나 차트 위젯에서 시각 요소를 클릭 혹은 드래그했을 때 실행할 동작을 지정할 수 있습니다.
그리드 위젯과 차트 위젯 모두 동일한 방식으로 이벤트를 설정할 수 있습니다.
- 필터 적용
- 대시보드 전역 또는 데이터셋에 필터를 적용합니다. 필터는 여러 개 설정할 수 있습니다.
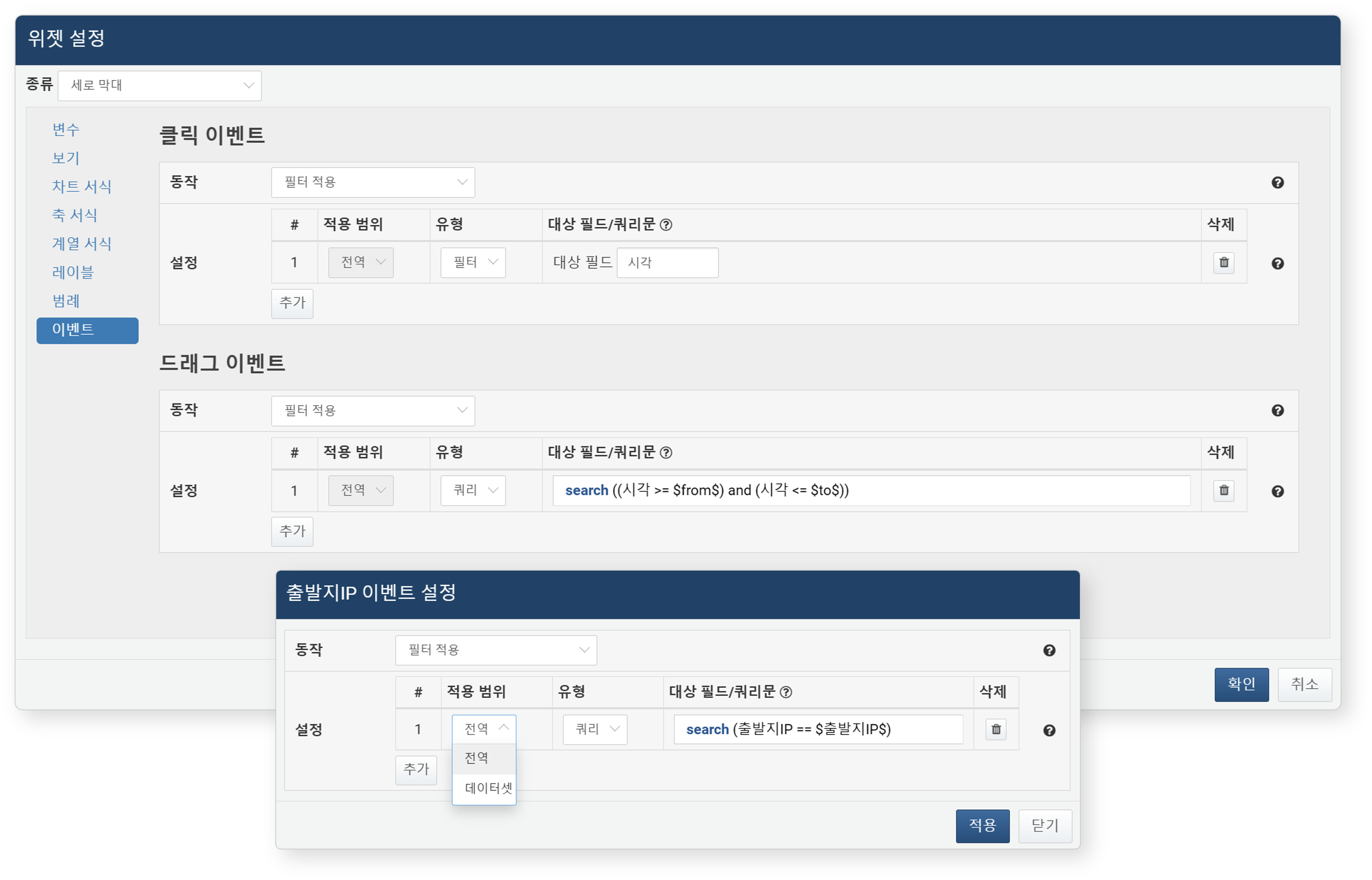
- 적용 범위: 필터를 적용할 위치를 선택하세요.
