ML Models
Overview
ML Models learn log patterns from training datasets and then classify or detect anomalies in incoming data. Security operators manage models in Policies > ML Models and can apply trained models to stream detection, batch detection, and query analysis.
In Sonar 5, you create a model by selecting one of the model types provided by the server. The default configuration includes the supervised learning-based Random Forest and the unsupervised learning-based Isolation Forest. The Type list on the screen may vary depending on server configuration.
Machine learning modeling process
The full steps for creating and using an ML model are as follows.
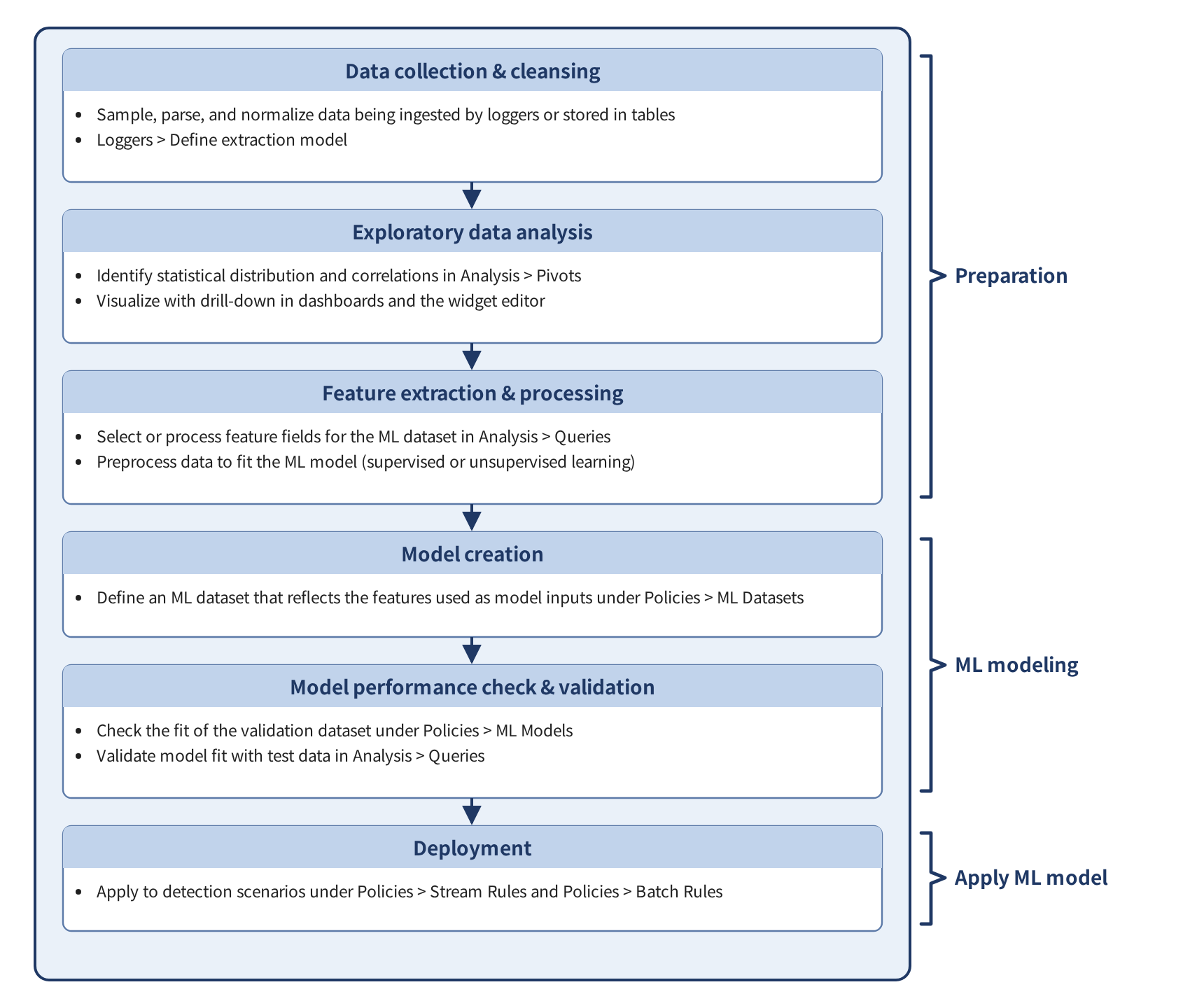
The data collection and preprocessing steps involve fetching data from the data source, then analyzing it in Analysis > Queries and Analysis > Pivots to understand statistical distributions and correlations. ML models work best with numerical data. If field values are strings, you need to convert them to categorized numbers (e.g., 0, 1, 2) or use one-hot encoding to transform them into numerical vectors. For string values that cannot be categorized, consider TF-IDF vectorization. TF stands for term frequency and IDF stands for inverse document frequency.