- 전역: 대시보드 전체에 적용 (위젯에서 지원되는 유일한 옵셥)
- 데이터셋: 조회 대상 데이터셋에 적용
- 유형(기본값: 필터)
- 필터: 지정한 필드의 값과 일치하는 항목만 조회
- 쿼리: 사용자 정의 쿼리문을 이용해 필터링
- 대상 필드/쿼리문: 필터에 사용할 필드 이름 또는 쿼리문을 입력하세요.
- 삭제: 필터를 삭제하려면
 아이콘을 클릭하세요.
아이콘을 클릭하세요.
사용 가능한 매크로
| 매크로 | 설명 | 위젯 구분 | 이벤트 |
|---|---|---|---|
$필드이름$ | 필드 값 | 그리드, 차트 | 클릭 |
$x$ | 독립 변수 값 | 차트 | 클릭 |
$xfield$ | 독립 변수 필드 이름 | 차트 | 클릭, 드래그 |
$from$ | 기간의 처음 값 | 차트 | 드래그 |
$to$ | 기간의 마지막 값 | 차트 | 드래그 |
- 쿼리 실행
- 새 쿼리 창을 열고, 지정한 쿼리를 실행합니다.
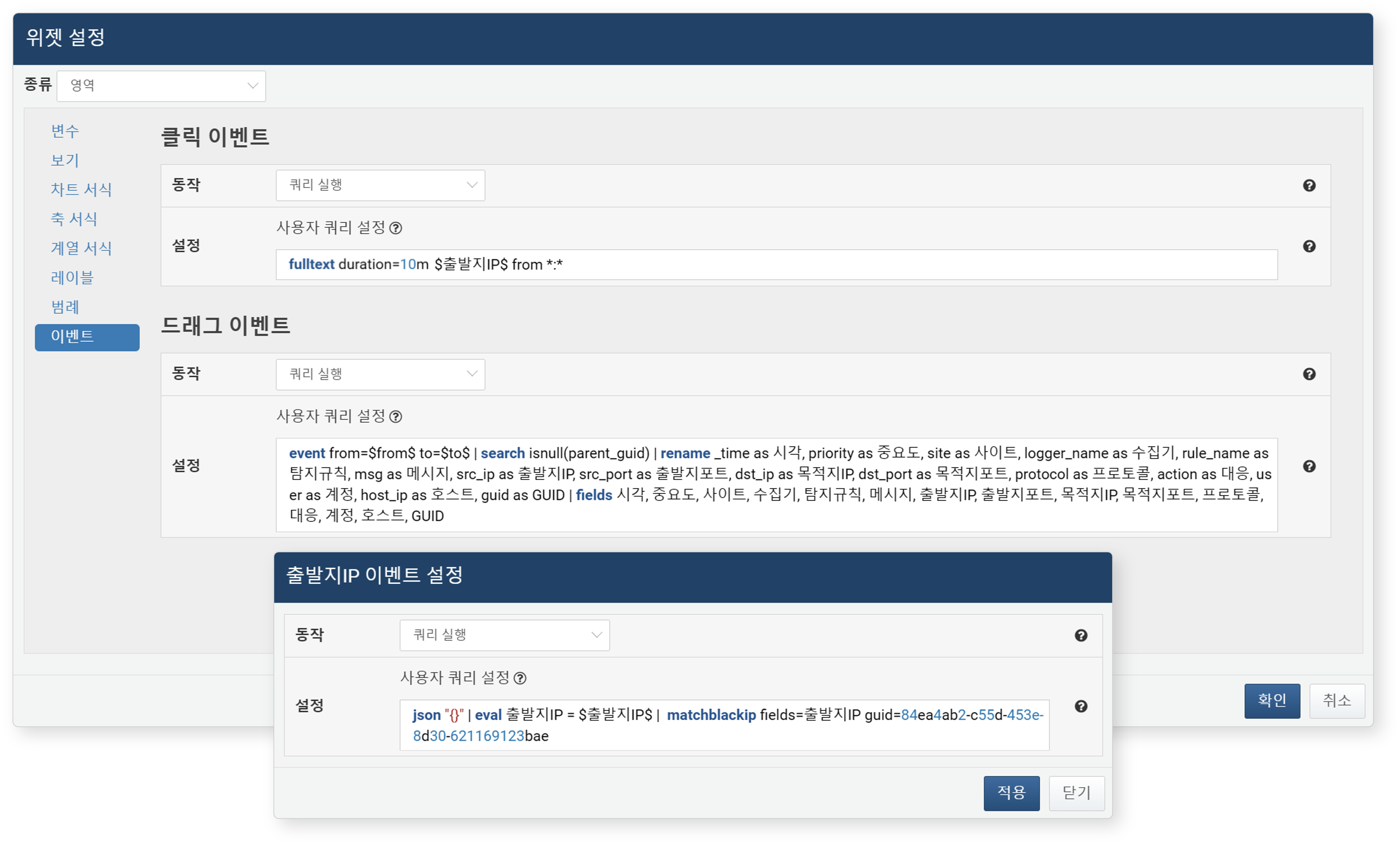
쿼리는 반드시 데이터 조회 명령어(fulltext, event, json 등)로 시작해야 합니다.
사용 가능한 매크로
| 매크로 | 설명 | 위젯 구분 | 이벤트 |
|---|---|---|---|
$필드이름$ | 필드 값 | 그리드, 차트 | 클릭 |
$series$ | 종속 변수 필드 이름 | 그리드, 차트 | 클릭 |
$xfield$ | 독립 변수 필드 이름 | 차트 | 클릭, 드래그 |
$from$ | 기간의 처음 값 | 차트 | 드래그 |
$to$ | 기간의 마지막 값 | 차트 | 드래그 |
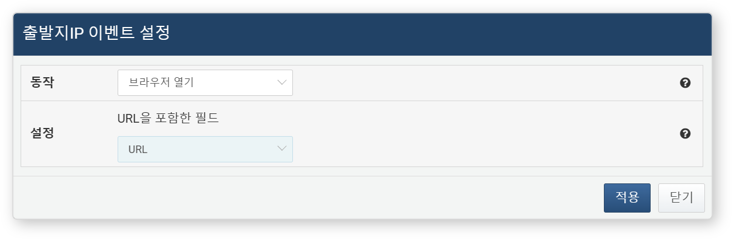
- 브라우저 열기
- 지정한 필드의 URL을 웹 브라우저 새 창에서 엽니다. 단, 드래그 이벤트는 지원하지 않습니다.
- 화면 전환
- 현재 접속 중인 웹 콘솔 내에서 지정한 URL로 화면을 전환합니다. 단, 드래그 이벤트는 지원하지 않습니다.