After these preparation steps, you can build a training dataset from the prepared data and create an ML model from it.
The ML models provided by Logpresso Sonar include both supervised and unsupervised learning.
Supervised learning: Random Forest
The supervised learning model provided by Logpresso Sonar is Random Forest. Random Forest is a type of ensemble learning that uses multiple decision trees to make predictions. Compared to a single decision tree, it is more resistant to overfitting and can reduce the bias and variance of individual models, improving generalization. Random Forest's strong predictive performance makes it well-suited for detecting anomalous behavior by analyzing complex, multi-dimensional data such as logs.
Random Forest is primarily used to solve classification and regression problems. The prediction aggregation method is as follows:
- Classification: The most frequently predicted class among all trees is selected as the final prediction.
- Regression: The predictions from all trees are averaged to produce the final prediction.
The Random Forest workflow is as follows.
- Prepare the training dataset
-
The fields in the training dataset are divided into feature fields and a target variable field.
- Feature: An attribute of the data to analyze — the data fields in a log. Collected log data falls into this category. For example, log data collected from a system uses attributes such as IP address, event time, and event type as features.
- Target variable: The data field that represents the category each data point belongs to. Also called a label. This is typically the field whose value the ML model should predict. It can be expressed as a number, boolean, or string depending on the data characteristics. The target variable values in the training dataset serve as guidance for the model, helping it learn to classify log patterns.
-
In supervised learning, the target variable values typically need to be converted to numbers for easier model training. Binary classification based on boolean values such as
1/0ortrue/falseis the most common approach. Other options include multi-class classification expressed as numbers (e.g.,0,1,2) or strings (e.g.,Normal,Warning,Critical), or regression values expressed as floating-point numbers. - Train the model
-
The random forest model is trained using data that includes the target variable field. The trained model gains the ability to predict the value of the target variable field for new incoming data.
- Predict and detect
-
The trained model analyzes new log data arriving in real time and detects abnormal patterns. For example, if an abnormally large number of login attempts from a specific IP address occurs within a short time, the model flags it as abnormal and sends an alert. This detection process enables rapid response.
Unsupervised learning: Isolation Forest
The unsupervised learning model provided by Logpresso Sonar is Isolation Forest. Isolation Forest is a variant of the Random Forest algorithm designed to detect anomalies or abnormal data. It is useful for anomaly detection problems such as fraudulent transactions, network intrusion detection, and credit card fraud detection. Unsupervised learning involves learning the patterns or structure of data without predefined labels.
Isolation Forest training works by averaging the isolation depth (the number of splits needed to isolate an individual data point) across individual trees to compute an anomaly score, then using that score to determine whether data is anomalous. A lower average isolation depth indicates a higher likelihood that the data is an anomaly. The anomaly score is expressed as a value between 0 and 1. The closer the value is to 1, the more likely it is to be an anomaly. Data above a certain threshold is classified as anomalous.
The Isolation Forest workflow is as follows.
- Prepare the training dataset
- Because Isolation Forest is an unsupervised learning method, you do not need to pre-label the data with target variables (normal/abnormal). Instead, training proceeds directly using the raw log data collected from the system.
- Train the model
- Isolation Forest trains by repeatedly and randomly splitting the given data sample to isolate each data point. Abnormal data is typically sparse, so it can often be isolated with fewer splits. By contrast, normal data requires more splits to isolate, so abnormal data is easier to detect with fewer iterations.
- Predict and detect
- The trained Isolation Forest model analyzes new log data and detects abnormal patterns. The model assigns a score to each log based on how quickly it is isolated, and data with a high score is considered abnormal. For example, when analyzing normal network traffic alongside rare traffic patterns at specific times, Isolation Forest identifies situations such as an abnormally large volume of traffic from a specific IP or unauthorized device access as abnormal. When such abnormal patterns are detected, the system immediately sends a notification and enables a response.