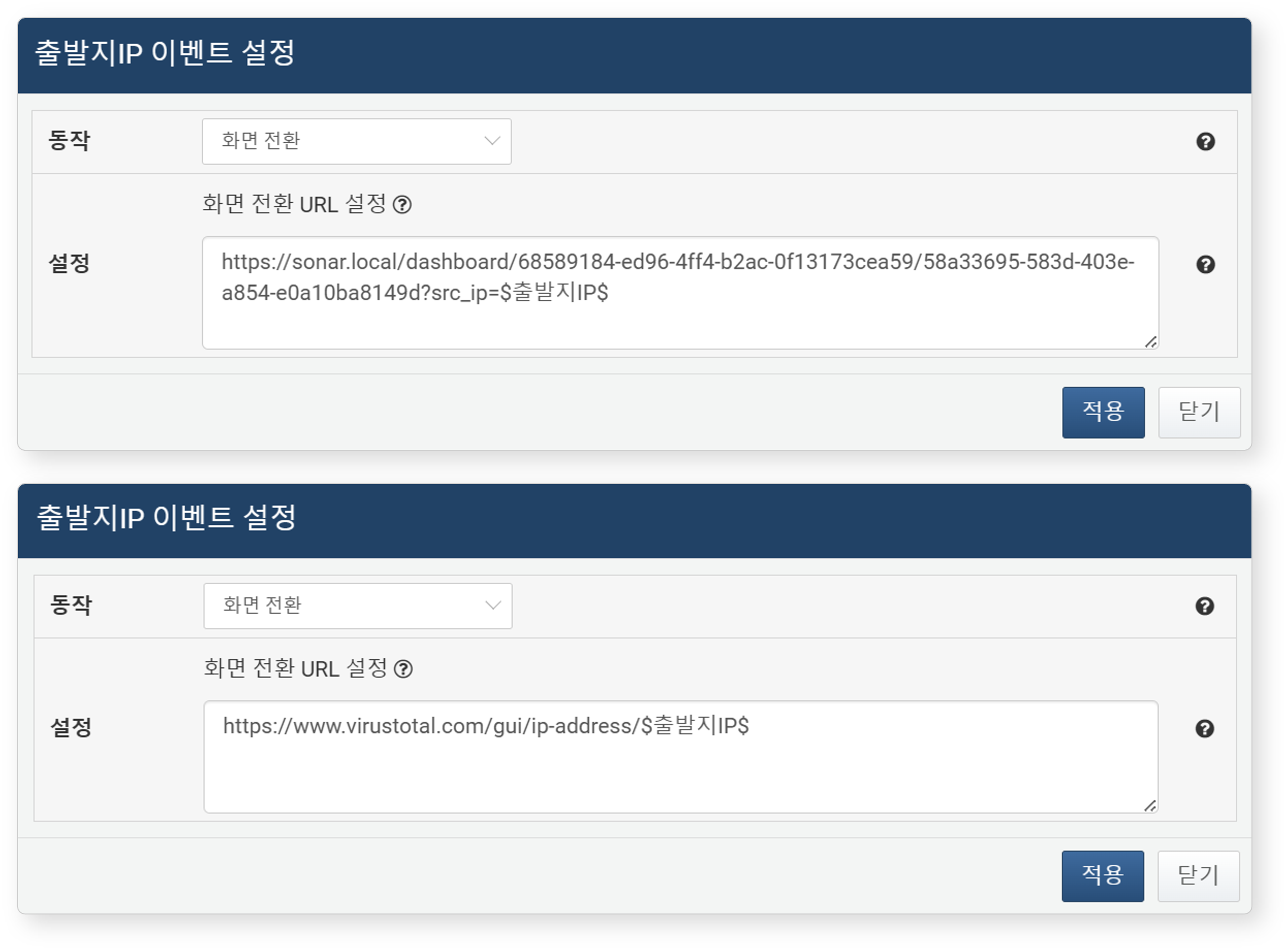
사용 가능한 매크로
| 매크로 | 설명 | 위젯 구분 | 이벤트 |
|---|---|---|---|
$필드이름$ | 필드 값 | 그리드, 차트 | 클릭 |
$series$ | 종속 변수 필드 이름 | 그리드, 차트 | 클릭 |
경보 설정
그리드 위젯에서 특정 필드의 값이 설정한 임계치를 초과할 경우, 브라우저 우측 하단에 알림 메시지를 띄우고 알림음을 재생할 수 있습니다. 실시간 대시보드 모니터링 시 유용하게 활용할 수 있는 기능입니다.
경고를 설정하려면, 그리드 편집 화면에서 필드 이름을 보조 클릭(오른쪽 버튼)한 뒤 팝업 메뉴에서 경보 설정을 클릭하세요.