Prerequisites
An ML model requires a training dataset. Read the training dataset documentation and prepare your dataset.
Search ML models
You can view or search the list of ML models in Policies > ML Models.
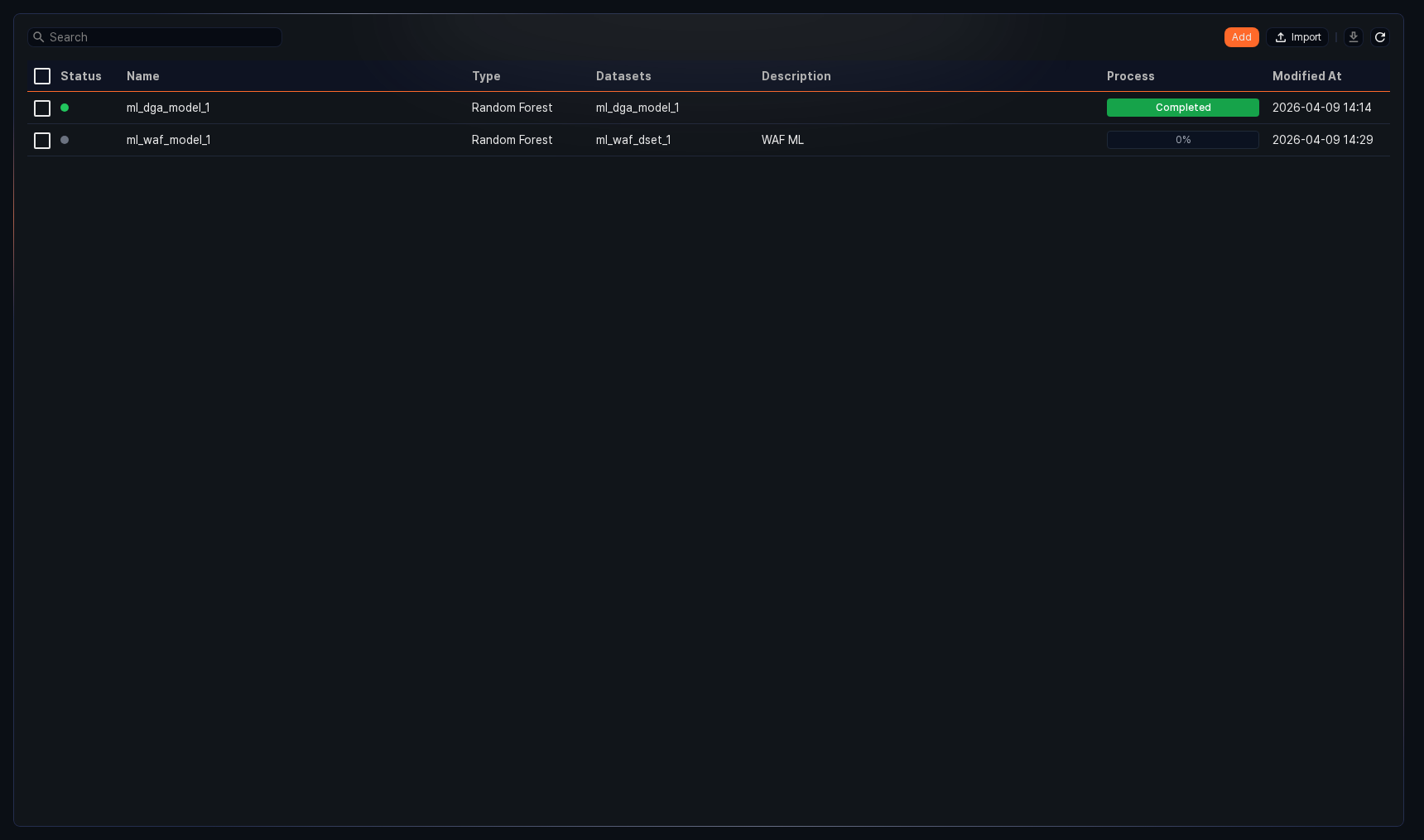
- Status: Indicates whether the ML model is ready to use. A model that has not been trained cannot be used in detection policies (green: available, gray: unavailable).