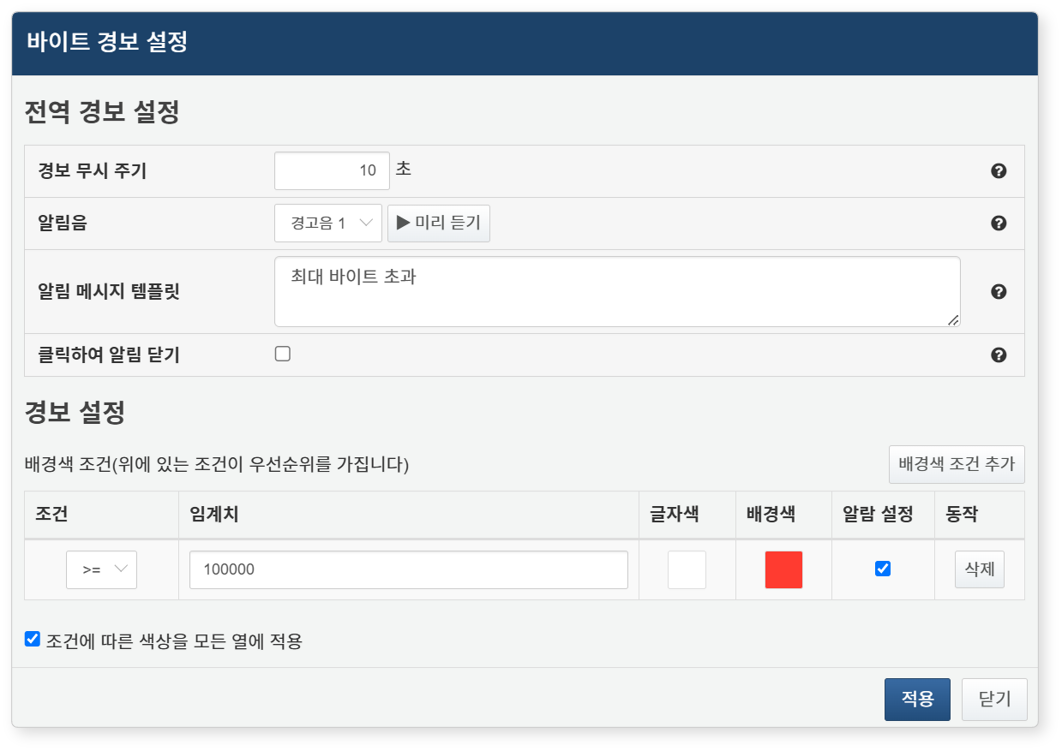
-
경보 무시 주기: 경보 발생 후 동일 조건의 경보를 다시 발생시키지 않을 시간(초)을 설정하세요(1~2,147,483초, 기본값: 10초).
-
알림음: 경보 발생 시 재생할 알림음을 선택하세요.
-
알림 메시지 템플릿: 경보 발생 시 표시할 메시지를 작성하세요(최대 5,000자). 아래 매크로를 사용할 수 있습니다:
매크로 설명 $필드이름$그리드에 표시된 필드 값 $rulefield$경보 조건이 설정된 필드 이름 $rulevalue$경보 조건이 설정된 필드 값 $ruleoperators$조건 연산자( ==,!=,>,>=,<,<=)$ruleoperands$경보 조건 비교 대상인 임계치 -
클릭하여 알림 닫기: 브라우저 알림 메시지를 사용자가 클릭하여 직접 닫을 수 있습니다(기본값: 사용 안 함).
-
배경색 조건: 알림을 발생시킬 조건을 설정하세요. 조건은 등록 순서에 따라 우선 적용됩니다.
- 조건: 비교 연산자를 선택하세요.
- 임계치: 비교 기준값을 입력하세요.
- 글자색: 조건 충족 시 텍스트에 적용할 색상을 지정하세요.
- 배경색: 조건 충족 시 셀 배경에 적용할 색상을 지정하세요.
- 알람설정: 조건 충족 시 알림음을 재생하거나 알림 메시지를 표시하도록 설정하세요.
- 동작: 조건을 삭제하려면 삭제 버튼을 클릭하세요.
-
조건에 따른 색상을 모든 열에 적용: 설정한 색상 조건을 선택한 필드뿐만 아니라 전체 열에 적용하려면 이 옵션을 활성화하세요.
- 운영체제에서 알림을 지원하는 경우 (예: Windows 11): 데스크톱 알림으로 표시됩니다.
- 운영체제는 지원하지 않지만 브라우저가 지원하는 경우 (예: Windows 7 + Chrome): 브라우저 알림으로 표시됩니다.
- 둘 다 지원하지 않는 경우: 로그프레소 기본 알림 메시지로 표시됩니다.
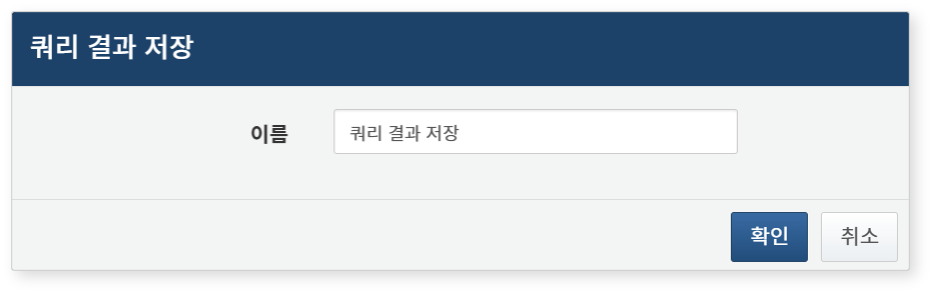
쿼리 결과 저장
피벗 분석 결과를 쿼리 결과로 저장하려면,
- 분석 검색 결과 화면의 도구 모음에서 쿼리 결과 저장 버튼을 클릭하세요.
- 쿼리 결과 저장 대화상자에서 저장할 이름을 입력한 후 확인 버튼을 클릭하세요.
저장된 쿼리 결과는 서버에 저장되며, 분석 > 쿼리 > 쿼리 결과 불러오기에서 확인할 수 있습니다. 저장된 쿼리 결과를 다시 조회하는 방법은 쿼리 결과 불러오기를 참고하세요.
피벗 결과 다운로드
분석 결과를 로컬 PC에 저장하려면,
- 도구 모음에서 다운로드를 클릭하세요.
- 쿼리 결과 다운로드 대화상자에서 아래 항목을 설정한 후 다운로드 버튼을 클릭하세요.
- 파일 이름: 저장할 파일의 이름을 입력하세요(기본값: 쿼리 (쿼리 번호)).
- 컬럼: 다운로드할 필드를 선택하세요. 전체 선택을 클릭하면 모든 필드가 포함됩니다.
- 파일 형식: 다운로드할 파일 형식을 선택하세요(기본값: CSV).
- CSV: CSV 파일
- Excel XML: Microsoft Excel에서 열어볼 수 있는 XML 파일
- Microsoft Word: DOCX 파일
- HTML: HTML 파일
- JSON: JSON 파일
- PDF: PDF 파일
- Hancom HWPX: HWPX 파일
- 파일 인코딩: 텍스트 인코딩 형식을 선택하세요(UTF-8, UTF-16 BE, 확장완성형, 기본값: 확장완성형).
- 범위: 파일에 기록할 데이터 개수를 지정하세요. 가장 최근 데이터부터 역시간순으로 지정된 개수만큼만 파일에 기록됩니다.
- 파일 분할 압축: 이 옵션을 선택하면 피벗 분석 결과를 여러 개의 압축 파일로 분할해 저장할 수 있습니다.
- 분할 건수: 파일 하나에 저장할 최대 건수를 입력하세요 (기본값: 100,000 / 최소: 1,000).
- 이 옵션은 4.0.2409.0 버전부터 지원됩니다.
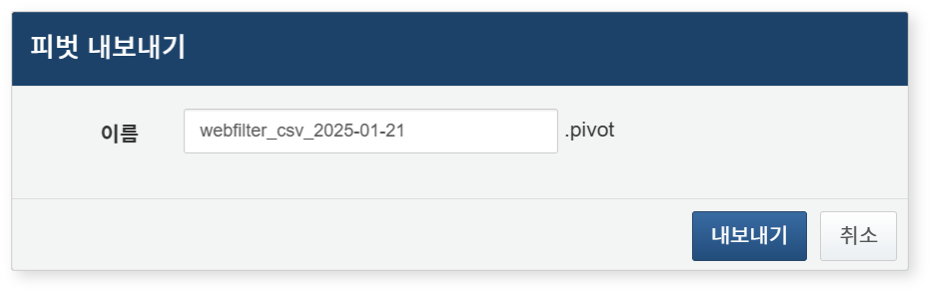
피벗 파일로 내보내기
분석 결과를 피벗 파일로 로컬 PC에 저장하려면,
- 도구 모음에서 내보내기를 클릭하세요.
- 피벗 내보내기 대화상자에서 파일 이름을 입력하고 내보내기 버튼을 클릭하세요.
- 파일 이름에는 문자, 숫자, 특수문자 '_' 만 사용할 수 있습니다.
내보낸 피벗 파일은 불러오기 기능 통해 다시 조회할 수 있습니다.
분석 데이터 표시 개수 변경
분석 결과는 기본적으로 50건 단위로 페이지가 나뉘어 표시됩니다. 한 페이지에 표시할 데이터 개수를 변경하려면, 분석 결과 화면의 도구 모음에서 표시 개수를 클릭하고 원하는 개수를 선택하세요.