- Name: The name of the ML model.
- Type: The type of the ML model.
- Dataset: The name of the training dataset used for the ML model.
- Description: Additional information about the ML model.
- Progress (%): The training progress. ML models currently training display their progress as a percentage (%).
- Modified At: The date the ML model was created or last modified.
To find a specific ML model in the list, use the search tool in the toolbar. Enter a keyword to narrow the list.
Download the list
To download the ML model list as a file to your local PC, click ![]() in the toolbar, then select the file format you want.
in the toolbar, then select the file format you want.
Refresh the list
To refresh the ML model list with the latest data, click ![]() in the toolbar.
in the toolbar.
Export/import ML models
You can export a created ML model to a file or import one from a file. This is useful for backing up and restoring ML models.
To export an ML model:
- Select the checkbox of the ML model row you want to export in the list.
- Click Export in the selected items action area.
- In the Export ML Model dialog, set the name and click Confirm.
To import an ML model:
- Click Import in the toolbar.
- In the Import ML Model dialog, click Select File and select the ML model file.
- After selecting the file, click Confirm.
Add an ML model
To add an ML model:
-
In Policies > ML Models, click Add in the toolbar. A training dataset is required for ML modeling.
-
On the Add ML Model screen, enter or select the required values, then click Confirm.
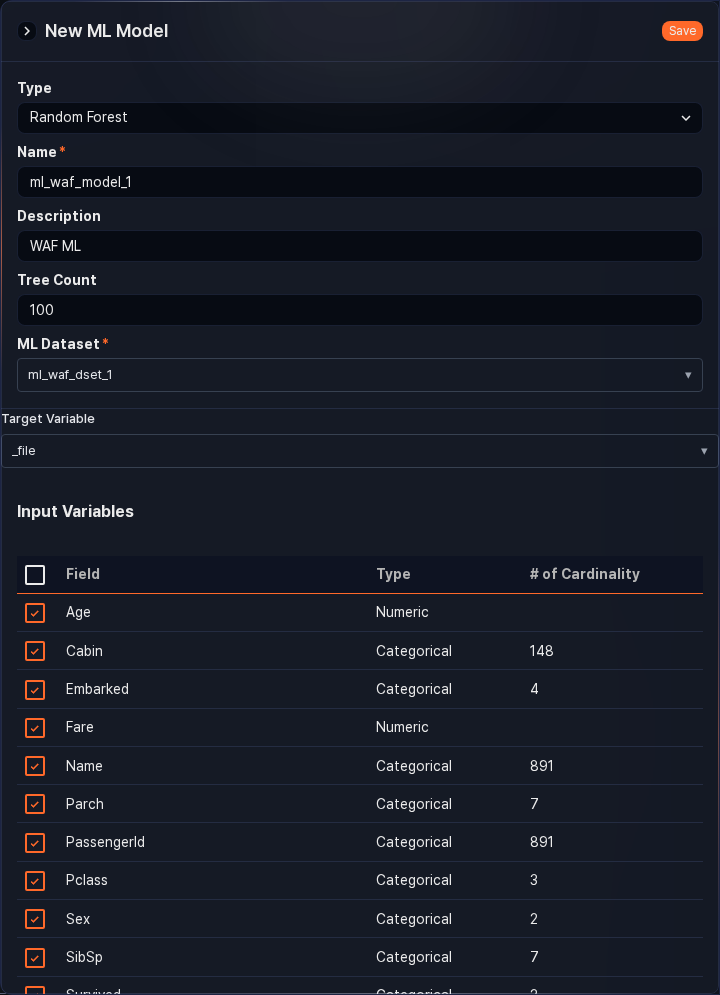
- Type: The type of ML model. Select Random Forest for predictive analysis, or Isolation Forest for anomaly detection.
- Name: A unique name to reference the ML model in queries (up to 50 characters).
- Description: A description of the ML model (up to 2,000 characters).
- Number of Trees: The number of decision trees in the ML model. More trees produce more stable results, but also increase the time required for modeling and inference. Set an appropriate value considering performance and efficiency. (default: 100, range: 1–500)
- Training Dataset: The training dataset to use when creating the ML model.