분석 쿼리 수행 정보 조회
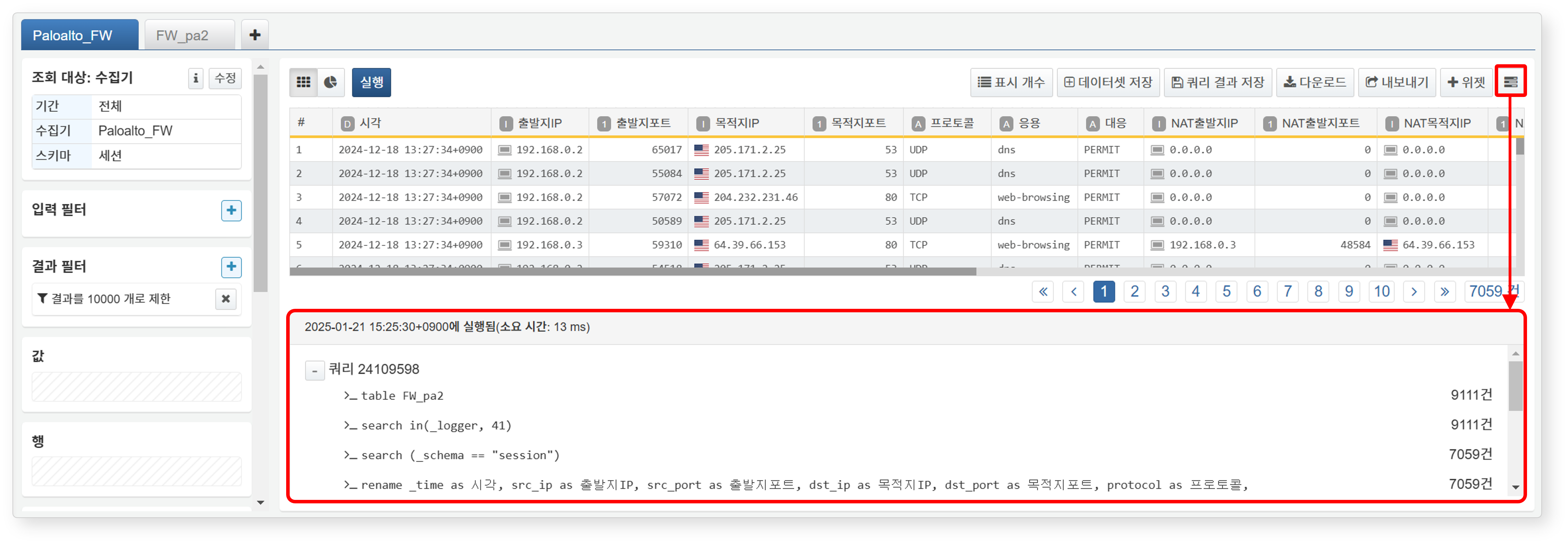
도구 모음에서  아이콘을 클릭하면 화면 하단에 현재 피벗 조건에 따라 실행된 쿼리문과 실행 시각, 처리 시간, 단계별 레코드 수가 표시됩니다.
아이콘을 클릭하면 화면 하단에 현재 피벗 조건에 따라 실행된 쿼리문과 실행 시각, 처리 시간, 단계별 레코드 수가 표시됩니다.
피벗 불러오기
이전에 내보낸 피벗 쿼리 설정 파일을 불러와 동일한 분석 조건으로 피벗을 실행할 수 있습니다.
-
분석 > 피벗 화면에서 가운데에 있는 불러오기 버튼을 클릭하세요.
-
피벗 불러오기 대화상자에서 파일 선택을 클릭한 후,
.pivot확장자의 피벗 파일을 선택하고 불러오기 버튼을 클릭하세요.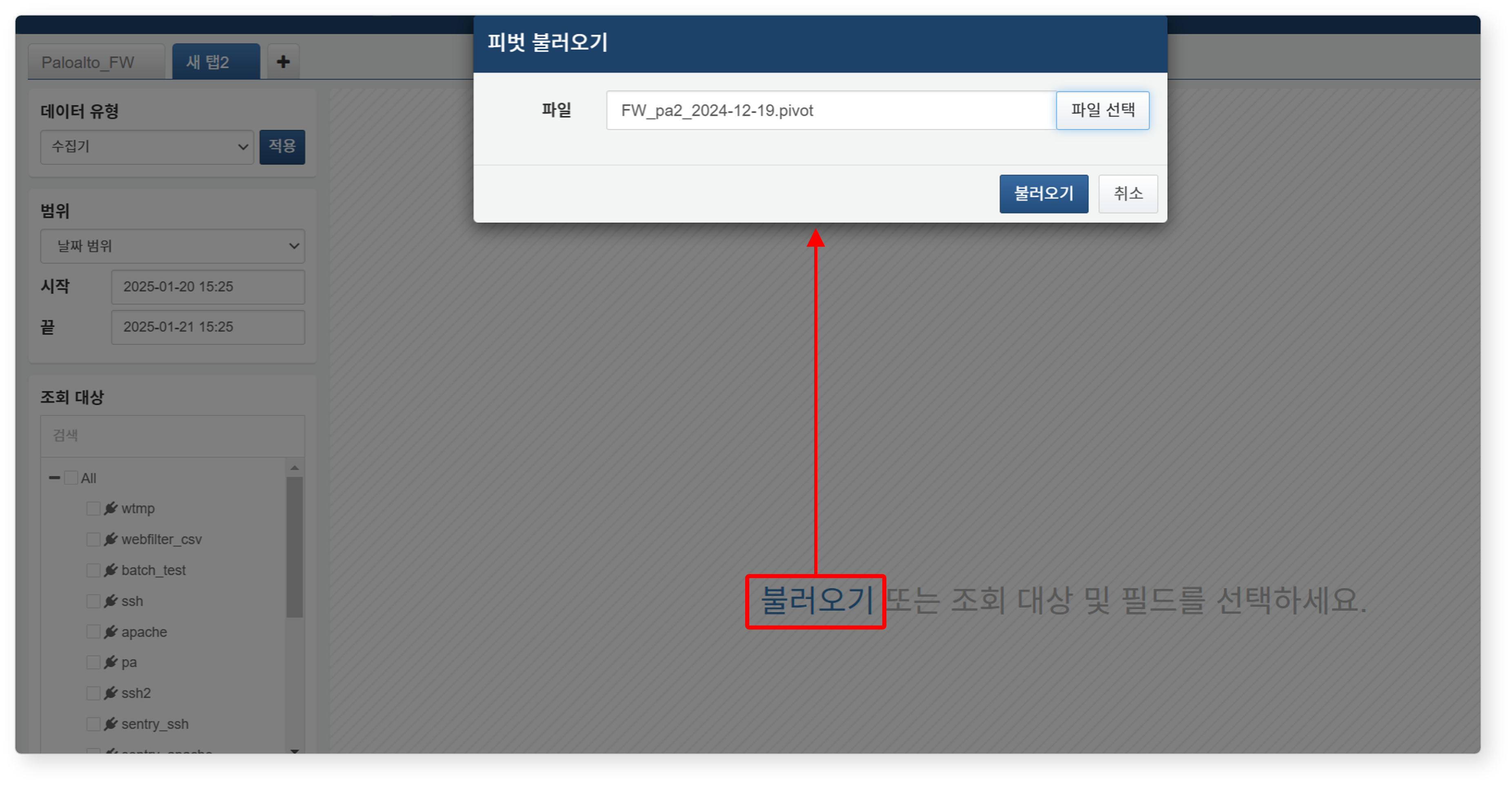
-
피벗을 불러온 시간을 기준으로 쿼리가 실행되어 데이터가 조회됩니다. 예를 들어, 데이터 범위가 '최근 1일'로 설정된 경우, 불러온 시점을 기준으로 최근 1일치 데이터가 자동으로 조회됩니다.
피벗 파일 불러오기 중 오류가 발생할 수 있는 상황은 다음과 같습니다:
- 내보내기 당시 존재했던 수집기, 테이블, 데이터셋, 행위 프로파일 등이 현재 시스템에 존재하지 않는 경우
- 내보내기를 실행했던 당시의 테이블과 동일한 이름의 테이블이 존재하지 않는 경우
- 일부 수집기 또는 테이블만 존재할 경우, 존재하는 항목만 불러오기가 수행됩니다.
- 불러온 피벗 파일에 포함된 데이터 소스에 사용자 계정이 접근 권한이 없는 경우
- 파일이 손상되었거나
.pivot확장자가 아닌 경우