- Target Variable: When the Type is Random Forest, this is the data field whose value the ML model will predict. For example, when creating an anomaly detection model for file access, you can set the field indicating whether file access is normal or abnormal as the target variable.
- Input Variables: Select the list of fields from the training dataset's full input variables to use for training when creating the model.
View an ML model
After training is complete, click the ML model name to view its performance metrics and model fields.
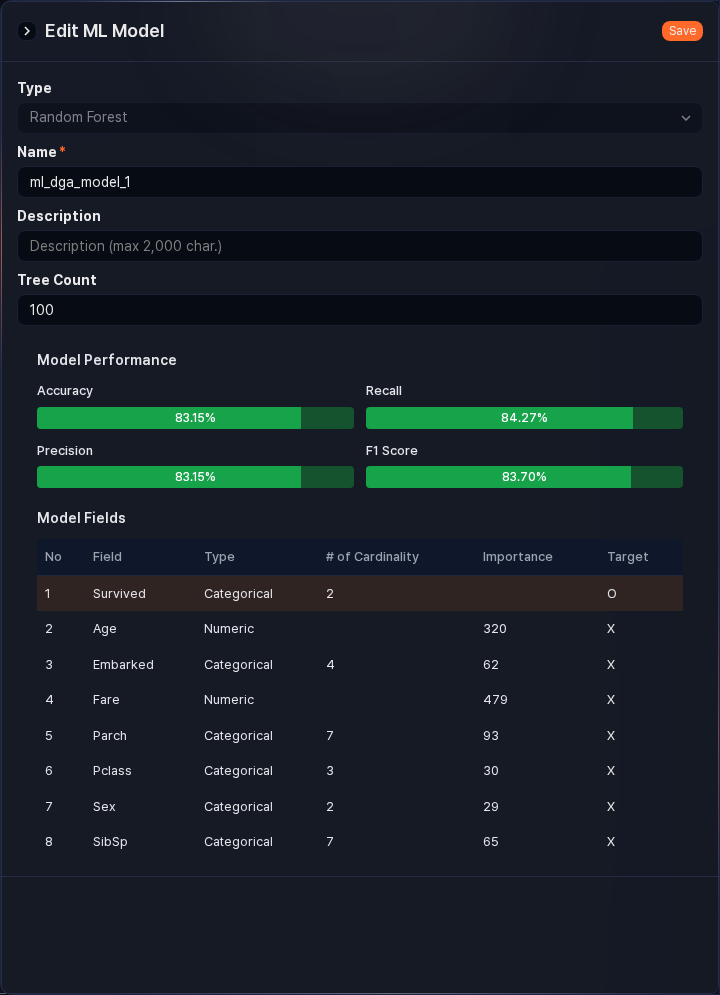
- Performance metrics
- Performance metrics are shown only for Random Forest models.
- Accuracy: The proportion of samples the model correctly predicted. Be careful when using imbalanced data, as accuracy can be misleading.
- Recall: The proportion of actual positive samples that the model predicted as positive. This is an important metric when you want to reduce false negatives.
- Precision: The proportion of samples predicted as positive that are actually positive. This is an important metric when you want to reduce false positives.
- F1 Score: The harmonic mean of precision and recall. The score is higher when precision and recall are similar; if either is high or low, the F1 score also decreases.
- Model fields
- Shows the feature fields, target variable field, and related information that the ML model learned.
Edit an ML model
To edit an ML model:
- Click the name of the ML model you want to edit in the list.
- On the Edit ML Model screen, update the information and click Confirm. Only the Name and Description can be edited. Other attributes cannot be changed.
Use ML models
You can use added ML models in Logpresso queries with the rforest and anomalies commands. Use the rforest command to apply a Random Forest model to input fields, and the anomalies command to apply an Isolation Forest model.
To apply an ML model with the rforest or anomalies command, all input fields must match the ML model fields. Before entering the ML command, process the data so that the input fields match. Queries created this way can also be used in stream detection or batch detection rules.
Delete ML models
To delete ML models:
- Select the checkboxes of the ML model rows you want to delete in the list.
- Click Delete in the toolbar.
- In the Delete ML Model dialog, review the list of ML models to delete, then click Delete. Click Cancel to abort.